2018-02-20 14:35:34
数据库管理系统(英语:database management system,缩写:DBMS) 是一种针对对象数据库,为管理数据库而设计的大型电脑软件管理系统。具有代表性的数据管理系统有:Oracle、Microsoft SQL Server、Access、MySQL及PostgreSQL等。
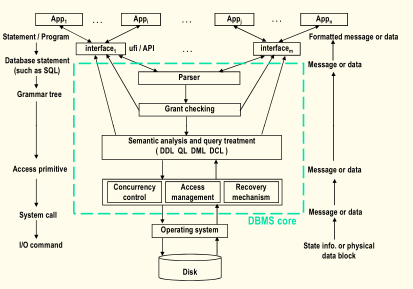
一、DBMS内核
Parser:编译器,或者说是语法分析器
Grant checking:授权检查器,用来检查特定用户的权限问题
Semantic analysis and query treatment ( DDL QL DML DCL ):语义分析和查询处理,核心中的核心,SQL语句的功能实现
Access management:访问管理,将表和文件进行映射
Concurrency control:并发控制
Recovery mechanism:恢复机制
二、DBMS的进程结构
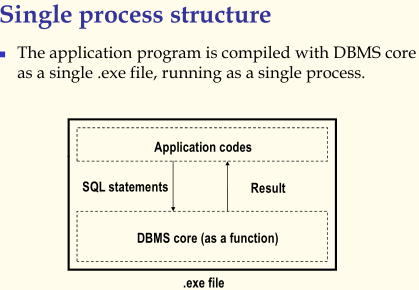
1、单进程结构,Single process structure
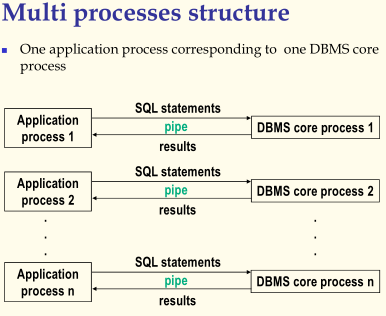
2、多进程结构,Multi processes structure
一个应用进程对应一个DBMS核心进程,每当一个应用进程需要访问数据库的时候,就会发起一个连接请求,系统就会生成一个DBMS核心进程,并创建管道进行交互。
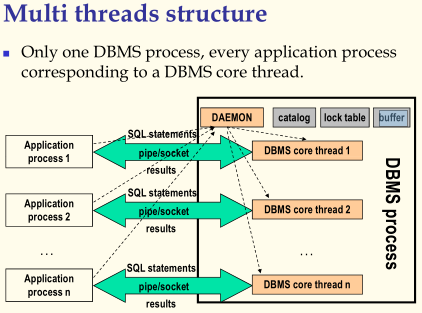
3、多线程结构,Multi threads structure
在操作系统中创建进程需要消耗大量的系统资源,如果使用多进程结构,每次对新的应用程序都创建一个新的DBMS核心进程,那么操作系统的资源将会很快耗尽。这里,可以使用多线程结构来进行优化。线程可以看成一个轻量级的进程,一个进程里可以包含多个线程,每个线程消耗的系统资源要比进程少很多。
同一个进程中的多个线程共享进程的数据,在DBMS核心进程中有如下的共享内容:
DAEMON:用来监听来自应用程序的请求,对每个新的应用程序的连接请求建立一个线程;
catalog:目录,记录数据库中表的信息;
lock table:锁表,在并发控制的时候发挥作用;
buffer:缓冲区;
三、Database Access Management
数据库访问管理所要做的是将对数据库的访问转换成操作系统中的文件对象的访问。数据库访问管理,也就是物理层上的文件结构定义和文件的存取路径将会直接影响数据库的查询速度。没有一种文件结构是可以一劳永逸的,所以我们需要考虑一下几个问题:
- 访问类型;
- 文件结构;
- 索引技术;
- 访问原语;
1)访问类型,Access Types
Query all or most records of a file (>15%):查询的元组数量占文件的15%以上,我们就认为是这种类型,一般这种大量查询可以使用堆文件进行存储;
Query some special record
Query some records (<15%)
Scope query:范围查询
Update
2)文件存储结构,File Organization
堆文件:顺序扫描进行查询,适合查询超过15%的查询操作
Hash文件:查询效率高,适合查询特殊查询操作
索引文件:堆文件 and B+树索引,适用面最广,也最常用
动态Hash:映射空间随着数据量的大小进行改变
Raw disk:注意文件的逻辑顺序和物理顺序是两个概念,一般来说,物理顺序是由操作系统控制的。使用Raw disk可以自己确定文件在磁盘的存储位置,一次申请连续存储空间,按属性值连续存储,也被称为Clustering index,簇集索引。
3)索引技术

