个人作业
——词频统计
一、项目概况
对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等,文件夹内的所有文件)统计字符数、单词数、行数、词频,统计结果以指定格式输出到默认文件中,以及其他扩展功能,并能够快速处理多个文件。
二、需求分析
(1)基本功能
a) 统计文件的字符数;
b) 统计文件的单词总数;
c) 统计文件的总行数;
d) 统计文件中各单词的出现次数,输出频率最高的10个;
e) 对给定文件夹及其递归子文件夹下的所有文件进行统计;
f) 统计两个单词(词组)在一起的频率,输出频率最高的前10个;
g) 在Linux系统下,进行性能分析,过程写到blog中(附加题)。
(2)输入与输出要求
a) 输入以命令行参数传入(文件夹的路径);
b) 在当前路径输出最终结果文件result.txt。
三、功能模块与设计
(1)遍历文件夹
a)windows平台上使用 _finddata_t 结构体,及 _findfirst 和 _findnext等函数来查找文件并遍历子文件夹,linuc平台上进行适当移植,使用dirent结构体,opendir、readdir等函数来遍历;
b)采用深度优先搜索,判断是文件夹则遍历该文件夹,是文件则进行计数。
(2)统计文件中的字符、单词数、行数
a)用fgetc()读取字符,ASCII码值≥32且<=126则计数加一;
b)行数目前是每个文件换行符数目+1;
c)单词数先用字符数组记录两个分隔符之间的所有字符(字母/数字),再判断是否符合单词定义,符合则计数加一。
(3)统计各单词、词组出现频率
a)用两个哈希表来进行查找计数,哈希函数采用ELFhash函数,采用开散列法(拉链法);
b)单词结构体包括次数、单词(同类则保存ASCII码最小的那个)、除去单词最末尾的数字剩下部分的小写(便于判断是否属于同一单词);
c)词组结构体包括次数、两个单词的指针;
(4)对单词、词组出现频率进行排序,各找出前十个并输出
a)目前采用的是最简单的一个方法,用一个容量为10的数组,对全部单词、词组一次遍历,依次数组内容比较,最后数组保留的即为最大的10个。
四、代码实现
(1)遍历文件夹
1)windows平台
a)main函数判断命令行参数是否符合要求


