Hadoop文件存储时将文件分为元数据,数据本身分别存储。
元数据指的是文件的属性信息,如存放位置,大小,创建时间等,NameNode节点保存文件元数据
数据本身指的是文件中的数据,数据分块Block存储可能是一块也可能是多块,这取决数据本身大小,DataNode节点保存文件Block数据
下图是hadoop map-reduce的运行图
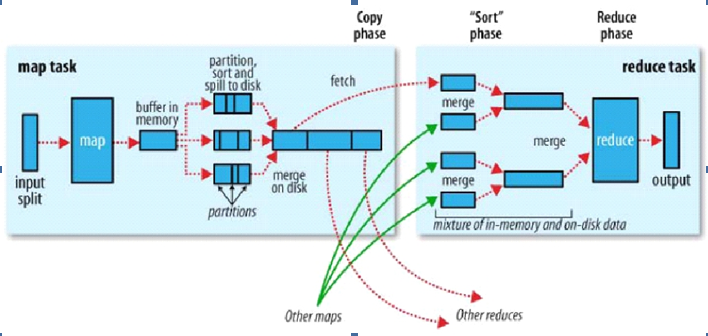
- hadoop运行原理需记住的核心原则是:“相同”的key为一组,调用一次reduce方法,方法内迭代这一组数据进行计算
下面通过以下几个问题来理解map-reduce的运行原理
Client,做了什么事情?
准备了split,split里面包括file路径、文件开始位置、文件大小、分区
环境初始化,做什么事情?
第一确定了splitIndex ;第二文件首行让出
nextKeyValue,做什么事情?
第一布尔返回值;第二key,value的赋值
Output输出,做什么事情?
1>Map输入的是k、v,但map输出的是k、v、p;每个map经过reduce处理后知道了每个map归属于哪个分区
2>内存缓冲区,那是环形缓冲区,内存默认100M,为了不使map阻塞会有个溢写的值,溢写值是80%,达到80%会触发溢写。在溢写之前,在内存中进行快速排序(ps这是整个框架中仅有的一次从乱序到有序,后面都是拿有序数据进行归并)。如果你做了combiner配置,就会排序。combiner就是先按分区排序,分区内按Key在排序生成的小文件
3>所有小文件最后归并成大文件,如果你做了combiner配置,框架默认小文件数据是3,超过3会触发第二次combiner,目的就是为了减少网络IO
Reduce方法迭代的原理是什么?
磁盘上有海量的数据,有个迭代器可以一条条取出数据,取数据过程中会有个假的迭代器,它会通过nextIsSame来判断组是否结束,目的是实现以组为单位迭代器处理数据。