一、完善球赛程序,测试球赛程序所有函数的结果。
from random import random def printIntro(): print("这个程序模拟两支排球队A和B的排球比赛") print("程序运行需要A和B的能力值(以0到1之间的小数表示)") def getInputs(): a=eval(input("请输入队伍A的能力值(0~1):")) b=eval(input("请输入队伍B的能力值(0~1):")) n=eval(input("模拟比赛的场次:")) return a,b,n def simNGames(n,probA,probB): winsA,winsB=0,0 for i in range(n): scoreA,scoreB=simOneGame(probA,probB) if scoreA>scoreB: winsA +=1 else: winsB +=1 return winsA,winsB def gameOver(a,b): if (a>=25 and abs(a-b)>=2 )or(b>=25 and abs(a-b)>=2): return True if (a>=15 and abs(a-b)>=2 )or(b>=15 and abs(a-b)>=2): return True return False def simOneGame(probA,probB): scoreA,scoreB=0,0 serving = "A" while not gameOver(scoreA,scoreB): if serving =="A": if random()<probA: scoreA +=1 else: serving="B" else: if random()<probB: scoreB +=1 else: serving="A" return scoreA,scoreB def final(probA,probB): winsA,winsB=simNGames1(4,probA,probB) printSummary(winsA,winsB) if not winsA==3 or winsB==3: if winsA==winsB==2: winsA1,winsB1=simOneGame1(probA,probB) finalprintSummary(winsA,winsB) else: finalprintSummary(winsA,winsB) def simNGames1(n,probA,probB): winsA,winsB=0,0 for i in range(n): scoreA,scoreB=simOneGame2(probA,probB) if winsA==3 or winsB==3: break if scoreA>scoreB: winsA+=1 else: winsB+=1 return winsA,winsB def simOneGame2(probA,probB): scoreA,scoreB=0,0 serving="A" while not GG(scoreA,scoreB): if serving=="A": if random() < probA: scoreA += 1 else: serving="B" else: if random() < probB: scoreB += 1 else: serving="A" return scoreA,scoreB def simOneGame1(probA,probB): scoreA,scoreB=0,0 serving="A" while not finalGameOver(scoreA,scoreB): if serving=="A": if random() < probA: scoreA += 1 else: serving="B" else: if random() < probB: scoreB += 1 else: serving="A" return scoreA,scoreB def GG(a,b): return a==3 or b==3 def