YOLO算法简单理解。
YOLO算法是将物体检测作为回归问题求解。基于一个单独的end-to-end网络,完成从原始图像的输入到物体位置和类别的输出。
在这里,我们并不先给出YOLO算法的逻辑结构图,我们先权且将其当作一个普通的神经网络即可。先从输出的角度开始逐步理解整个网络的思想和结构。
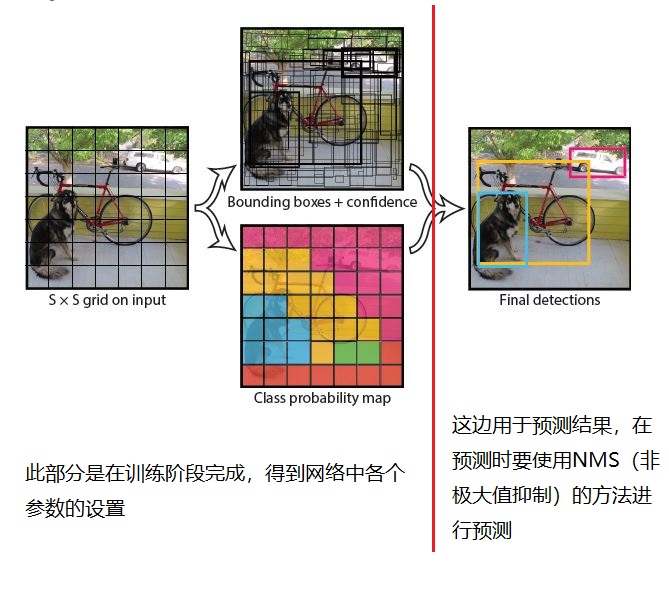
YOLO算法的输入是一张图片,在该算法执行过程中首先会将一张输入图片划分为S*S个grid cell。如下图所示

每个grid cell就负责检测“落入”该grid cell的物体。对于“落入”的定义是这样的,如果一个物体的中心位置的坐标在某个grid cell里面,那么就称该物体落入了这个grid cell里面,这个grid cell就要负责把这个物体检测出来。如果一个物体较大,其他的grid cell也包含了这个物体的一部分,但是并不包含这个物体的中心位置坐标,这就不算该物体落入了该grid cell。
那么这个物体的中心位置我们是怎么知道的呢?请注意,YOLO算法是属于监督式学习算法,我们在训练算法之前这些是要对这些输入图片进行标注的,图像中物体的类别以及位置信息(包含物体的方框的位置数据,就是x, y, w, h)我们都要进行正确标注,也就是我们的ground truth。如下图

在YOLO算法中将一张输入图片划分成了S*S个grid cell,每个grid cell都负责检测出中心落在它内部的物体。对于较大的物体,一个物体往往需要横跨几个grid cell。最理想情况下,预测时该grid cell能够直接预测生成一个与ground truth box完全重合的或者IOU接近于1的predicted box。但是算法并不是总能生成这样理想的predicted box。在算法中就设置生成为生成B个bounding box,并且为每个bounding box生成一个confidence scores。上篇博客中我们提到,定位一个物体需要四个参数x, y, w, h,这里同样使用这样的四个参数来表示每个predicted bounding box。再加上confidence scores,每个predicted box都要得到5个预测值。其中(x, y)代表了predicted box的中心位置相对于该grid cell边界的坐标,也就是偏移值,(w, h)代表了predicted box相对于整个输入图片的宽度和高度。confidence scores代表了predicted box 与ground truth box的交并比,表明了这个模型对于预测这个predicted box中包含物体的概率。在论文中定义 confidence scores为
confidence scores = Pr(Obj) * IOUtruthpred
注:
1.如果在该grid cell中并没有物体落入,那么Pr(Obj)就为0,如果有物体落入,就为1,此时cofidence scores就是predicted box 与ground truth box的交并比;
2.在上式中pred是IOU的下标,由于网页编辑器问题,暂且这么写
如下图