四、查询优化
关系型数据库在刚提出的时候是遭到反对的,因为使用关系型数据库在查询的时候效率很低,比如一个10000条元组的表和50000条元组的表进行连接,那么就会产生5亿条元组,这是不可接受的。但是,为什么现在关系型数据库成为了主流呢?因为其查询优化技术有了长足的发展。
查询优化会将用户的SQL语言进行重写,生成效率更高的查询语言进行查询,其根本目标就是使用尽量少的资源,尽量快的将查询结果返回给用户。
可以分为两步优化:Algebra Optimization(代数优化,就是重写);Operation Optimization(操作优化)
举个例子:计算x^2 + 2xy + y^2,可以先进行代数优化将之转换成等价的(x+y)^2,所谓操作优化就是选择合适的加法和乘法实现方式。

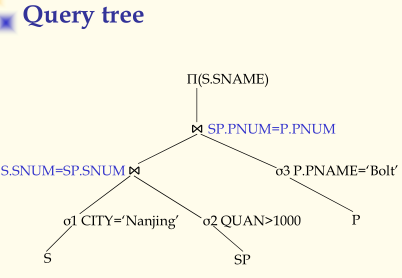
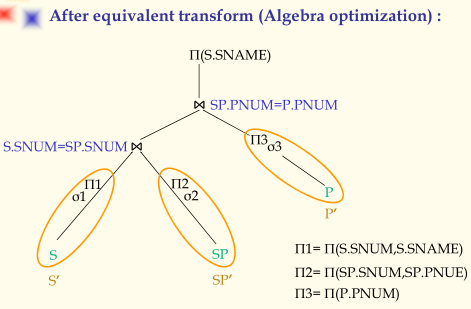
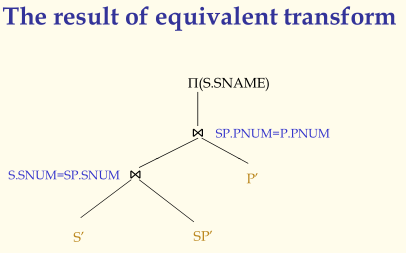
- Algebra Optimization
代数优化的基本目标是对用户的查询操作进行改写,将之生成更优的形式。基本原则是将一元操作尽可能的向下压;寻找合并公共子表达式。
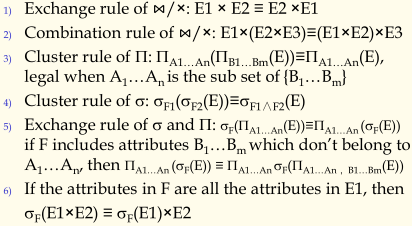

- Operation Optimization
操作优化的目标是将每个操作如投影,连接操作等如何选择更好的算法进行实现。下面以连接运算为例。
连接操作的方法一:嵌套循环,算法复杂度为O(nm)。
连接操作的方法二:归并扫描,前提按照连接属性的值进行了外排序。
连接操作的方法三:基于B+索引的循环,通过B+树进行查找,而不用单纯遍历。
四、恢复机制
数据库的恢复机制指:预防数据库出现差错;发生故障后,可以进行恢复,将数据库变为稳定的状态。
恢复机制有两个基本的原则:冗余是必须的,也就是要进行必要的备份工作;能够预测所有的可能故障情况。
恢复机制的实现方法:
1) Periodical dumping
Periodical dumping:每隔一段时间将整个数据库备份一次。
这种方法有一个缺点就是完整备份数据库不可能经常进行,这样在两次备份中出现差错会导致中间很多的更新操作的丢失。

