2018-07-29 17:42:29
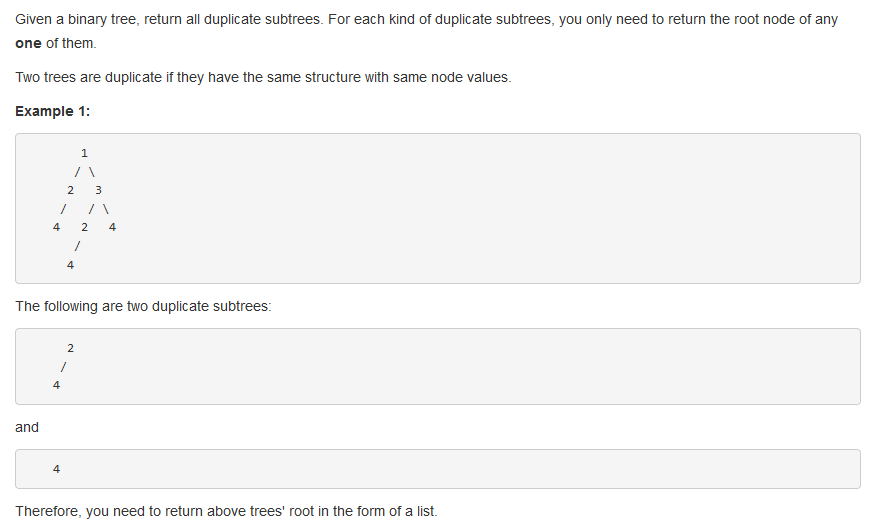
问题描述:
问题求解:
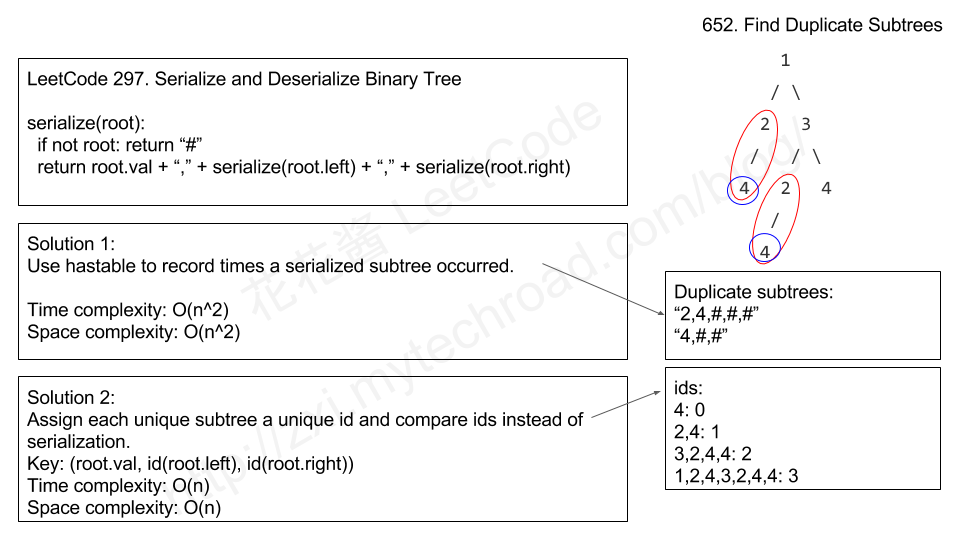
本题是要求寻找一棵树中的重复子树,问题的难点在于如何在遍历的时候对之前遍历过的子树进行描述和保存。
这里就需要使用之前使用过的二叉树序列化的手法,将遍历到的二叉树进行序列化表达,我们知道序列化的二叉树可以唯一的表示一棵二叉树,并可以用来反序列化。
想到这里其实问题就已经解决了一大半了, 我们只需要在遍历的过程中将每次的序列化结果保存到一个HashMap中,并对其进行计数,如果重复出现了,那么将当前的节点添加到res中即可。
public List<TreeNode> findDuplicateSubtrees(TreeNode root) {
List<TreeNode> res = new ArrayList<>();
Map<String, Integer> map = new HashMap<>();
helper(root, map, res);
return res;
}
private String helper(TreeNode root, Map<String, Integer> map, List<TreeNode> res) {
if (root == null) return "#";
String str = root.val + "," + helper(root.left, map, res) + "," + helper(root.right, map, res);
if (map.containsKey(str)) {
if (map.get(str) == 1) res.add(root);
map.put(str, map.get(str) + 1);
}
else map.put(str, 1);
return str;
}
算法改进:
上述的算法基本可以在O(n)的时间复杂度解决问题,但是其中的字符串拼接是非常耗时的,这里可以对这个部分做出一点改进。如果我们不用序列化结果来表征一个子树,用一个id值来表征的话,那么就可以规避掉字符串拼接的问题。
这里直接使用id的size来进行id的分配,值得注意的是由于已经给null分配了0,那么每次分配的大小应该是size + 1。
public List<TreeNode> findDuplicateSubtrees(TreeNode root) {
List<TreeNode> res = new ArrayList<>();
Map<Long, Integer> id = new HashMap<>();
Map<Integer, Integer> map = new HashMap<>();
helper(root, id, map, res);
return res;
}
private Integer helper(TreeNode root, Map<Long, Integer> id, Map<Integer, Integer> map, List<TreeNode> res) {
if (root == null) return 0;
Long key = ((long) root.val << 32) | helper(root.left, id, map, res) << 16 | helper(root.right, id, map, res);
if (!id.containsKey(key))
id.put(key, id.size() + 1);
int curId = id.get(key);
if (map.containsKey(curId)) {
if (map.get(curId) == 1) res.add(root);
map.put(curId, map.get(curId) + 1);
}
else map.put(curId, 1);
return curId;
}