一、死锁的概念
死锁是指两个或两个以上的事务在执行过程中,因争夺锁资源而造成的一种互相等待的现象。若无外力作用,事务都将无法推进下去。
解决死锁问题最简单的方式是不要等待,将任何的等待都转化为回滚,并且事务重新开始。然而在线上环境中,这可能导致并发性能的下降,甚至任何一个事务都不能进行。而这锁带来的问题远比死锁问题更严重,因为这很难被发现并且浪费资源。
解决死锁问题最简单的一种方式是超时,即当两个事务互相等待时,当一个等待时间超过设置的某一阈值时,其中一个事务进行回滚,另一个等待的事务就能继续进行。在InnoDB存储引擎中,参数innodb_lock_wait_timeout用来设置超时的时间。
超时机制虽然简单,但是其仅通过超时后对事务进行回滚的方式来处理,或者说其根据FIFO的顺序选择回滚对象。但若超时的事务所占权重比较大,如事务操作更新了很多行,占用了较多的undo log,这时采用FIFO的方式,就显得不合适了,因为回滚这个事务的时间想对另一个事务所占时间可能会很多。
因此,除了超时机制,当前数据库还普遍采用wait-for graph(等待图)的方式来进行死锁检测。这是一种更为主动的死锁检测方式。InnoDB存储引擎也采用的这种方式。
wait-for graph要求数据库保存以下两种信息:
1、锁的信息链表
2、事务等待链表
通过以上链表可以构造处一张图,而这个图中若存在回路,就代表存在死锁,因此资源间相互发生等待。wait-for graph中,事务为图中的节点。在图中,事务T1指向T2边的定义:
事务T1等待事务T2所占用的资源
事务T1最终等待T2所占用的资源,也就是事务之间在等待相同的资源,而事务T1发生在事务T2的后面
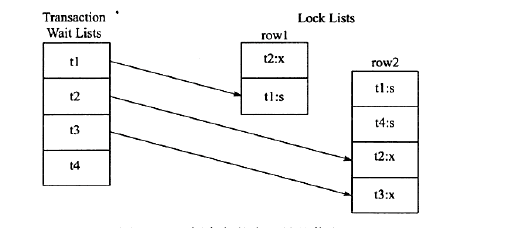
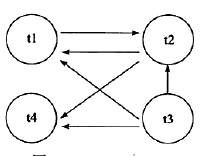
在Transaction wait Lists中可看到共有4个事务t1,t2,t3,t4,故在wait-for graph中应有4个节点。而事务t2对row1占用x锁,事务t1对row2占用s锁。事务t1需要等待事务t2中row1的资源,因此wait-for graph中有条边从节点t1指向节点t2。事务t2需要等待事务t1,t4所占用的row2对象,故而存在节点t2到节点t1,t4的边。同样,存在t3到节点t1,t2,t4的边,因此最终的wait-for graph如图
二、死锁示例
1、示例1
A等待B,B等待A,这种死锁问题被称为AB-BA死锁。

以上操作中,B的事务抛出了1213错误,即表示事务发生了死锁。
死锁的原因是会话A和B的资源在相互等待。
大多数的死锁InnoDB存储引擎本身可以侦测到,不需要人为进行干预。
在会话B中的事务抛出死锁异常后,会话A中马上得到了记录为2的这个资源,这其实是因为会话B中的事务发生了回滚,否则会话A中的事务不可能得到资源。
InnoDB存储引擎不会回滚大部分的错误异常,但是死锁除外。发现死锁后,InnoDB存储引擎会马上回滚一个事务。
Oracle产生死锁的常见原因是没有对外键添加索引,而InnoDB存储引擎会自动对其添加,因而能很好的避免这种情况。