线程锁
线程锁的主要目的是防止多个线程之间出现同时抢同一个数据,这会造成数据的流失。线程锁的作用类似于进程锁,都是为了数据的安全性
下面,我将用代码来体现进程锁的作用:
from threading import Thread,Lock
x = 0
def task():
global x
for i in range(200000):
x = x+1
if __name__ == '__main__':
t1 = Thread(target=task)
t2 = Thread(target=task)
t3 = Thread(target=task)
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
print(x)
t1 的 x刚拿到0 保存状态 就被切了
t2 的 x拿到0 进行+1 1
t1 又获得运行了 x = 0 +1 1
思考:一共加了几次1? 加了两次1 真实运算出来的数字本来应该+2 实际只+1
这就产生了数据安全问题
这个时候我们就可以利用进程锁来避免出现这种问题
from threading import Thread,Lock
x = 0
mutex = Lock()
def task():
global x
mutex.acquire()
for i in range(200000):
x = x+1
mutex.release()
if __name__ == '__main__':
t1 = Thread(target=task)
t2 = Thread(target=task)
t3 = Thread(target=task)
t1.start()
t2.start()
t3.start()
t1.join()
t2.join()
t3.join()
print(x)
死锁问题
from threading import Thread,Lock
mutex1 = Lock()
mutex2 = Lock()
import time
class MyThreada(Thread):
def run(self):
self.task1()
self.task2()
def task1(self):
mutex1.acquire()
print(f'{self.name} 抢到了 锁1 ')
mutex2.acquire()
print(f'{self.name} 抢到了 锁2 ')
mutex2.release()
print(f'{self.name} 释放了 锁2 ')
mutex1.release()
print(f'{self.name} 释放了 锁1 ')
def task2(self):
mutex2.acquire()
print(f'{self.name} 抢到了 锁2 ')
time.sleep(1)
mutex1.acquire()
print(f'{self.name} 抢到了 锁1 ')
mutex1.release()
print(f'{self.name} 释放了 锁1 ')
mutex2.release()
print(f'{self.name} 释放了 锁2 ')
for i in range(3):
t = MyThreada()
t.start()
运行程序,会发现程序执行一半卡死了这就是因为发生了死锁问题
两个线程
线程1拿到了(锁头2)想要往下执行需要(锁头1),
线程2拿到了(锁头1)想要往下执行需要(锁头2)
互相都拿到了彼此想要往下执行的必需条件,互相都不放手里的锁头,这就造成了死锁
递归锁
递归锁在同一线程内可以被多次require
递归锁如何释放:内部相当于维护了一个计数器,也可以说是同一个线程,acquire了几次就要release几次
from threading import Thread,Lock,RLock
# mutex1 = Lock()
# mutex2 = Lock()
mutex1 = RLock()
mutex2 = mutex1
import time
class MyThreada(Thread):
def run(self):
self.task1()
self.task2()
def task1(self):
mutex1.acquire()
print(f'{self.name} 抢到了 锁1 ')
mutex2.acquire()
print(f'{self.name} 抢到了 锁2 ')
mutex2.release()
print(f'{self.name} 释放了 锁2 ')
mutex1.release()
print(f'{self.name} 释放了 锁1 ')
def task2(self):
mutex2.acquire()
print(f'{self.name} 抢到了 锁2 ')
time.sleep(1)
mutex1.acquire()
print(f'{self.name} 抢到了 锁1 ')
mutex1.release()
print(f'{self.name} 释放了 锁1 ')
mutex2.release()
print(f'{self.name} 释放了 锁2 ')
for i in range(3):
t = MyThreada()
t.start()
信号量Semaphore
同进程的一样
Semaphore管理一个内置的计数器,
每当调用acquire()时内置计数器-1;
调用release() 时内置计数器+1;
计数器不能小于0;当计数器为0时,acquire()将阻塞线程直到其他线程调用release()。
实例:(同时只有5个线程可以获得semaphore,即可以限制最大连接数为5):
from threading import Thread,currentThread,Semaphore
import time
def task():
sm.acquire()
print(f'{currentThread().name} 在执行')
time.sleep(3)
sm.release()
sm = Semaphore(5) # 同一时间只允许5个线程在执行
for i in range(15):
t = Thread(target=task)
t.start()
与进程池是完全不同的概念,进程池Pool(4),最大只能产生4个进程,而且从头到尾都只是这四个进程,不会产生新的,而信号量是产生一堆线程/进程。
GIl
介绍
'''
定义:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple
native threads from executing Python bytecodes at once. This lock is necessary mainly
because CPython’s memory management is not thread-safe. (However, since the GIL
exists, other features have grown to depend on the guarantees that it enforces.)