同时,每个grid cell也会预测输出C(C是识别的类别数)个条件概率值,Pr(Classi|Object),这些概率值是在检测到物体的条件下的概率值,与我们的Bounding box数量无关。这个式子的含义使在检测到该grid cell中检测到物体的条件下,检测到的物体属于第i个类别的概率值。如下图
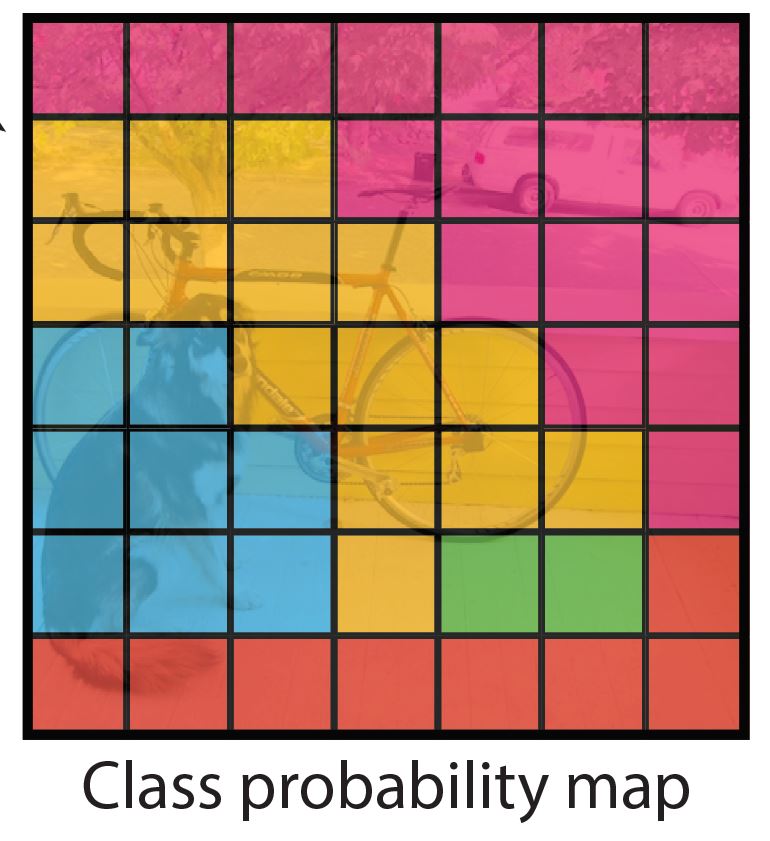
在测试时间,我们将每个grid cell的条件概率值与每个predicted box的confidence prediction相乘,如下式
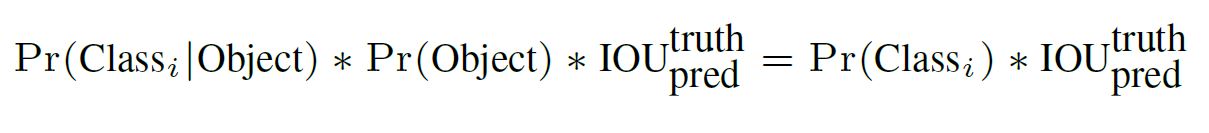
前面我们说到,confidence scores代表了predicted box 与ground truth box的交并比,这个模型对于grid cell预测产生了B个bounding box,confidence scores表示预测产生的predicted box中包含物体的概率。也就是每个模型对于每个grid cell都预测产生了B个bounding box,而每个bounding box都有概率包含物体,而confidence scores就是表示这个概率值的大小。
而Pr(Classi|Object)是使在检测到该grid cell中检测到物体的条件下,检测到的物体属于第i个类别的概率值。
两者相乘,就得到了每个predicted box关于特定类别的物体的confidence scores,就是模型对于每个grid cell预测产生了B个bounding box,这个乘积结果就是每个bounding box中的物体(如果有的话)属于某个类别的概率值。这个分数就表明了出现在这个box里面的某个类别物体的概率值以及这个box预测这个物体的优良与否。
综上所述,由于把输入图片分成了S*S个grid cell, 每个grid cell 生成B个prdicted bounding box和C个条件概率值Pr(Classi|Object),而每个predicted bounding box生成x, y, w, h和confidence scores五个数据,所以输出维度最终是S*S( B * 5 + C)。
在文章原文中写道,YOLO predicts multiple bounding boxes per grid cell. At trainning time we only want one bounding box predictor tobe responible for each object. we assign one predictorto be “responsible” for predicting an object based on which prediction has the highest current IOU with the ground truth. This leads to specialization between the bounding box predictors. Each predictor gets better at predicting certain sizes, aspect ratios, or classes of object, improving overall recall.
也就是说,每个grid cell会预测生成B个bounding box,但是算法只会选择与ground truth 具有最高的交并比的那个bounding box来负责物体检测输出。同时,这样的算法的结果就是一个grid cell只能检测出一个物体。但是当物体在图像中较小而导致一个grid cell中含有多个物体时,只能检测出其中一个。
损失函数
在本算法中使用sum-squared error来作为损失函数进行模型的优化。这个损失函数的有点是比较容易优化,但是也存在如下缺点
1.这个函数并不与我们实现最大平均精度的目标完全一致
2.这个损失函数会增加局部误差与分类误差的权重,但这并不是理想的结果
3.在每个图像中,这个损失函数会把那些不包含物体的网格的confidence scores趋向于零,这样会导致这些不包含物体的grid cell的梯度超过包含物体的grid cell的梯度,这样会导致模型不稳定,在训练早期就出现分歧。
为了修正损失函数的上述缺点,我们增加每个grid cell的predictor的坐标预测的损失值并减少不包含物体的grid cell的confidence scores的损失值。我们引入两个参数λcoord, λnoobj。在文中,λcoord = 5, λnoobj = 0.5。
同时应该知道,对于相等的误差值,大物体误差对检测的影响应小于小物体误差对检测的影响。这是因为,相同的位置偏差占大物体的比例远小于同等偏差占小物体的比例。YOLO将物体大小的信息项(w和h)进行求平方根来改进这个问题。
同时,鉴于前面的分析,我们可以知道,一个yolo算法的输出由三个方面构成,1.坐标(x, y, w, h)2, confidence scores(当有物体时就是IOU), 3.分类。那么在损失函数也由这三部分组成,1.坐标误差 coordError, 2.交并比误差iouError, 3.分类误差classError。那么损失函数可以如下式

