Java中网络相关API的应用
一、InetAddress类
InetAddress类用于标识网络上的硬件资源,表示互联网协议(IP)地址。
-
InetAddress类没有构造方法,所以不能直接new出一个对象;
-
InetAddress类可以通过InetAddress类的静态方法获得InetAddress的对象;
1 InetAddress.getLocalHost();//获取本地对象 2 InetAddress.getByName("");//获取指定名称对象
主要方法使用:
1 //获取本机的InetAddress实例 2 InetAddress add=InetAddress.getLocalHost(); 3 System.out.println("本地计算机名称:"+add.getHostName()); 4 System.out.println("本地IP地址:"+add.getHostAddress()); 5 byte[] bytes=add.getAddress();//获取字节数组形式的IP地址 6 System.out.println("字节数组形式的IP地址:"+Arrays.toString(bytes)); 7 System.out.println(add); 8 9 //根据机器名获取InetAddress实例 10 InetAddress add2=InetAddress.getByName("LAPTOP-CU3IL302"); 11 System.out.println("本地计算机名称:"+add2.getHostName()); 12 System.out.println("本地IP地址:"+add2.getHostAddress()); 13 //根据IP地址和机器名称获取InetAddress实例 14 InetAddress add3=InetAddress.getByAddress("LAPTOP-CU3IL302",bytes); 15 System.out.println("本地计算机名称:"+add3.getHostName()); 16 System.out.println("本地IP地址:"+add3.getHostAddress());
运行结果:

结论:
-
getHostName()---->获取机器名称
- getHostAddress()----->获取ip地址
-
getAddress()---->获取ip地址字节数组,与ip地址一一对应
-
System.out.println(add)----->直接输出的对象信息为计算机名称/IP地址
二、URL统一资源定位符
1)概念
- URL:统一资源定位符,表示internet上的网络资源。
- URL由两部分组成:协议名称和资源名称,中间用冒号隔开。
例如:https://www.cnblogs.com/是博客园的首页网址,其中http表示协议(超文本传输协议),后面的网址就是资源名称。
2)URL常用方法
在java.net中提供了URL类来表示URL。
URL常用方法存在java.net包中,提供创建url/子url,获取url等方法。
---------------使用URL基本步骤-----------------
第一步:创建一个URL对象
这里介绍两种创建URL对象的方法,一种直接创建一个指定地址的URL,另一种是在刚刚创建的URL对象上嵌套一个新的URL
1 //创建一个URL的实例 2 URL blog =new URL("https://www.cnblogs.com"); 3 //?后面表示参数,#后面表示锚点 4 URL url=new URL(blog,"/index.html?username=hysum#test");
注:这里有关URL参数的说明先不作详细解释,之后会专门写一篇关于这方面的文(还在学习中哈)。
第二步:使用URL方法调用相关信息
1 System.out.println("协议:"+url.getProtocol()); 2 System.out.println("主机:"+url.getHost()); 3 //如果未指定端口号,则使用默认的端口号,此时getPort方法返回值为-1 4 System.out.println("端口:"+url.getPort()); 5 System.out.println("文件路径:"+url.getPath()); 6 System.out.println("文件名:"+url.getFile()); 7 System.out.println("相对路径:"+url.getRef()); 8 System.out.println("查询字符串:"+url.getQuery());
运行结果:
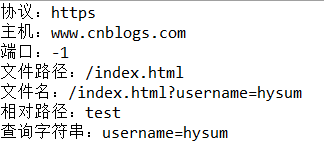
解惑:为什么getPort方法返回的是-1?
答:如果未指定端口号,则使用默认的端口号,此时getPort方法返回值为-1。
解惑:文件路径/文件名/相对路径/查询字符串在URL中分别代表什么?
答:文件路径-- 即不含任何特殊符号的路径;
文件名-- 文件路径+?后面的参数;
相对路径-- #后面的锚点;
查询字符串--?后面的参数。
第三步:读取网页内容
1.通过URL对象的openStream()方法可以得到指定资源的输入流。
2.通过输入流可以读取、访问网络上的数据。
基本实现步骤如下:
- 生成URL对象
- 通过openStream方法获得字节输入流,即InputStream
- 把InputStream包装成字符输入流InputStreamReader(根据网页的编码格式构造)
- 包装成缓冲流提高效率
- 声明一个String来储存读取的内容,通过while循环输出(不唯一)
- 关闭所有的流,close
1 URL url= new URL("http://www.baidu.com"); 2 //获取字节输入流通过openStream方法 3 InputStream is=url.openStream(); 4 //转化成字符输入流 5 InputStreamReader isr=new InputStreamReader(is,"utf-8"); 6 //加缓冲提高读取效率 7 BufferedReader br=new BufferedReader(isr); 8 String date; 9 while((date=br.readLine())!=null){ 10 System.out.println(date); 11 }
注意:
- 完成后要关闭资源相关资源:如上面的br,isr字符输入流,is字节输入流。
-
如果输出是乱码则要在字符输入流中规定编码为该URL指定网页的编码格式。
第四步:保存网页内容为HTML文件
1 BufferedReader br=new BufferedReader(isr); 2 PrintWriter pw=new PrintWriter("C:\Users\acer\Desktop\baidu.html"); 3 String date; 4 while((date=br.readLine())!=null){ 5 pw.println(date); 6 pw.flush(); 7 }
运行后,我桌面就生成了一个baidu.html文件:

双击打开,发现都是乱码,这其实是浏览器编码解析问题。
把浏览器编码改为简体中文,则可以正常显示了

---------------点击查看更多关于Socket信息------------------