欢迎关注WX公众号:【程序员管小亮】
专栏——深度学习入门笔记
声明
1)该文章整理自网上的大牛和机器学习专家无私奉献的资料,具体引用的资料请看参考文献。
2)本文仅供学术交流,非商用。所以每一部分具体的参考资料并没有详细对应。如果某部分不小心侵犯了大家的利益,还望海涵,并联系博主删除。
3)博主才疏学浅,文中如有不当之处,请各位指出,共同进步,谢谢。
4)此属于第一版本,若有错误,还需继续修正与增删。还望大家多多指点。大家都共享一点点,一起为祖国科研的推进添砖加瓦。
深度学习入门笔记(十六):计算机视觉之边缘检测
1、计算机视觉

计算机视觉是一个飞速发展的一个领域,这多亏了深度学习领域的迅猛发展。深度学习与计算机视觉可以帮助汽车,查明周围的行人和汽车,并帮助汽车避开它们,即无人驾驶。还使得人脸识别技术变得更加效率和精准,目前即将体验到的或早已体验过的仅仅通过刷脸就能支付账单或者解锁手机或门锁。当解锁了手机,上面一定有很多分享图片的应用,比如美食(某团),酒店(某程)或商品(某宝和某东),等等。这些公司在这些应用上使用了深度学习技术来展示与你最为相关的或你感兴趣的图片。
深度学习之所以让人兴奋有下面两个原因:
-
第一,计算机视觉的高速发展标志着新型应用产生的可能,这是几年前,人们所不敢想象的。通过学习使用这些工具,也许能够创造出新的产品和应用。
-
第二,即使到头来也未能在计算机视觉上有所建树,但人们对于计算机视觉的研究是如此富有想象力和创造力,由此衍生出新的神经网络结构与算法,这启发人们去创造出计算机视觉与其他领域的交叉成果。

第一个例子,你应该早就听说过图片分类,或者说图片识别,之前也有讲过,比如给出这张64×64的图片,让计算机去分辨出这是不是一只猫。

还有一个例子,在计算机视觉中有个问题叫做目标检测,比如在一个无人驾驶项目中,不一定非得识别出图片中的物体是车辆,但一定需要计算出其他车辆的位置,以确保自己能够避开它们。所以在目标检测项目中,首先需要计算出图中有哪些物体,比如汽车,还有图片中的其他东西,再将它们模拟成一个个盒子,或用一些其他的技术识别出它们在图片中的位置。注意在这个例子中,在一张图片中同时有多个车辆,每辆车相对与你来说都有一个确切的距离。