解决方法很简单,就是在间断性备份的基础上加上增量备份 Backup + Incremental dumping。由于增量的数据量较少,可以较多次的进行备份操作。虽然依然存在丢失更新,但是由于间隔短,所以丢失的内容较少。早期使用,适合小型的数据库。
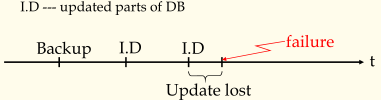
2)Backup + Log
备份加日志,所谓日志,其实就是流水帐,记录备份一来,用户对数据库做的所有改变。不会产生丢失更新的问题。

五、事务处理机制
对数据库的操作是以事务为单位进行运行的,如果没有显示的指明Transaction,则默认每条SQL为一个事务。
一个事务(Transaction)就是一组SQL语句,具有如下特性ACID:
- 原子性(Atomic):要么全部执行,要么都不执行;
-
一致性(Consistent):事务在完成时,必须使所有的数据都保持一致状态。在相关数据库中,所有规则都必须应用于事务的修改,以保持所有数据的完整性。事务结束时,所有的内部数据结构(如 B 树索引或双向链表)都必须是正确的;
-
隔离性(Insulation):同时运行的事务不能相互干扰;
- 持久性(Duration):一个事务只要完成,那么这个操作将永久反映在数据库上。

六、并发控制
并发是指在多用户数据库管理系统里,允许多个事务同时对数据库进行访问。
支持并发的好处:提高系统的利用率和减少响应时间;由于事务很有可能访问数据库的不同内容,所以并发会极大的提高效率。
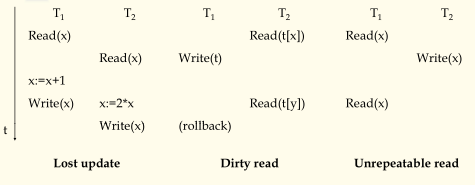
1)并发中可能会出现的三种冲突
- write – write:写写冲突,会造成丢失更新的问题。写写冲突是必须避免的。
- write – read:写读冲突,会造成数据的脏读的问题。
- read – write:读写冲突,会造成数据的重复读冲突的问题。
2)可串行化理论
可串行化理论是用来判别并行运算的结果是否正确的依据。并发控制的目标就是并发结果是可串行化的。
可串行化是指 {T 1 ,T 2 ,…T n }这n个事务的并发结果如果和其串行运行结果的其中一个相等(n!中的任意一个),那么我们就认为,这次的并发执行的结果是正确的。
3)封锁法
加锁机制是最常见的并发控制策略,其核心思想就是:在并发的事务对数据库中数据进行访问的时候需要提前加锁,如果是没有冲突的话,那么各自锁上自己占用的资源,如果产生了冲突,那么就按照先抢到锁的先运行的方法来执行,其实就是一种通过锁机制强行串行化的方法,从而保证并发结果是可串行化的。
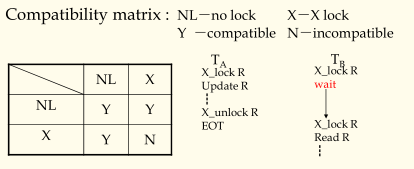
(a)X locks
系统中只有一种锁,就是排他锁,事务对数据的读或写都要申请排他锁。
定理:并行调度是Well-formed + 2PL,则可证明其并行结果是可串行化的。
(well-formed:每个事务都很守规矩,即每次读写数据前都会先申请锁)
(2PL:事务在读写数据前会先统一进行申请锁,最后再统一释放锁,也就是说在释放锁资源后不再继续申请锁)