1 if (argc != 2) 2 { 3 printf("one folderpath required!\n"); 4 exit(1); 5 }
b)判断是文件还是文件夹
1 _finddata_t fileInfo; 2 long Handle = _findfirst(argv[1], &fileInfo); 3 4 if (Handle != -1L && (fileInfo.attrib & _A_SUBDIR) == 0) 5 { 6 //It's a file name and not a folder path 7 CountQuantity(argv[1]); 8 } 9 else 10 { 11 //it's a folder path 12 TraverseFolder(argv[1]); 13 }
c)递归遍历文件夹
头文件:#include<io.h>
函数原型:void TraverseFolder(string folderPath) ;
1 void TraverseFolder(string folderPath) 2 { 3 //Traverse a folder using Depth First Search Traversal 4 if (folderPath.empty()) 5 { 6 printf("The folder path is empty!\n"); 7 exit(0); 8 } 9 10 _finddata_t fileInfo; 11 string filePath; 12 filePath = folderPath + "\\*"; 13 14 long Handle = _findfirst(filePath.c_str(), &fileInfo); 15 16 if (Handle == -1L) 17 { 18 printf("cannot match the folder path %s\n", filePath.c_str()); 19 //printf("cannot match the folder path %s\n", filePath); 20 return; 21 } 22 do 23 { 24 //Judge if there are subdirectories 25 if (fileInfo.attrib & _A_SUBDIR) 26 { 27 //Exclude two cases 28 if ((strcmp(fileInfo.name, ".") != 0) && (strcmp(fileInfo.name, "..") != 0)) 29 { 30 //Traverse subdirectories 31 string newPath; 32 newPath = folderPath + "\\" + fileInfo.name; 33 TraverseFolder(newPath); 34 } 35 } 36 else 37 { 38 string fullName; 39 fullName = folderPath + "\\" + fileInfo.name; 40 CountQuantity(fullName.c_str()); 41 } 42 } while (_findnext(Handle, &fileInfo) == 0); 43 44 _findclose(Handle); 45 }
2)linux平台
a)main函数判断命令行参数是否符合要求
1 if (argc != 2) 2 { 3 printf("one dir required!\n"); 4 exit(1); 5 }
b)递归遍历文件夹
头文件:#include<dirent.h>
函数原型:void TraverseFolder(string folderPath) ;
1 void TraverseFolder(string folderPath) 2 { 3 //Traverse a folder using Depth First Search Traversal 4 if (folderPath.empty()) 5 { 6 printf("The folder path is empty!\n"); 7 exit(0); 8 } 9 10 DIR *dir; 11 struct dirent *ptr; 12 13 if ((dir = opendir(folderPath.c_str())) == NULL) 14 { 15 printf("cannot match the folder path %s\n", folderPath.c_str()); 16 return; 17 } 18 while((ptr = readdir(dir)) != NULL) 19 { 20 //Judge if there are subdirectories 21 if (ptr->d_type & DT_DIR) 22 { 23 //Exclude two cases 24 if ((strcmp(ptr->d_name, ".") != 0) && (strcmp(ptr->d_name, "..") != 0)) 25 { 26 //Traverse subdirectories 27 string newPath; 28 newPath = folderPath + "/" + ptr->d_name; 29 TraverseFolder(newPath); 30 31 } 32 } 33 else 34 { 35 string fullName; 36 fullName = folderPath + "/" + ptr->d_name; 37 CountQuantity(fullName.c_str()); 38 } 39 } 40 41 closedir(dir); 42 }