还有一个更有趣的例子,就是神经网络实现的图片风格迁移,比如说现在有一张图片,但你想将这张图片转换为另外一种风格,这个时候就可以使用图片进行风格迁移。具体操作是有一张满意的图片和一张风格图片(实际上右边这幅画是毕加索的画作),可以利用神经网络将它们融合到一起,描绘出一张新的图片。它的整体轮廓来自于左边,却是右边的风格,最后就生成下面这张图片,这种神奇的算法创造出了新的艺术风格。
但在应用计算机视觉时要面临一个挑战,就是数据的输入可能会非常大。举个例子,在上面的例子中一般操作的都是64×64的小图片,实际上,它的数据量是64×64×3,因为每张图片都有3个颜色通道,如果计算一下的话,可得知数据量为12288,所以特征向量 维度为12288。这其实还好,因为64×64真的是很小的一张图片。
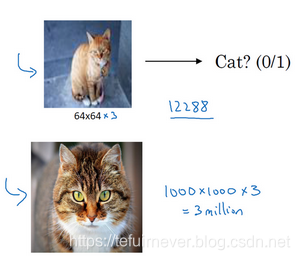
如果要操作更大的图片,比如一张1000×1000的图片,它足有1兆那么大,但是特征向量的维度达到了1000×1000×3,因为有3个 RGB 通道,所以数字将会是300万。如果在尺寸很小的屏幕上观察,可能察觉不出上面的图片只有64×64那么大,而下面一张是1000×1000的大图。
如果要输入300万的数据量,就意味着特征向量 的维度高达300万,所以在第一隐藏层中,也许会有1000个隐藏单元,而所有的权值组成了矩阵 ,如果使用了标准的全连接网络,这个矩阵的大小将会是1000×300万,其中 的维度为 (300万),意味着矩阵 会有30亿个参数,这是个非常巨大的数字。在参数如此大量的情况下,很难获得足够的数据来防止神经网络发生过拟合和竞争需求,此外,要处理包含30亿参数的神经网络,巨大的内存需求让人不太能接受。
对于计算机视觉应用来说,你肯定不想它只处理小图片,为此,需要进行卷积计算,它是卷积神经网络中非常重要的一块。
2、边缘检测示例
卷积运算是卷积神经网络最基本的组成部分,使用边缘检测作为入门样例是非常好的一个选择。
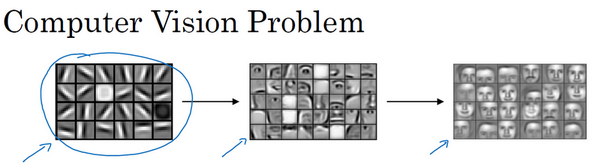
神经网络的前几层是用来检测边缘的,后面的层有可能检测到物体的部分区域,更靠后的一些层可能检测到完整的物体,这个最好理解的例子就是人脸。
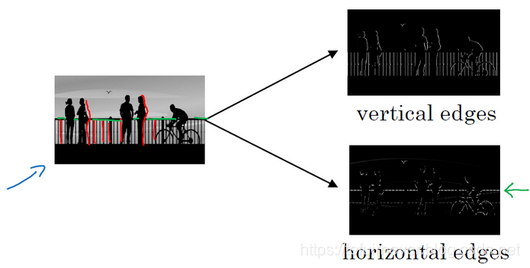
举个例子,给了这样一张图片,让电脑去搞清楚这张照片里有什么物体。
- 可能做的第一件事是检测图片中的垂直边缘,比如,栏杆对应垂直线,与此同时,这些行人的轮廓线某种程度上也是垂线,这些线是垂直边缘检测器的输出。
- 同样,可能也想检测水平边缘,比如说这些栏杆就是很明显的水平线,它们也能被检测到,结果为右面的图。
所以如何在图像中检测这些边缘?
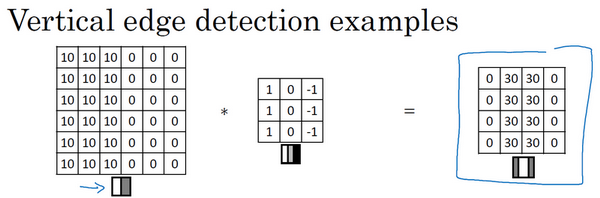
看一个例子,这是一个6×6的灰度图像(因为是灰度图像,所以它是6×6×1的矩阵,而不是6×6×3的,因为没有 RGB 三通道),为了检测图像中的垂直边缘,可以构造一个3×3矩阵,在卷积神经网络的术语中,它被称为 过滤器,即我们要构造一个3×3的过滤器,像这样 ,而在论文它有时候会被称为 核,而不是过滤器,这里我们就叫它过滤器!!
对这个6×6的图像进行卷积运算,卷积运算用 来表示,用3×3的过滤器对其进行卷积。

关于符号表示有一些问题,在数学中 就是卷积的标准标志,但是在 Python 中,这个标识常常被用来表示乘法或者元素乘法,它是一个重载符号,当 表示卷积的时候我会特别说明。
开始卷积:
这个卷积运算的输出将会是一个4×4的矩阵(4 = 6 - 3 + 1,大 - 小 + 步长)那么如何计算得到这个4×4矩阵的?

为了计算第一个元素(在4×4左上角的那个元素),使用3×3的过滤器,将其覆盖在输入图像(蓝色区域),如图所示,然后进行元素乘法(element-wise products)运算,即对应位置相乘,所以:
然后将该结果的每个元素相加,即
就是输出矩阵的第一个元素的值。
接下来,接着计算第二个元素,把蓝色的方块向右移动一步,像下图这样,把这些绿色的标记去掉:

继续做同样的元素乘法,然后加起来,所以是

接下来也是一样,继续右移一步。

继续移得到8。

接下来为了得到下一行的元素,现在把蓝色块下移,现在蓝色块在这个位置:

