一、分析《三国演义》,得到词频统计,并对词频进行排序。
(一)具体代码如下:
1 #CalThreeKingdomsV2.py 2 import jieba 3 excludes = {"将军","却说","荆州","二人","不可","不能","如此"} 4 txt = open("threekingdoms.txt", "r", encoding='utf-8').read() 5 words = jieba.lcut(txt) 6 counts = {} 7 for word in words: 8 if len(word) == 1: 9 continue 10 elif word == "诸葛亮" or word == "孔明曰": 11 rword = "孔明" 12 elif word == "关公" or word == "云长": 13 rword = "关羽" 14 elif word == "玄德" or word == "玄德曰": 15 rword = "刘备" 16 elif word == "孟德" or word == "丞相": 17 rword = "曹操" 18 else: 19 rword = word 20 counts[rword] = counts.get(rword,0) + 1 21 for word in excludes: 22 del counts[word] 23 items = list(counts.items()) 24 items.sort(key=lambda x:x[1],reverse=True) 25 for i in range(10): 26 word, count = items[i] 27 print("{0:<10}{1:>5}".format(word, count))
(二)程序运行效果如下:
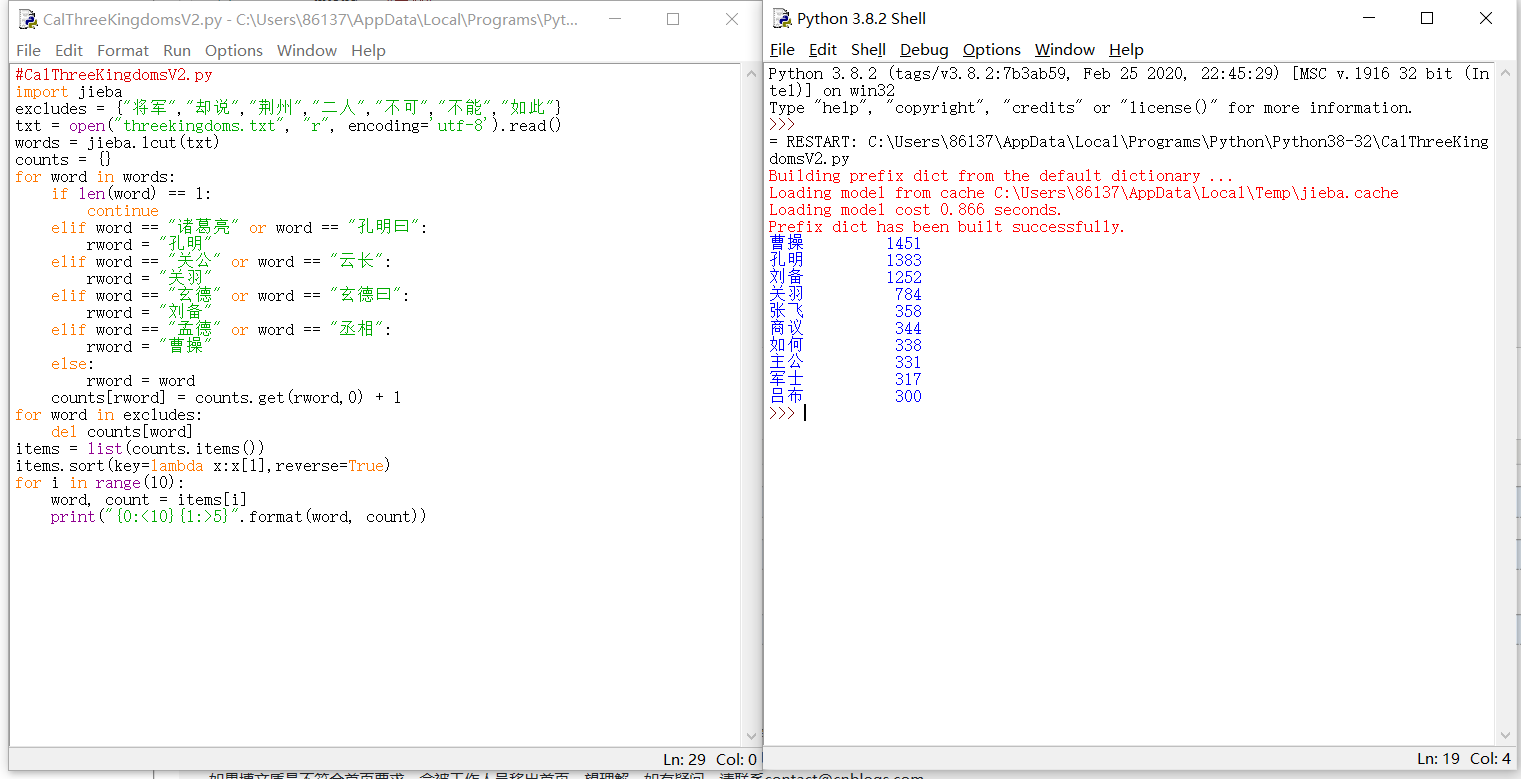
二、对以上关键词制作一个词云图
(一)具体代码如下:
1 #GovRptWordCloudv2.py 2 import jieba 3 import wordcloud 4 import imageio 5 mask = imageio.imread("chinamap.png") 6 excludes = { } 7 f = open("threekingdoms.txt",encoding="utf-8") 8 9 t = f.read() 10 f.close() 11 ls = jieba.lcut(t) 12 13 txt = " ".join(ls) 14 w = wordcloud.WordCloud(width = 1000, height = 700, background_color = "white", font_path = "msyh.ttc") 15 w.generate(txt) 16 w.to_file("grwordclouds.png")
(二)程序运行效果如下:
