1.先建立一台虚拟机,分配内存2G,硬盘20G,网络为nat 模式,设置一个静态的ip 地址: 例如设定3台机器的ip 为 192.168.63.167(master) 192.16863.168(slave1) 192.168.63.169 (slave2)
2.修改第一台主机的用户名
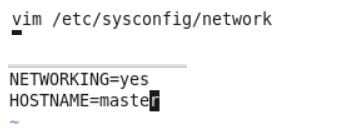
3.复制master文件两次,重命名为slave1和slave2,打开虚拟机文件,然后按照同样的方法设置两个节点的ip和主机名

4.建立主机名和ip的映射
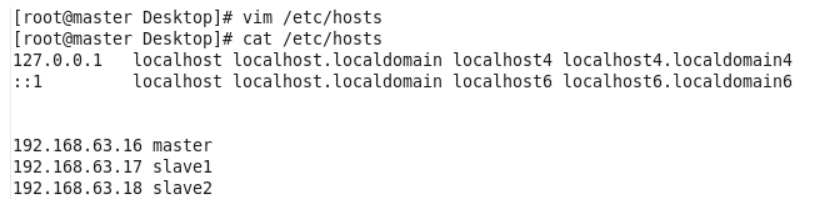
5.查看是否能ping通,关闭防火墙和selinux 配置
6.配置ssh免密码登录
在root用户下输入ssh-keygen -t rsa 一路回车

秘钥生成后在~/.ssh/目录下,有两个文件id_rsa(私钥)和id_rsa.pub(公钥),将公钥复制到authorized_keys并赋予authorized_keys600权限
同理在slave1和slave2节点上进行相同的操作,然后将公钥复制到master节点上的authoized_keys
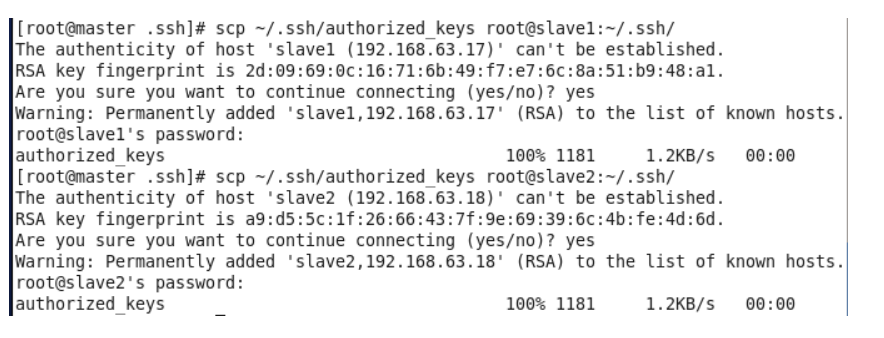
检查是否免密登录(第一次登录会有提示)
7..安装JDK(省去)
三个节点安装java并配置java环境变量
8.安装MySQL(master 节点 省去)
9.安装SecureCRT或者xshell 客户端工具 ,然后分别链接上 3台服务器
12.搭建集群
12.1 集群结构
三个结点:一个主节点master两个从节点 内存2GB 磁盘20GB
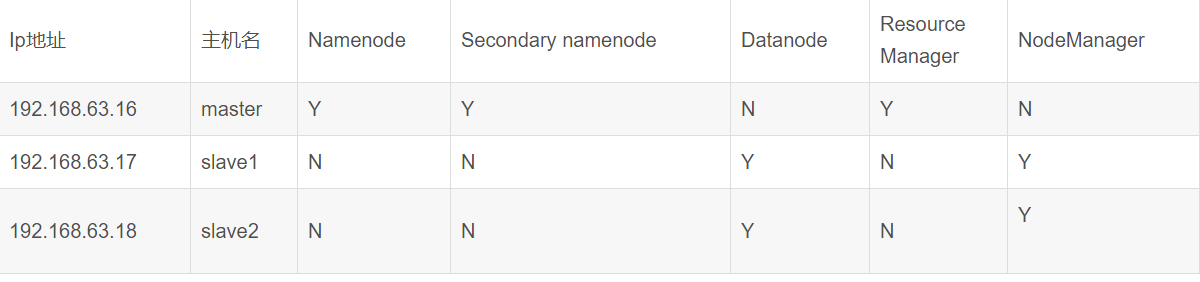
12.2 新建hadoop用户及其用户组
用adduser新建用户并设置密码
将新建的hadoop用户添加到hadoop用户组
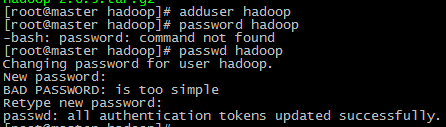
前面hadoop指的是用户组名,后一个指的是用户名