注意:linux系统下,代码中文件路径只能用斜杠“/”来表示,而windows下用“/”和“\\”均可。
(2)字符数、行数、单词数计数
函数原型:void CountQuantity(const char* fileName);//传入文件名
1 void CountQuantity(const char* fileName) 2 { 3 //Count the total number of characters/lines/words 4 FILE *fp = NULL; 5 char ch; 6 char tempWord[WORD_MAX_LENGTH];//for preserving word temprorily 7 wordList wNode, wNodePre = NULL; 8 int i = 0, j = 0, flag = 0; 9 10 if ((fp = fopen(fileName, "r")) == NULL) { 11 printf("cannot open this file %s\n", fileName); 12 exit(0); 13 } 14 15 while ( (ch = fgetc(fp)) != EOF) 16 { 17 if(ch >= 32 && ch <= 126) 18 characterNum++; 19 if (ch == '\n') 20 { 21 lineNum++; 22 } 23 if (isLetter(ch) || isNumber(ch)) 24 { 25 i = 0; 26 tempWord[i++] = ch; 27 while ((ch = fgetc(fp)) != EOF && (isLetter(ch) || isNumber(ch))) 28 { 29 characterNum++; 30 tempWord[i++] = ch; 31 } 32 tempWord[i] = '\0'; 33 34 if (i >= 4 && i <= 1024 && isLetter(tempWord[0]) && isLetter(tempWord[1]) && isLetter(tempWord[2]) && isLetter(tempWord[3])) 35 { 36 // it's a word 37 wordNum++; 38 for (j = i - 1; isNumber(tempWord[j]); j--) 39 { 40 } 41 wNode = CountFrequency(tempWord, j + 1); 42 if (flag == 1) 43 { 44 CountFrequency_Phrase(wNodePre,wNode); 45 } 46 wNodePre = wNode; 47 flag = 1; 48 } 49 if (ch >= 32 && ch <= 126) 50 characterNum++; 51 if (ch == '\n') 52 { 53 lineNum++; 54 } 55 if (ch == EOF) 56 { 57 break; 58 } 59 } 60 } 61 62 fclose(fp); 63 lineNum++; 64 return; 65 }
在统计字符数、行数、单词数的同时,对各个单词、词组出现的频率进行统计。
(3)单词频率统计
宏定义:
#define WORD_MAX_LENGTH 1024 //单词最长长度
#define isLetter(c) (((c) >= 'a' && (c) <= 'z') || ((c) >= 'A' && (c) <= 'Z')))
#define isNumber(c) ((c) >= '0' && (c) <= '9')
#define HASHMOD 22248619 //哈希表容量
单词结构体:
1 typedef struct wordNode
2 {
3 char word[WORD_MAX_LENGTH];
4 char wordPreLow[WORD_MAX_LENGTH];//word excluding numbers in the end
5 int time;
6 struct wordNode *next;
7 }wordNode, *wordList;
全局变量:wordList headList[HASHMOD];
函数原型:int ELFhash(char* key);//哈希函数
void Mystrncpy_lwr(char* &s, char *t, int k);//自定义的一个从字符串t拷贝指定长度字符串到字符串s,并转化为小写字母的函数
wordList CountFrequency(char word[], int lengthPre);//传入单词字符及除去位于最后的数字的单词长度,返回单词结点(便于词组使用)
a)ELF哈希函数
1 int ELFhash(char* key) 2 { 3 //Hash function 4 unsigned long h = 0, g; 5 while (*key) 6 { 7 h = (h << 4) + *key++; 8 g = h & 0xF0000000L; 9 if (g) 10 h ^= g >> 24; 11 h &= ~g; 12 } 13 return(h % HASHMOD); 14 }