finalGameOver(a,b): if (a==8 or b==8): if a>b: print("A队获得8分,双方交换场地") else: print("B队获得8分,双方交换场地") if (scoreA>15 and abs(scoreA-scoreB)>=2 )or(scoreB>15 and abs(scoreA-scoreB)>=2): return True else: return False def finalprintSummary(winsA,winsB): n=winsA+winsB if n>=4: print("进行最终决赛") if winsA>winsB: print("最终决赛由A获胜") else: print("最终决赛由B获胜") else: if winsA>winsB: print("最终决赛由A获胜") else: print("最终决赛由B获胜") def printSummary(winsA,winsB): n=winsA+winsB print("竞技分析开始,共模拟{}场比赛".format(n)) print("选手A获胜{}场比赛,占比{:0.1%}".format(winsA,winsA/n)) print("选手B获胜{}场比赛,占比{:0.1%}".format(winsB,winsB/n)) def main(): printIntro() probA,probB,n=getInputs() winsA,winsB=simNGames(n,probA,probB) printSummary(winsA,winsB) final(probA,probB) try: main() except: print("Error")
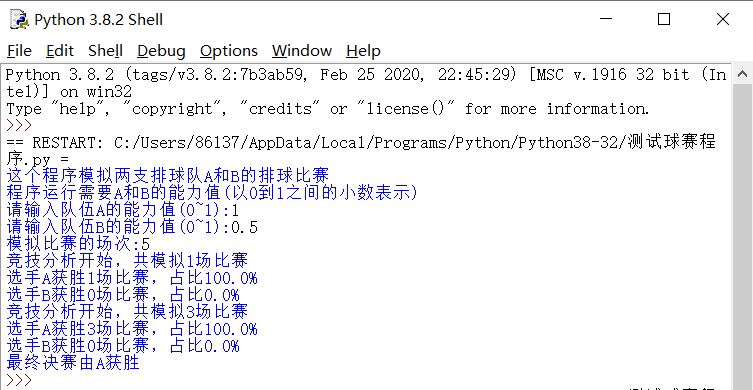
代码执行效果:

二、用requests库的get()函数访问搜狗主页
(一)简介:requests库是一个简洁且简单的处理HTTP请求的第三方库。
get()是对应与HTTP的GET方式,获取网页的最常用方法,可以增加timeout=n 参数,设定每次请求超时时间为n秒
text()是HTTP相应内容的字符串形式,即url对应的网页内容
content()是HTTP相应内容的二进制形式
(二)用requests()打开搜狗20次,并打印返回状态、text()内容、、计算text()属性和content()属性所返回网页内容的长度。
from requests import * try: for i in range(20): r=get("https://www.sogou.com/") r.raise_for_status() r.encoding='utf-8' print(r) print(len(r.text)) print(len(r.content)) except: print("Error")
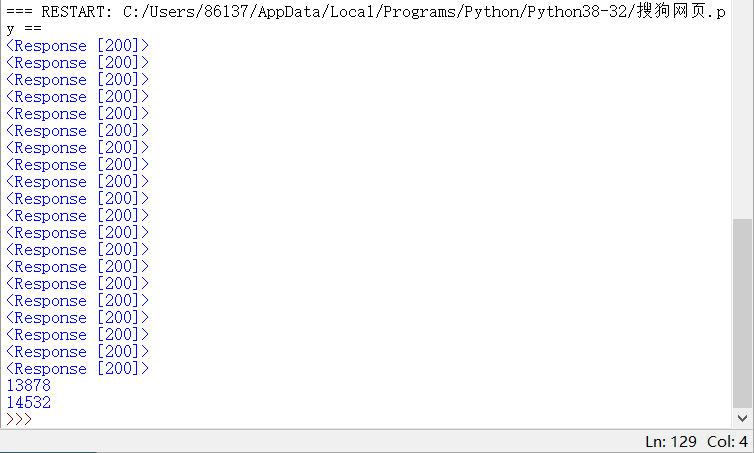
代码执行效果:
三、用 Beautifulsoup4 库提取网页源代码中的有效信息
(一)下面是本次操作所访问的网页源代码:
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</title> </head> <body> <hl>我的第一个标题</hl> <p id="first">我的第一个段落。</p> </body> <table border="1"> <tr> <td>row 1, cell 1</td> <td>row 1, cell 2</td> </tr> <tr> <td>row 2, cell 1</td> <td>row 2, cell 2</td> <tr> </table> </html>
(二)获取网页各个属性的代码如下