'''
# 1
在Cpython解释器中有一把GIL锁,GIl锁本质是一把互斥锁。
因为GIL锁:同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势
# 2
GIL本质就是一把互斥锁,那既然是互斥锁,原理都一样,都是让多个并发线程同一时间只能
有一个执行
即:有了GIL的存在,同一进程内的多个线程同一时刻只能有一个在运行,意味着在Cpython中
一个进程下的多个线程无法实现并行===》意味着无法利用多核优势
多个线程只能并发不能并行
# 3
GIL可以被比喻成执行权限,同一进程下的所以线程 要想执行都需要先抢执行权限。
首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。有名的编译器例如GCC,INTEL C++,Visual C++等。Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL
GIL介绍
GIL本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。
# 为何要有GIL?
因为Cpython解释器自带垃圾回收机制不是线程安全的。
# 如果不对垃圾回收机制线程做任何处理,也没有GIL锁行不行?
提示:如果是问题的这种情况,多线程和垃圾回收线程就会并发了。
可以肯定的一点是:保护不同的数据的安全,就应该加不同的锁。
要想了解GIL,首先确定一点:每次执行python程序,都会产生一个独立的进程。例如python test.py,python aaa.py,python bbb.py会产生3个不同的python进程
'''
#验证python test.py只会产生一个进程
#test.py内容
import os,time
print(os.getpid())
time.sleep(1000)
'''
python3 test.py
#在windows下
tasklist |findstr python
#在linux下
ps aux |grep python
在一个python的进程内,不仅有test.py的主线程或者由该主线程开启的其他线程,还有解释器开启的垃圾回收等解释器级别的线程,总之,所有线程都运行在这一个进程内,毫无疑问
#1 所有数据都是共享的,这其中,代码作为一种数据也是被所有线程共享的(test.py的所有代码以及Cpython解释器的所有代码)
例如:test.py定义一个函数work(代码内容如下图),在进程内所有线程都能访问到work的代码,于是我们可以开启三个线程然后target都指向该代码,能访问到意味着就是可以执行。
#2 所有线程的任务,都需要将任务的代码当做参数传给解释器的代码去执行,即所有的线程要想运行自己的任务,首先需要解决的是能够访问到解释器的代码。
综上:
如果多个线程的target=work,那么执行流程是
多个线程先访问到解释器的代码,即拿到执行权限,然后将target的代码交给解释器的代码去执行
解释器的代码是所有线程共享的,所以垃圾回收线程也可能访问到解释器的代码而去执行,这就导致了一个问题:对于同一个数据100,可能线程1执行x=100的同时,而垃圾回收执行的是回收100的操作,解决这种问题没有什么高明的方法,就是加锁处理,如下图的GIL,保证python解释器同一时间只能执行一个任务的代码
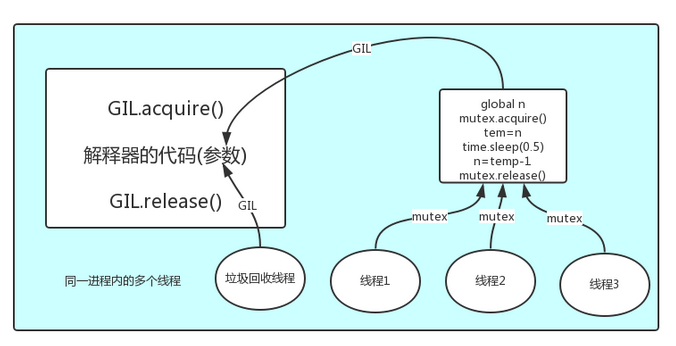
GIL与Lock
GIL保护的是解释器级的数据,保护用户自己的数据则需要自己加锁处理,如下图