经过分析后,损失函数的理解如下所示
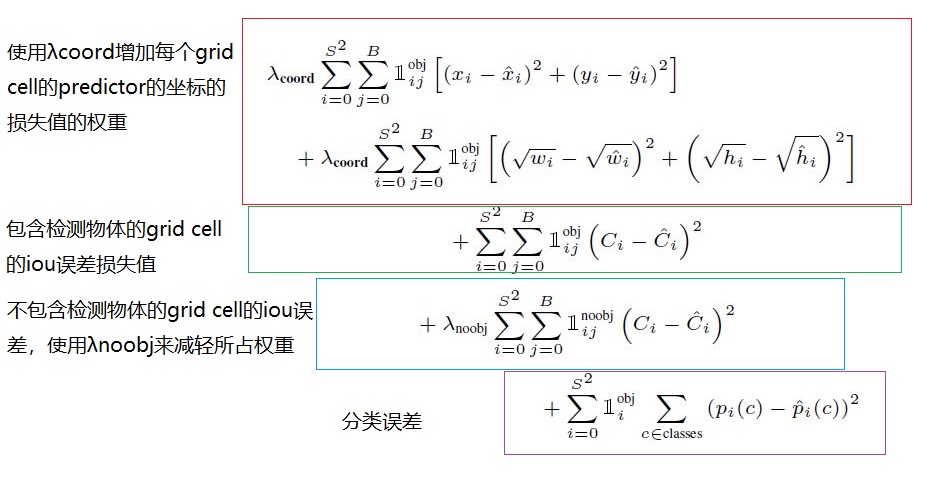
式中的![]() 表示第i个grid cell中包含物体,
表示第i个grid cell中包含物体,![]() 表示在第i个grid cell中包含物体并且第j个bounding box是第交并比最大并且负责该gird cell检测物体的predictor。
表示在第i个grid cell中包含物体并且第j个bounding box是第交并比最大并且负责该gird cell检测物体的predictor。
值得注意的是,对于分类误差,损失函数只计算了包含物体的grid cell的分类误差,对于坐标误差,也只是计算了包含物体的grid cell中具有最高交并比的那个bounding box的坐标误差。
详细介绍完了YOLO.v1算法的各个部分,我们就简单介绍一下算法的整个逻辑结构图
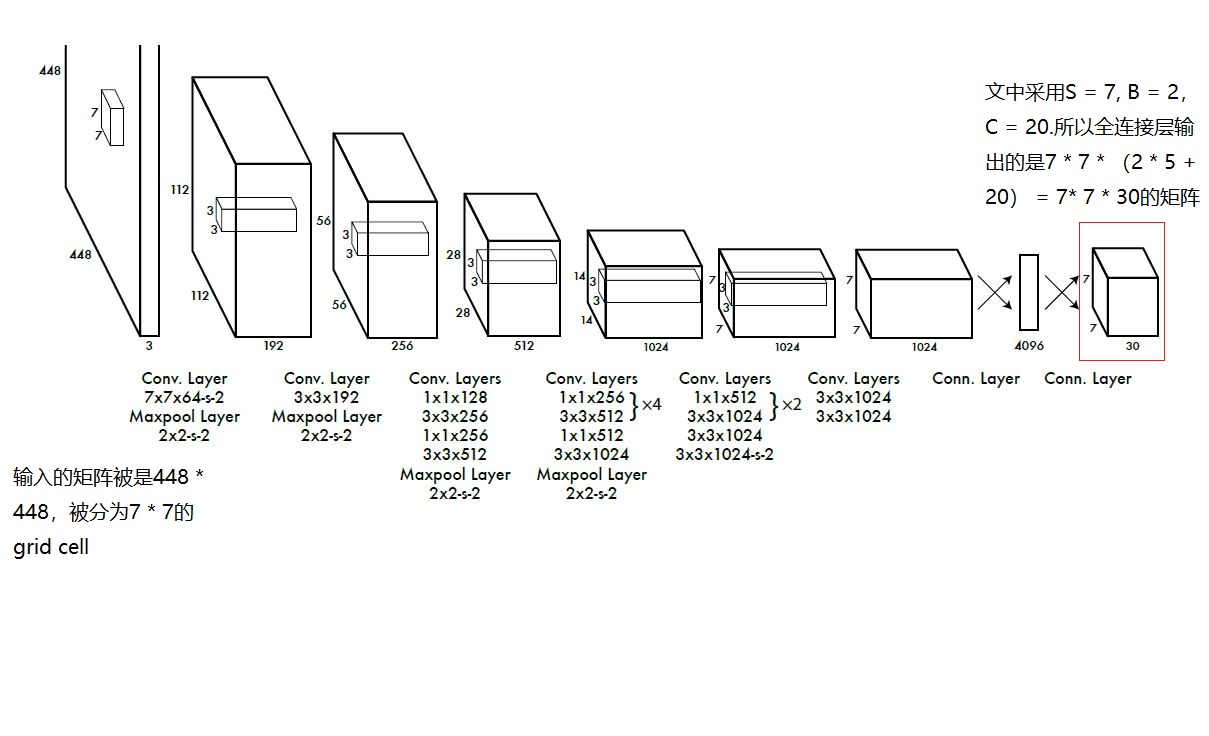
在模型的训练时,训练主要分为两步,预训练和训练
1)预训练。使用ImageNet 1000类数据训练YOLO网络的前20个卷积层+1个average池化层+1个全连接层。训练图像分辨率resize到224x224。
2)用步骤1)得到的前20个卷积层网络参数来初始化YOLO模型前20个卷积层的网络参数,然后用VOC 20类标注数据进行YOLO模型训练。为提高图像精度,在训练检测模型时,将输入图像分辨率resize到448x448。
关于学习率的设置
如果一开始就将学习率设置的很大,很容易由于模型中不稳定的梯度造成模型发散,所以前75个epochs中设置学习率为0.01,在接下来的30个epochs中设置学习率为0.001,在最后的30个epochs中设置学习率为0.0001.
避免过拟合的措施
在文中采用了随机失活(dropout)和加大数据量的方式来避免模型的过拟合。