# -*- encoding:utf-8 -*- from requests import get def getText(url): try: r = get(url, timeout=5) r.raise_for_status() r.encoding = 'utf-8' return r.text except Exception as e: print("Error:", e) return '' from bs4 import BeautifulSoup url = "http://www.runoob.com/" html = getText(url) soup = BeautifulSoup(html) #获取head标签 print("head:", soup.head) print("head:", len(soup.head)) print("学号后两位:24") #获取body标签 print("body:", soup.body) print("body:", len(soup.body)) #获取title标签 print("title:", soup.title) #获取title内容 print("title_string:", soup.title.string) #获取特定id的内容 print("special_id", soup.find(id='cd-login'))
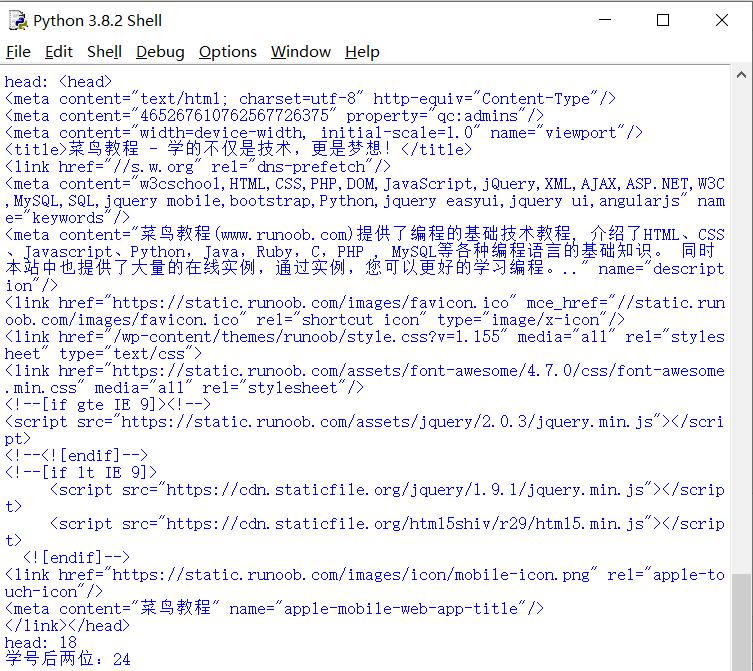
(三)代码执行效果:
a.打印head标签内容和学号后两位
b.获取body标签的内容

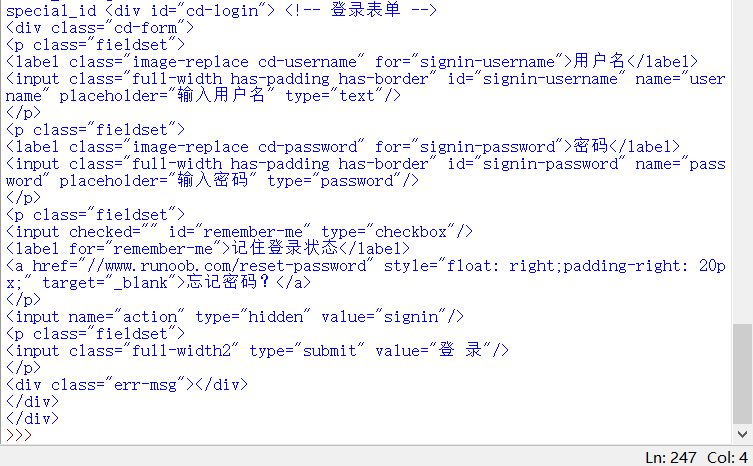
c.获取id
d.获取并打印html页面的中文字符
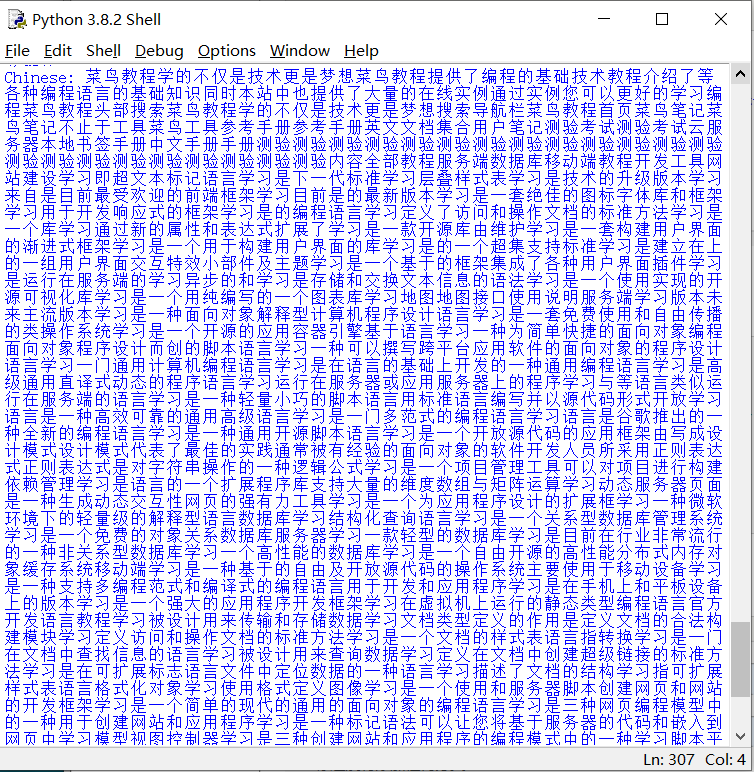
import re def getChinese(text): text_unicode = text.strip() # 将字符串进行处理, 包括转化为unicode string = re.compile('[^u4e00-u9fff]') chinese = "".join(string.split(text_unicode)) return chinese print("Chinese:",getChinese(html))
代码执行效果:
四、爬取中国大学排名(2016)网站内容
import requests from bs4 import BeautifulSoup allUniv = [] def getHTMLText(url): try: r=requests.get(url,timeout=30) r.raise_for_status() r.encoding='utf-8' return r.text except: return"" def fillUniVList(soup): data=soup.find_all('tr') for tr in data: ltd = tr.find_all('td') if len(ltd)==0: continue singleUniv = [] for td in ltd: singleUniv.append(td.string) allUniv.append(singleUniv) def printUnivList(num): print("{1:^4}{2:{0}^10}{3:{0}^5}{4:{0}^8}{5:{0}^10}".format(chr(12288),"排名","学校名称","省市","总分","培养规模")) for i in range(num): u=allUniv[i] print("{1:^4}{2:{0}^10}{3:{0}^5}{4:{0}^8}{5:{0}^10}".format(chr(12288),u[0],u[1],u[2],u[3],u[6])) def main(num): url = "http://www.zuihaodaxue.cn/zuihaodaxuepaiming2016.html" html = getHTMLText(url) soup = BeautifulSoup(html,"html.parser") fillUniVList(soup) printUnivList(num) main(10)
代码执行效果:
