随着移动互联网的发展,人们的衣食住行等日常生活越来越依赖网络。以往人们连接互联网只是为了简单快捷的获取信息。现如今,人们利用互联网可以实现即时通讯,购物,交易。而移动支付越来越发达,意味着我们不仅是基本的个人信息,甚至是银行相关信息都越来越多地被获取并保存在互联网上。移动互联网在给我们的生活带来便捷的同时,也存在着诸多隐私数据安全的问题。如互联网社交巨头Facebook的隐私门事件,逾5000万用户的信息被泄露。
为了在采集、存储及发布数据等环节,保护用户的隐私信息不被泄漏,研究人员引入了多种隐私的保护方法,包括k-匿名,l-多样性,差分隐私技术等。差分隐私技术是最近研究比较多的一种保护方法,其思想是在数据的采集或发布前,对数据进行扰动(Perturbation)添加噪声,从而可以隐藏真实数据,避免具有背景知识的攻击者通过猜测,获取隐私信息。差分隐私保护技术给出了数据隐私保护程度及数据可用性之间的严格数学定义模型:
算法A是满足ε的差分隐私算法(ε-DP),其中ε ≧0,当且仅当对于任意两个只相差一个元素的数据集D,D’,都满足如下公式:
其中Pr是指算法得到特定结果的概率,对于任意t∈T,T是算法A的值域。
以上数学模型的直观意义是,如果算法对于任意两个不同的数据集计算得到同一个结果的概率非常接近,即任意两个不同的输入,算法都大概率得到两个相同值,那么很难通过算法的结果值,猜测出输入数据集的信息。根据上述公式,当ε接近于0时,表示算法对输入数据的保护性很高;相反,如果算法对于任意两个不同的输入数据集,总能大概率得到两个不同的值,那么很容易通过算法的输出,猜测出输入数据集的信息。这时ε的取值会较大。ε即被称作隐私预算,隐私预算越小,对数据的隐私保护越大,但是数据的可用性越差;隐私预算越大,数据的可用性越好,但是隐私保护能力越差。
差分隐私保护技术是通过对数据进行扰动达到保护隐私的目的,根据上述差分隐私的数学定义公式,算法A被称为带扰动的查询函数。其输入为原始数据,输出即为扰动后的受保护数据。目前最为常用的一种扰动机制是Laplace机制。一般来说,原始数据采集后,会存储在一个可信中心服务中。该服务负责将数据进行差分计算处理,并向外发布加噪后的保护数据。这种原始数据存储于中心服务的差分隐私技术被称为中心化差分隐私(Centralized Differential Privacy)。与之对应的是本地化差分隐私(Local Differential Privacy),该方案是在数据被收集前,由数据拥有者在本地先对数据进行扰动,然后将加噪数据上传到服务中心。
本地化差分隐私的数学定义如下:
算法A是满足ε的本地化差分隐私算法(ε-LDP)),其中ε ≧0,当且仅当对于任意两个数据v,v’,都满足如下公式:
其中v,v’属于A的定义域,y属于A的值域。
由此可见,中心化差分隐私与本地化差分隐私主要的区别在于处理过程的不同。中心化差分隐私对采集后的数据进行扰动,因此需要一个可信的中心服务进行数据的汇总和处理;而本地化差分隐私在数据的源头进行扰动保护,因此允许数据拥有者在本地进行处理,更好地保护了隐私。在本地化差分隐私技术中,由于中心服务采集的都是扰动后的数据,无法直接得到想发布的数据结果,如统计值等。因此,在本地化差分隐私技术中,一般都需要对采集数据进行去扰动的处理,从而得到如和值、平均值等可发布的统计数据。
从用户角度来看,本地化差分隐私能更好地保护用户数据的隐私。用户的数据在被采集前,已经在本地进行扰动处理,原始数据的隐私已被抹去。因此本地化差分隐私技术不需要假设有可信的中心服务的存在,也就不需要担心隐私可能会被中心服务泄漏。
目前已有多个研究机构及企业提出了不同的本地化差分隐私技术的实现方案,如苹果、谷歌、三星等,其中以苹果的方案较为有代表性。苹果在其iPhone、Mac等设备上进行系统和应用信息采集的时候,均应用了本地化差分隐私技术来对用户敏感信息进行脱敏。其中一个典型应用,是对用户手机键盘上输入的单词及emoji表情,进行统计分析以得到流行的emoji表情、单词或新的网络用语,用于改善产品体验。下面将具体介绍该方案的原理。
差分隐私保护过程可以分成扰动,预处理,汇聚3个阶段。扰动阶段是在用户手机端进行的。用户每输入一个表情或单词,其输入信息即会被记录、扰动并存储在本地,等待上传。预处理及汇聚阶段都是在服务器端进行。在预处理阶段,服务器会对从不同用户,不同设备收集到的扰动数据进行去除元数据、时间戳,重新排序等操作。最后的汇聚阶段将利用预处理阶段得到的数据,按照每个表情或单词,利用无偏估计的原理进行统计计算。
苹果的本地化差分隐私保护技术[1](以下称为LDP-CMS)是基于频度统计算法(CMS,Count-Min Sketch)设计的。CMS是一种大数据领域中的轻量级统计数据结构,其主要目的是利用尽可能小的内存开销来统计已知定义域的海量数据集中,每条数据的出现频度(frequency)。CMS的基本思路是使用一个哈希函数集,将输入数据映射到一个矩阵中并累计每一个输入数据的值。统计对象再根据相同的哈希函数集取出其最小的累计值,即为其冲突最少的频度预估值。根据上面对LDP-CMS的整体过程描述可知,LDP-CMS的隐私保护过程包括三个数据处理阶段,详细介绍如下。
扰动过程在用户端进行。用户输入的表情用d表示,而D是所有表情的集合,有d∈D。哈希函数集H中包含k个不同的哈希函数,任意一个函数hj∈H将输入d映射到整数范围m,有hj : D->[m]。ε是隐私预算,扰动阶段的算法过程如下:
AlgorithmAclient-CMS:
1. 在k范围内随机地选取数值j,作为选择第j个哈希函数的索引;
2. 初始化一个长度为m的向量u,将向量的所有元素置为-1;
3. 将向量中的元素uhj(d)置为1;
4. 对于向量u中每一个元素的符号位,以概率1/(eε/2+1)进行翻转,即把-1变成1或把1变成-1,得到向量ũ;
5. 返回向量ũ及索引j。
可以证明,算法Aclient-CMS满足ε-LDP:
用户在手机端输入的每一个表情d都会使用Aclient-CMS算法进行扰动处理,得到加噪数据(ũ,j)。然后系统会进行随机抽样,将部分扰动数据上传到服务器。接着数据处理进入预处理阶段,其算法过程如下:
AlgorithmAserver-CMS:
1. 算法的输入为数据集D={(ũ1,j1),…, (ũn,jn)};
2. 定义cε=(eε/2+1)/ (eε/2-1);
3. 对数据集D中的每个数据ũi,计算õi=k∙(cε/2∙ũi+1/2∙1)
4. 初始化一个大小为k×m的矩阵M,将矩阵的所有元素设置为0;
5. 对每个õi,以其对应的ji作为矩阵M的第ji行,把向量õi的每个元素与矩阵M的第ji行的每个元素相加,有Mji,l= Mji,l+õil,其中i∈[n],l∈[m];
6. 返回计算得到的概要矩阵M。
汇聚阶段,服务器对表情集合中的每个表情d,通过概要矩阵M预估其出现的频度。算法过程如下:
AlgorithmAserver:
1. 对表情集合D中的每个表情d,依次使用哈希函数集H中的每个函数h,获取d在矩阵M中不同行的对应的元素,并根据以下公式得到预估频度f’(d):
可以证明,对每个输入表情d的实际频度f(d)=E(f’(d))。
LDP-CMS技术应用的主要目的,是在保护用户隐私的前提下,统计用户输入内容的频度、平均值等。在实际应用中,一方面需要较精确的还原采样的表情或单词的实际频度;另一方面,也要保证实际的频度排序与预估的频度排序接近,特别是Top n的排列顺序。为了评价基于LDP技术的隐私保护方案的实际应用效果,我们给出了一种验证算法有效性的评价模型。
评价模型从期望偏差∆E,排序偏差∆R及稳定性D(x)三个方向,评价技术方案的有效性。
期望偏差是指,算法对一个元素的频度进行多次预估得到的预估频度期望值,与该元素实际频度值之间的偏差比。期望偏差越小,表明算法预估越精确,还原能力越强。期望偏差的定义如下:
其中,d为输入的元素,ac(d)是元素的实际频度,ec(d)i为算法对元素第i次的预估频度,n为重复预估的次数。
排序偏差是指,算法多次预估一个元素的频度值的排序,与该元素的实际频度排序的平均偏差。序列是按频度值从大到小排序。排序偏差越小,表明算法越能还原元素的频次排序。排序偏差的定义如下:
其中,ar(d)是元素d的实际频度排序,er(d)i是算法对元素第i次的预估频度排序。
方差即是预估频度与实际频度的方差,方差越小表明算法的预估越稳定。其定义公式如下:
接下来,我们将在具体的应用场景,使用LDP-CMS模拟对用户数据进行采集及发布,并展示有效性评价模型是如何工作的。我们使用的输入数据集是英文单词。数据集取值范围为前2000个最常用的英文单词集W,数据集的大小为n=1000000。输入数据的构造,将会使用几种不同的方法,以尽量保证接近真实的用户使用频度,当然我们也会使用一份真实的数据与构造的数据进行比较。数据构造主要目的是生成单词表W中每个单词的频度,问题即转化为所有单词的频度分布问题。为表述方便,先将单词表中的单词以字典序正序排序,并假设排序越前的单词,其频度越高。以下为生成单词频度分布的几种方法。
1. 调和级数分布(1/x)
单词的频度分布满足如下数列分布:
而已知:
其中C≈0.57722被称作欧拉初始。
假设需要产生的数据集大小为m,单词表的大小为n,那么频度从大到小的分布为:
2. 指数分布(exponent)
单词的频度分布满足如下数列分布:
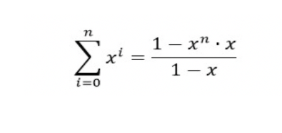
而已知:
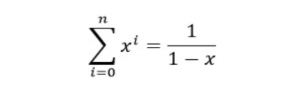
当x<1时,公式可约等于:
同理,数据集大小m,单词表大小n,频度从大到小的分布为:
本文中,x=1.3-1。
3. 平均分布(even)
数据集大小m,单词表大小n,频度从大到小的分布为
除了上述3种不同方法构造的数据集分布外,我们还从某app获得一部分真实的用户输入单词频度的分布数据作为对比。下图以单词频度排序从高到低,展示了不同方式产生的数据的频度分布。从图中可观察到,指数分布及调和级数分布都能较好地接近真实的频度分布,因此后续的验证也是主要采用这两种分布生成的数据集。
使用LDP-CMS进行数据加噪需要确定3个参数,隐私预算ε,哈希函数集大小k,哈希空间m。其中隐私预算一般会由数据发布者根据数据保密程度决定。而另外两个参数k及m的确定则较为复杂,其选择可能会影响加噪效果及运算时间。我们的实验将使用指数分布及调和级数分布,分别生成大小为100万的两个测试数据集,数据集取值范围为2000个英文单词。使用LDP-CMS的客户端算法,对测试集的每个数据加噪,然后再使用服务端算法预估每个单词的频度。为验证不同k及m的取值对结果产生的影响,分别使用k=[256,65535],m=[32,1024]。每个数据集的每种不同参数取值重复上述加噪及预估过程100次。最后取原始数据中频度排序Top 20的单词作为验证的样本数据。
上图是根据前述验证有效性模型给出的公式,从验证数据计算得到的排序偏移,期望及方差在不同参数,不同分布下的对比图表。首先是排序偏移,曲线越接近横坐标,预估的频度排序越准确。从图表中可以观察到,频度排序越高的单词,其预估结果的排序偏差越小,即其预期稳定性越好;k及m的取值越大,预估排序与实际排序越接近。图中的黑线是假设排序偏差标准,设为1。
期望偏差、方差与排序偏差类似,曲线越接近横坐标,表明算法还原每个单词的实际频度越准确,算法的计算稳定性越好。
我们的测试发现,m的取值对计算耗时的影响较明显,取值越大计算耗时越多。综合算法有效性及计算耗时,对于单词集为2000条,数据集为100万的场景,在隐私预算固定,k=65535,m=32的情况下,LDP-CMS能够取得较佳的隐私保护及可用性的效果。
我们首先对差分隐私的定义及分类进行了简单介绍,然后进一步介绍了本地化差分隐私的其中一种实现方案——LDP-CMS。最后提出一种可以验证本地化差分隐私技术有效性的方法。该方法包括一个验证模型,验证模型从3个不同的角度,量化LDP方法的有效性。该有效性验证方法还可以给LDP算法的参数选择提供量化参考。
【参考文献】
[1] Differential Privacy Team, Apple. Learning with privacy at scale. 2017.