赋予hadoop用户root权限


12.3 安装hadoop并配置环境变量
由于hadoop集群需要在每一个节点上进行相同的配置,因此先在master节点上配置,然后再复制到其他节点上即可。
将hadoop包放在/usr/目录下并解压

配置环境变量
在/etc/profile文件中添加如下命令
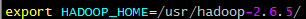
12.4 搭建集群的准备工作
在master节点上创建以下文件夹
/usr/hadoop-2.6.5/dfs/name
/usr/hadoop-2.6.5/dfs/data
/usr/hadoop-2.6.5/temp
12.5 配置hadoop文件
接下来配置/usr/hadoop-2.6.5/etc//hadoop/目录下的七个文件
slaves core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml hadoop-env.sh yarn-env.sh
配置hadoop-env.sh

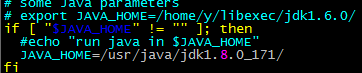
配置yarn-env.sh
配置slaves文件,删除localhost

配置core-site.xml
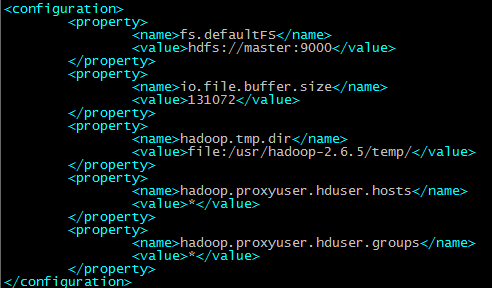
配置hdfs-site.xml
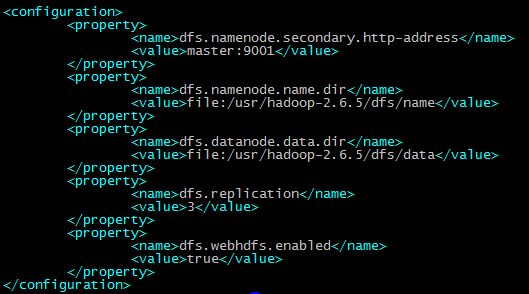
配置mapred-site.xml
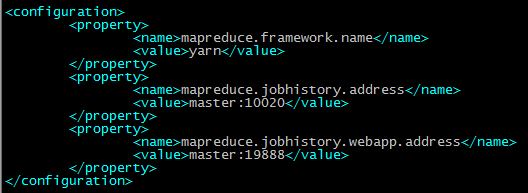
配置yarn-site.xml
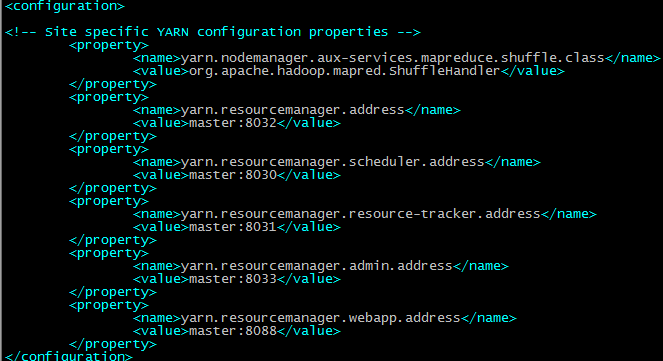
将配置好的hadoop文件复制到其他节点上
12.6 运行hadoop
格式化Namenode

source /etc/profile

13. 启动集群
[root@master sbin]# ./start-all.sh
原文链接:https://blog.csdn.net/code__online/article/details/80178032