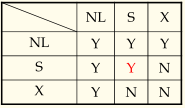
(b)(S,X) locks
我们知道,多个事务同时读一个数据是没有冲突的,所以如果只是单纯的排他锁的话,系统的效率就会很低。为了进一步提高效率,提出了(S,X) locks。
S locks:读操作申请
X locks:写操作申请
(c)(S,U,X) locks
我们知道,在更新操作的时候,很多情况下是先把数据读取出来再对对其修改,最后写回。我们可以在写回前定义一个U锁,在写回的时候再升级成X锁。也就是见缝插针,尽量推迟X锁的加锁时间,在update期间允许读操作,可以进一步提高效率。
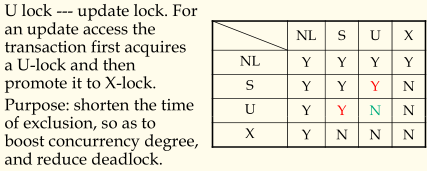
4)死锁和活锁
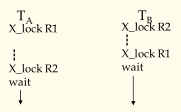
死锁(Dead lock):多个并发运行的事务之间出现循环等待,即每个事务拥有部分锁资源,又渴望获得对方的锁资源,导致任何一个事务都没法获得全部资源来完成整个事务,称为死锁。
例如下面的例子,Ta申请了R1的锁,Tb申请了R2的锁,这两者是没有冲突的,你申请你的,我申请我的。之后Ta又申请了R2的锁,Tb又申请了R1的锁,这个时候就很尴尬了,因为两者都会进入等待,等待自己的锁被释放,于是进入了循环等待,两个事务都没法获得全部的资源。
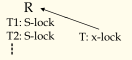
活锁(Live Lock):尽管其他事务都在有限长的时间内获得了锁资源,但是由于系统调度的问题,某个事务等待了很久依然没有获得该资源,称为活锁。
例如下面的例子,对于数据R,T1,T2申请得到了S锁,进行读操作,这时T来申请X锁,发现有S锁,于是进行等待,之后又有T3,T4...来进行读操作,根据定义可以继续申请到S锁,这样T在下一次重新申请的时候依然会发现R上还是有S锁,又要继续等待,这就称为活锁,也被称为饿死现象。
解决方案:
对于活锁,解决方案比较简单,可以采用FIFO,先进先出的调度方案来进行解决。
对于死锁,有两类解决方案,如下。
(1) Solving(permit it occurs, but can solve it)
- TimeOut,也就是给每个事务的等待时间设置了一个常量,如果等待时间超过阈值,则认为发生死锁,则将该事务kill掉,稍后重新执行,在小系统里使用;
- 等待图法,根据事务和等待关系构造等待图,对等待图进行判环就可以发现是否出现了死锁,检查是否出现环的时机有两种主要方案,一是新填加边的时候进行判环;二是定期检查,当判定为死锁后,则需要在环中挑选一个牺牲者,然后将之kill掉,最后在重新执行那个牺牲者;

(2) Prevention(don’t let it occur)
- 规定所有的锁在初始化阶段需要全部申请到:这样要么获得全部锁,执行语句,要么全部都没有获得,不会出现拥有部分锁资源的情况。(数据库系统里不太现实)
- 给资源进行排序,必须按规定从高到低进行申请:这样比如两个事务都要申请R1,R2的锁,第一个事务申请到R1的时候,第二个事务是没有办法先申请到R2的锁的,因为必须按顺序先等待R1的锁被释放,申请到R1的锁,才能申请R2的锁。(数据库系统里不太现实)
- 事务重置法:数据库中比较实用的方法。具体来说就是给每个事务定义一个时间戳(Time Stamp),该时间戳既可以作为TID,也可以用来比较两个事务的年龄。在发生冲突的时候,我们可以比较两个事务的年龄,这时候就有两个策略:i)Wait-die:年老 等待 年轻 ,即遇到碰撞,如果当前事务比较年轻,则kill掉自己,过一段时间自动按原时间戳重新执行;如果自己比较年老,则进入等待。ii)Wound-wait:年轻 等待 年老 ,即遇到碰撞,如果当前事务比较年老,则kill掉对方,如果自己比较年轻,则进入等待。注意,这两种方案都是kill年轻的事务,并且由于事务的执行的单方向的特性,所以不会产生死锁。另外,由于当前事务之前的事务是有限多个,所以不会出现永久等待的活锁现象。