重复进行元素乘法,以此类推,直到这样计算完矩阵中的其他元素。

这些图片和过滤器表面上就是不同维度的矩阵,但左边矩阵更容易被理解为一张图片,中间的这个被理解为过滤器,右边的图片可以理解为另一张图片,这个就是垂直边缘检测器。
如果要使用编程语言实现这个运算,不同的编程语言有不同的函数,而不是用 来表示卷积。
- 如果在 tensorflow 下,这个函数叫 tf.conv2d;
- 如果在 Keras 下,用 Conv2D 实现卷积运算。
为什么这个可以做垂直边缘检测呢?
来看另外一个例子,这是一个简单的6×6图像,左边一半是10,右边一半是0。如果把它当成一个图片,左边那部分看起来是白色的(像素值10比较亮),右边那部分看起来是比较暗的,用灰色来表示,尽管它也可以被画成黑的。图片里,有一个特别明显的垂直边缘在图像中间,这条垂直线是从黑到白的过渡线,或者从白到深的过渡线。
所以,当用3×3过滤器进行卷积运算时,可视化如下:左边是明亮的,然后有一个过渡,0在中间,然后右边是深色的,卷积运算后得到右边的矩阵。数学运算同样可以验证,最左上角的元素0,就是由这个3×3块(绿色方框标记)经过元素乘积运算再求和得到的:
而30是由这个(红色方框标记)得到的,

如果把最右边的矩阵当成图像,它在中间有一段亮一点的区域,对应检查到这个6×6图像中间的垂直边缘。这里的维数似乎有点不正确,检测到的边缘太粗了,因为在这个例子中,图片太小了,如果用一个1000×1000的图像,而不是6×6的图片,会发现其会很好地检测出图像中的垂直边缘。即输出图像中间的亮处,表示在图像中间有一个特别明显的垂直边缘。
从垂直边缘检测中可以得到的启发是,使用3×3的矩阵(过滤器),垂直边缘是3×3的区域,左边是明亮的像素,中间的并不需要考虑,右边是深色的像素。在这个6×6图像的中间部分,明亮的像素在左边,深色的像素在右边,就被视为一个垂直边缘,卷积运算提供了一个方便的方法来发现图像中的垂直边缘,不是吗?
3、更多边缘检测内容
前面见识到了用卷积运算实现垂直边缘检测,那么如何区分正边和负边?
这实际就是由亮到暗与由暗到亮的区别,也就是边缘的过渡。
还是之前的例子,这张6×6的图片,左边较亮,而右边较暗,将它与垂直边缘检测滤波器进行卷积,检测结果就显示在了右边这幅图的中间部分。
如果原始图片进行边缘的过渡:
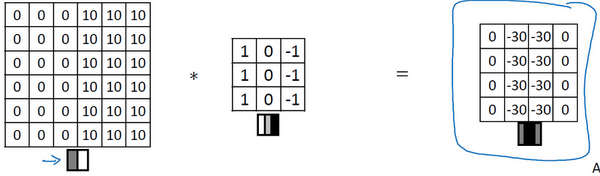
那么它的颜色被翻转了,变成了左边比较暗,而右边比较亮。如果用相同的过滤器进行卷积,最后得到的图中间会是-30,而不是30,如果将矩阵转换为图片,就会是该矩阵下面图片的样子。现在中间的过渡部分被翻转了,之前的30翻转成了-30,表明是由暗向亮过渡,而不是由亮向暗过渡。
当然,如果你不在乎这两者的区别,可以取矩阵的绝对值。但这个特定的过滤器确实可以区分这两种明暗变化的区别!
再来看看更多的边缘检测的例子,除了之前用过的那个3×3的过滤器可以检测出垂直的边缘,右边这个过滤器也能检测出水平的边缘。
- 一个垂直边缘过滤器是一个3×3的区域,它的左边相对较亮,而右边相对较暗。
- 相似的,右边这个水平边缘过滤器也是一个3×3的区域,它的上边相对较亮,而下方相对较暗。

当然还有个更复杂的例子,左上方和右下方都是亮度为10的点,如下图。如果将它绘成图片,右上角是比较暗的地方,左下角也是,而左上方和右下方都相对较亮。如果用这幅图与水平边缘过滤器卷积,就会得到右边这个矩阵。