b)拷贝及小写转化
1 void Mystrncpy_lwr(char* &s, char *t, int k) 2 { 3 //copy and change to lower case 4 int i; 5 for(i = 0; i < k; i++) 6 { 7 s[i] = t[i]; 8 if (s[i] >= 'A' && s[i] <= 'Z') 9 s[i] += 32; 10 } 11 s[i] = '\0'; 12 }
c)单词频率统计
1 wordList CountFrequency(char word[], int lengthPre) 2 { 3 //Count the frequency of words 4 char* wordPreLow = new char[lengthPre + 1]; 5 int h; 6 wordList wNode = NULL, p, q = NULL; 7 8 Mystrncpy_lwr(wordPreLow, word, lengthPre); 9 10 h = ELFhash(wordPreLow); 11 12 if(headList[h] == NULL) 13 { 14 wNode = new wordNode; 15 wNode->time = 1; 16 strcpy(wNode->word, word); 17 strcpy(wNode->wordPreLow, wordPreLow); 18 wNode->next = NULL; 19 headList[h] = wNode; 20 headList[h]->next = NULL; 21 } 22 else 23 { 24 p = headList[h]; 25 while (p != NULL) 26 { 27 if (strcmp(p->wordPreLow, wordPreLow) == 0) 28 { 29 p->time++; 30 if (strcmp(word, p->word) < 0) 31 { 32 strcpy(p->word, word); 33 } 34 return p; 35 } 36 q = p; 37 p = p->next; 38 } 39 if (p == NULL) 40 { 41 wNode = new wordNode; 42 wNode->time = 1; 43 strcpy(wNode->word, word); 44 strcpy(wNode->wordPreLow, wordPreLow); 45 wNode->next = NULL; 46 q->next = wNode; 47 } 48 } 49 return wNode; 50 }
(4)词组频率统计
词组结构体:
1 typedef struct phraseNode 2 { 3 int time; 4 struct phraseNode *next; 5 wordList word1; 6 wordList word2; 7 }phraseNode, *phraseList;
存放两个单词的指针
全局变量:phraseList headList_Phrase[HASHMOD];
函数原型:int ELFhash_Phrase(char* key1, char* key2);//用于词组的哈希函数,使词组中两个单词对函数返回值都有用处
void CountFrequency_Phrase(wordList word1, wordList word2);//传入词组中两个单词的指针
a)两个单词的哈希函数
1 int ELFhash_Phrase(char* key1, char* key2) 2 { 3 //Hash function for two words 4 unsigned long h = 0, g; 5 while (*key1) 6 { 7 h = (h << 4) + *key1++; 8 g = h & 0xF0000000L; 9 if (g) 10 h ^= g >> 24; 11 h &= ~g; 12 } 13 while (*key2) 14 { 15 h = (h << 4) + *key2++; 16 g = h & 0xF0000000L; 17 if (g) 18 h ^= g >> 24; 19 h &= ~g; 20 } 21 return(h % HASHMOD); 22 }
b)词组频率统计
1 void CountFrequency_Phrase(wordList word1, wordList word2) 2 { 3 //Count the frequency of phrases 4 5 if (word1 == NULL || word2 == NULL) 6 { 7 printf("Empty Pointer\n"); 8 return; 9 } 10 11 int h; 12 phraseList pNode, p, q = NULL; 13 h = ELFhash_Phrase(word1->wordPreLow, word2->wordPreLow); 14 15 if (headList_Phrase[h] == NULL) 16 { 17 pNode = new phraseNode; 18 pNode->time = 1; 19 pNode->word1 = word1; 20 pNode->word2 = word2; 21 headList_Phrase[h] = pNode; 22 headList_Phrase[h]->next = NULL; 23 } 24 else 25 { 26 p = headList_Phrase[h]; 27 while (p != NULL) 28 { 29 if (strcmp(p->word1->wordPreLow, word1->wordPreLow) == 0 && strcmp(p->word2->wordPreLow, word2->wordPreLow) == 0) 30 { 31 p->time++; 32 break; 33 } 34 q = p; 35 p = p->next; 36 } 37 if (p == NULL) 38 { 39 pNode = new phraseNode; 40 pNode->time = 1; 41 pNode->word1 = word1; 42 pNode->word2 = word2; 43 pNode->next = NULL; 44 q->next = pNode; 45 } 46 } 47 }
(5)找出单词、词组中的前10个
全局变量:
wordNode wordTop10[11];
phraseNode phraseTop10[11];
函数原型:void Top10WordPhrase();
a)排序找前十个
1 void Top10WordPhrase() 2 { 3 int i, j; 4 wordNode *p; 5 phraseNode *q; 6 7 for (i = 0; i < HASHMOD; i++) 8 { 9 //find top 10 words 10 if (headList[i] != NULL) 11 { 12 p = headList[i]; 13 while (p != NULL) 14 { 15 for (j = 9; j >= 0 && p->time > wordTop10[j].time || ((p->time == wordTop10[j].time) && (strcmp(p->word, wordTop10[j].word) < 0)); j--) 16 { 17 strcpy(wordTop10[j + 1].word, wordTop10[j].word); 18 wordTop10[j + 1].time = wordTop10[j].time; 19 } 20 if (j < 9) 21 { 22 strcpy(wordTop10[j + 1].word, p->word); 23 wordTop10[j + 1].time = p->time; 24 } 25 p = p->next; 26 } 27 } 28 } 29 for (i = 0; i < HASHMOD; i++) 30 { 31 //find top 10 phrases 32 33 if (headList_Phrase[i] != NULL) 34 { 35 q = headList_Phrase[i]; 36 while (q != NULL) 37 { 38 for (j = 9; j >= 0 && q->time > phraseTop10[j].time; j--) 39 { 40 phraseTop10[j + 1].word1 = phraseTop10[j].word1; 41 phraseTop10[j + 1].word2 = phraseTop10[j].word2; 42 phraseTop10[j + 1].time = phraseTop10[j].time; 43 } 44 if (j < 9) 45 { 46 phraseTop10[j + 1].word1 = q->word1; 47 phraseTop10[j + 1].word2 = q->word2; 48 phraseTop10[j + 1].time = q->time; 49 } 50 q = q->next; 51 } 52 } 53 } 54 }
b)以文件形式输出
1 int i; 2 FILe *fout; 3 4 if ((fout = fopen("result.txt", "w")) == NULL) { 5 printf("cannot open this file result.txt\n"); 6 exit(0); 7 } 8 9 fprintf(fout, "char_number : %d\n", characterNum); 10 fprintf(fout, "line_number : %d\n", lineNum); 11 fprintf(fout, "word_number : %d\n", wordNum); 12 fprintf(fout, "\n"); 13 14 for (i = 0; i <= 9; i++) 15 { 16 fprintf(fout, "%s: %d\n", wordTop10[i].word, wordTop10[i].time); 17 } 18 fprintf(fout, "\n"); 19 20 for (i = 0; i <= 9; i++) 21 { 22 fprintf(fout, "%s %s: %d\n", phraseTop10[i].word1->word, phraseTop10[i].word2->word, phraseTop10[i].time); 23 }
五、代码质量和性能分析
(1)质量分析
无错误或警告;
(2)性能分析
1)vs自带性能分析工具
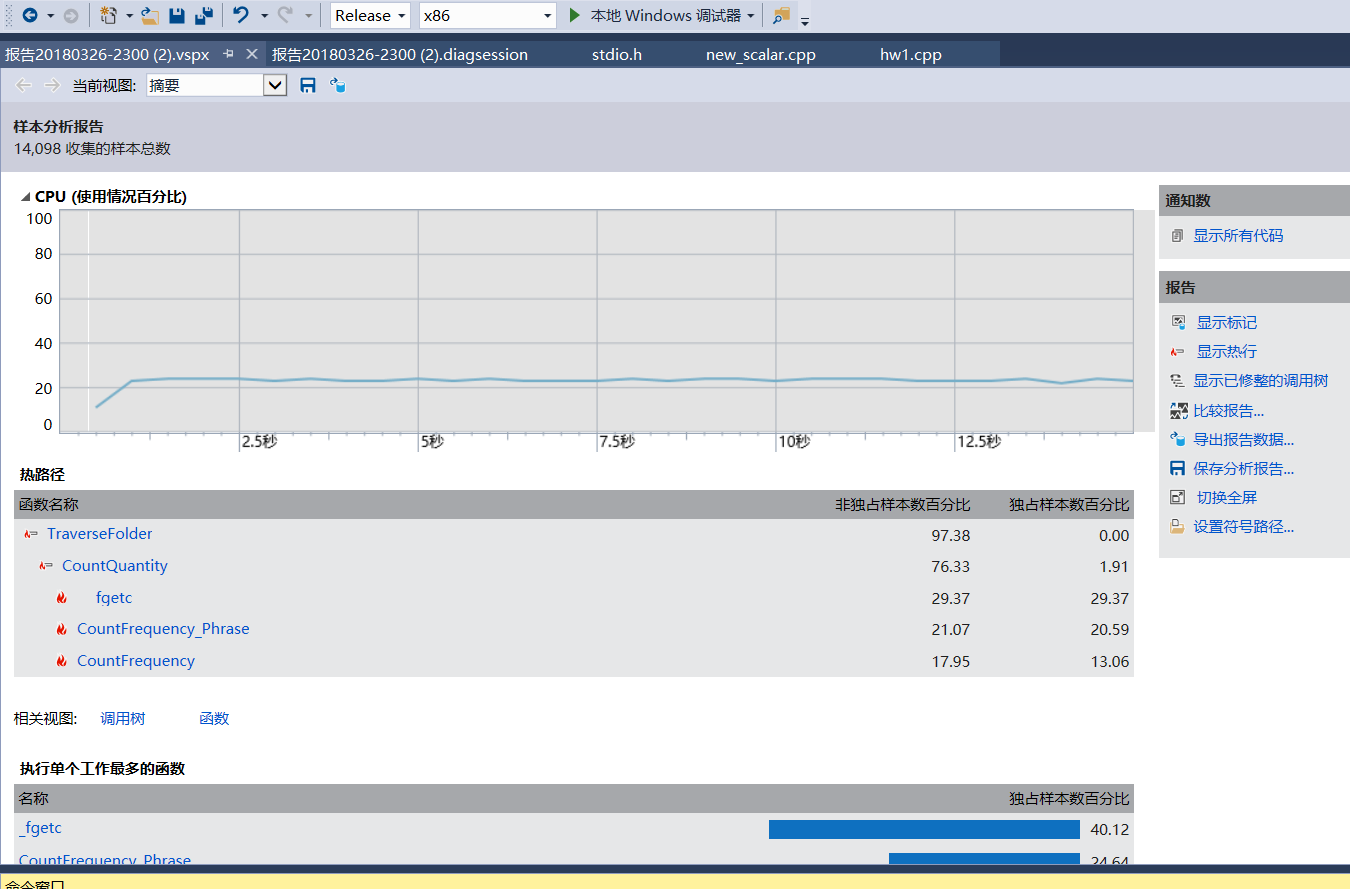
(样本分析报告,运行时间15s左右)

(存储字符判断是否为单词的代码块)

(单词统计、词组统计函数的调用语句)

(哈希表判断是否是空结点)
分析:
a)通过对热行查看,运行次数最多的就是fgetc()函数,但是因为整体架构的原因,不好修改,而且我觉得这个时间消耗也是必不可少的;
b)其他一些执行次数多的我感觉都是程序结构里比较重要的语句,然后暂时也没想到更好的方法;
c)之前担心的排序耗时多,结果发现排序函数只占不到1%,所以整个代码的执行时间还是在统计这一块;
d)对于string和字符数组两种形式,我只是在文件路径这里使用了string,修改成char型数组后发现二者时间相差不大;
c)因为我目前掌握的优化方法不多,只局限一些减少重复计算等,这些在具体编码时也考虑到了,比如多存一个单词的去掉后缀的小写形式减少重复计算等,程序运行时间也算比较快,所以优化的地方并不多。
2)Linux上性能分析
通过查找资料,可以用GPROF进行性能分析
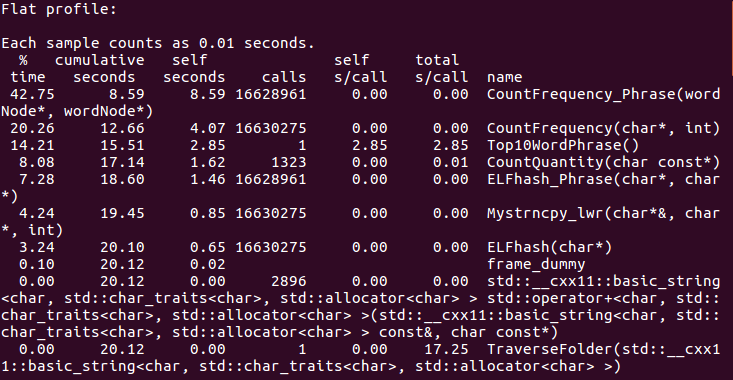
(函数调用情况)
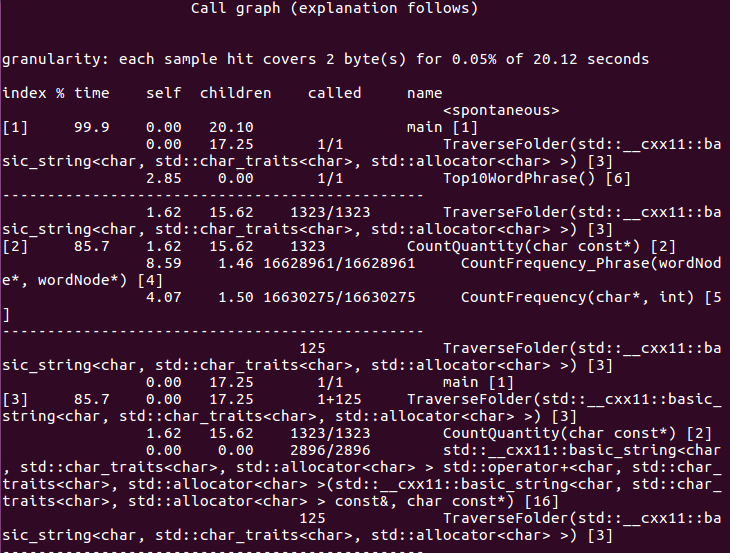
(函数调用关系图)
分析:
a)由性能分析结果,可以看到,执行时间最长的就是单词和词语频率统计的函数,这跟样本数量太大有关; 词组统计的运行时间大致为单词统计的两倍,这也符合常理;
b)排第三的是排序函数,这个在我意料之外,因为之前vs性能分析结果中,排序的这个函数根本没有出现在性能报告的前面;
c)Linux上运行代码时,时间是windows上运行时间的几倍,初步猜测是Linux虚拟机的内存不够。
六、测试设计与分析
(1)助教的样例
运行时间: Release模式生成的.exe文件运行时间15s左右,但linux虚拟机上时间更慢,可能是内存等的原因。
输出结果: 字符数、行数、单词数均有偏差(╯﹏╰)b;
前十单词结果正确;
前十词组结果正确;
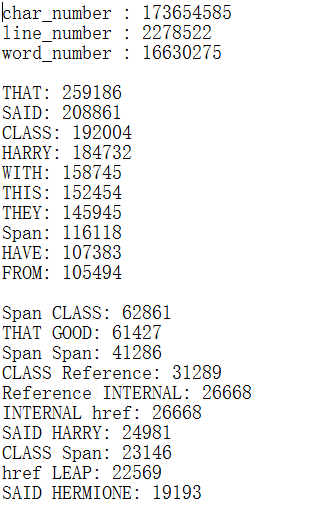