再举个例子,这里的30(右边矩阵中绿色方框标记元素)代表了左边这块3×3的区域(左边矩阵绿色方框标记部分),这块区域确实是上边比较亮,而下边比较暗的,所以在这里发现了一条正边缘。而这里的-30(右边矩阵中紫色方框标记元素)又代表了左边另一块区域(左边矩阵紫色方框标记部分),这块区域确实是底部比较亮,而上边则比较暗,所以在这里它是一条负边。
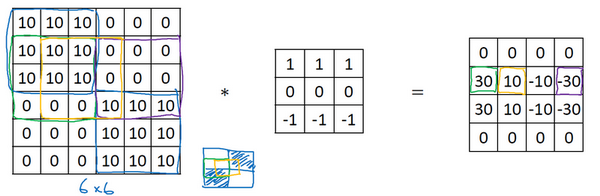
再次强调的是现在使用的都是很小的图片,仅有6×6,但这些中间的数值,比如说这个10(右边矩阵中黄色方框标记元素)代表的是左边这块区域(左边6×6矩阵中黄色方框标记的部分)。这块区域左边两列是正边,右边一列是负边,正边和负边的值加在一起得到了一个中间值。但假如这个一个非常大的1000×1000的类似这样棋盘风格的大图,就不会出现这些亮度为10的过渡带了,因为图片尺寸很大,这些中间值就会变得非常小。
总而言之,通过使用不同的过滤器,可以找出垂直的或是水平的边缘。
事实上,对于这个3×3的过滤器来说,我们只是使用了其中的一种数字组合。
但在历史上,在计算机视觉的文献中,曾公平地争论过怎样的数字组合才是最好的,所以还可以使用这种:
叫做 Sobel 的过滤器,它的优点在于增加了中间一行元素的权重,这使得结果的鲁棒性会更高一些。
此外,计算机视觉的研究者们也会经常使用其他的数字组合,比如这种:
这叫做 过滤器,它有着和之前完全不同的特性,实际上也是一种垂直边缘检测,如果将其翻转90度,就能得到对应水平边缘检测。
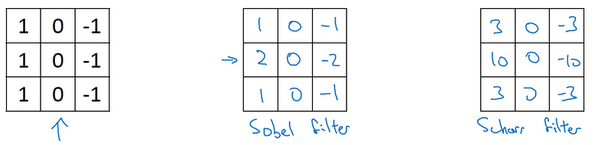
随着深度学习的发展,我们学习的其中一件事就是:当你真正想去检测出复杂图像的边缘,不一定要去使用那些研究者们所选择的这九个数字,但可以从中获益匪浅。 把这矩阵中的9个数字当成9个参数,并且在之后可以学习使用反向传播算法,其目标就是去理解这9个参数。

当得到左边这个6×6的图片,将其与这个3×3的过滤器进行卷积,将会得到一个出色的边缘检测。除了 的过滤器,或者 Sobel 过滤器和 Scharr 过滤器之外,还有另一种过滤器,这种过滤器对于数据的捕捉能力甚至可以胜过任何之前这些手写的过滤器。相比这种单纯的垂直边缘和水平边缘,它可以检测出45°或70°或73°,甚至是任何角度的边缘,所以将矩阵的所有数字都设置为参数,通过数据反馈,让神经网络自动去学习它们,会发现神经网络可以学习一些低级的特征,例如这些边缘的特征。
尽管比起那些研究者们要更费劲一些,但确实可以动手写出这些东西。不过构成这些计算的基础依然是卷积运算,使得反向传播算法能够让神经网络学习任何它所需要的3×3的过滤器,并在整幅图片上去应用它,去输出这些任何它所检测到的特征,不管是垂直的边缘,水平的边缘,还有其他奇怪角度的边缘,甚至是其它的连名字都没有的过滤器。
所以这种将这9个数字当成参数的思想,已经成为计算机视觉中最为有效的思想之一,也是深度学习的核心思想之一。
推荐阅读
- 深度学习入门笔记(一):深度学习引言
- 深度学习入门笔记(二):神经网络基础
- 深度学习入门笔记(三):求导和计算图
- 深度学习入门笔记(四):向量化
- 深度学习入门笔记(五):神经网络的编程基础
- 深度学习入门笔记(六):浅层神经网络
- 深度学习入门笔记(七):深层神经网络
- 深度学习入门笔记(八):深层网络的原理
- 深度学习入门笔记(九):深度学习数据处理
- 深度学习入门笔记(十):正则化
- 深度学习入门笔记(十一):权重初始化
- 深度学习入门笔记(十二):深度学习数据读取
- 深度学习入门笔记(十三):批归一化(Batch Normalization)
- 深度学习入门笔记(十四):Softmax
- 深度学习入门笔记(十五):深度学习框架(TensorFlow和Pytorch之争)
- 深度学习入门笔记(十六):计算机视觉之边缘检测
- 深度学习入门笔记(十七):深度学习的极限在哪?
- 深度学习入门笔记(十八):卷积神经网络(一)
- 深度学习入门笔记(十九):卷积神经网络(二)
- 深度学习入门笔记(二十):经典神经网络(LeNet-5、AlexNet和VGGNet)
参考文章
- 吴恩达——《神经网络和深度学习》视频课程