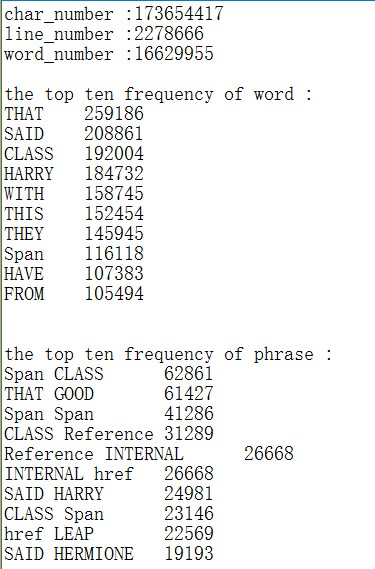
(左为我在windows上的输出,中为linux上的输出,右为样例输出)
(2)遍历文件夹
命令行参数:D:\调研报告(代码输出文件夹内所有文件名字)
输出:

按照深度优先搜索进行遍历;
(3)空文件夹
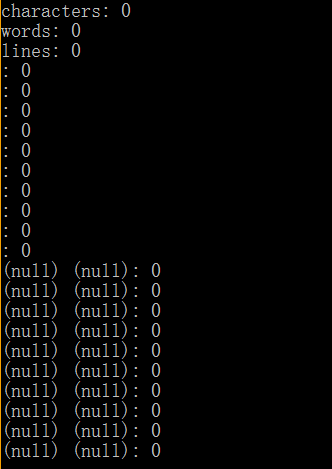
字符数、行数、单词数均为0;
(4)空文件
输出:

字符数、单词数为0,行数为1,因为空行也算一行;
(5)错误的文件路径
输出:

输出错误信息
(6)只包含一个单词的文件(结束没有换行)
文件内容:

输出:

(7)同一类单词按字典顺序输出
文件内容:
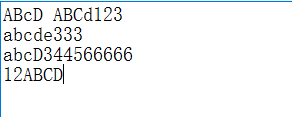
输出:

按单词的定义:ABcD、ABCd123、abcD344566666均算同一类单词,输出时按ASCII码最小(即ABCd123)输出;
(8)词组按词典顺序输出
文件内容:

输出:

词组中每个单词按他ASCII码最小的形式输出,由于123good555不算单词,所以它前后的gooD777、goOd也算词组,所以这一词组共出现了三次。
(9)不同类型文件
文件内容:

输出:
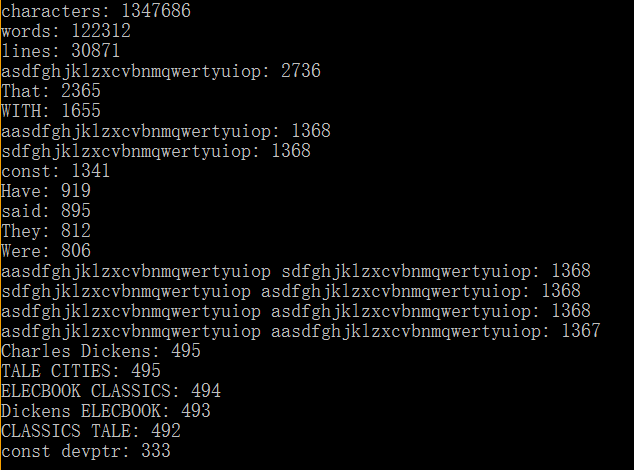
与助教的.exe文件一致
(10)特殊文件
文件内容:

用Notepad++打开为乱码;
输出:
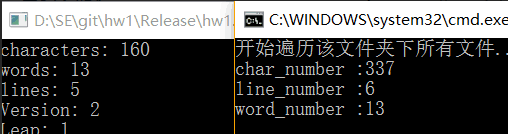
(左为我的程序,右为助教的.exe文件)
可以看到,行数有区别,字符数有较大差别,可能还是在对文件处理、细节判断上有出入。
七、总结收获
这次软工的个人作业整体的框架还不是很难,主要是细节很多,再加上个人编程经验实在不足,所以在构想编程方面花了大量时间,然后具体编程时效率也不高,而且犯了一些以前也经常犯的小错误,比如忘记“p = p->next;”、排序时数组下标搞错、某些情况没有及时用“break”跳出循环等等。
此外,在代码调试上也花了大很多时间,然后调试的进展也不大。还有诸如代码移植、linux上代码分析等事项也耗费了很多时间,主要还是以前没有接触过的原因。总的来说,这周在这个作业上真的花了大量大量的时间,从周五晚开始,一直到周四,才算差不多完整地完成了作业,虽然仍然有很多瑕疵。
收获的话还是有的,比如之前提到的一些小bug让我再次长了点记性,再就是学习了以前不会的遍历文件夹的方法,还有熟悉了像vs的使用、linux虚拟机的安装配置和在虚拟机上运行代码等等操作。通过这次作业,我把以前学的一些知识(如哈希表等)在实际中更灵活的运用,也一定程度是开阔了自己的思维。
附:
(1)Github管理代码
Github地址:https://github.com/hytu99/homework_1
(2)PSP表格
|
Status |
Stages |
预估耗时/min |
实际耗时/min |
|
Accept |
【计划】 Planning |
60 |
80 |
|
Accept |
——估计时间 Estimate |
60 |
80 |
|
Accept |
【开发】 Development |
790 |
1280 |
|
Accept |
——需求分析 Analysis |
10 |
5 |
|
Accept |
——设计文档 Design Spec |
40 |
40 |
|
Accept |
——设计复审 Design Review |
10 |
10 |
|
Accept |
——代码规范 Coding Standard |
10 |
5 |
|
Accept |
——具体设计 Design |
60 |
100 |
|
Accept |
——具体编码 Coding |
480 |
780 |
|
Accept |
——代码复审 Code Review |
60 |
40 |
|
Accept |
——测试 Test |
120 |
300 |
|
Accept |
【记录用时】 Record Time Spent |
20 |
10 |
|
Accept |
【测试报告】 Test Report |
60 |
40 |
|
Accept |
【算工作量】 Size Measurement |
20 |
15 |
|
Accept |
【总结改进】 Postmortem |
40 |
30 |
|
Accept |
【合计】 Summary |
990 |
1455 |