(一)基于度量的程序结构分析
先上前两次作业的类图和复杂度分析
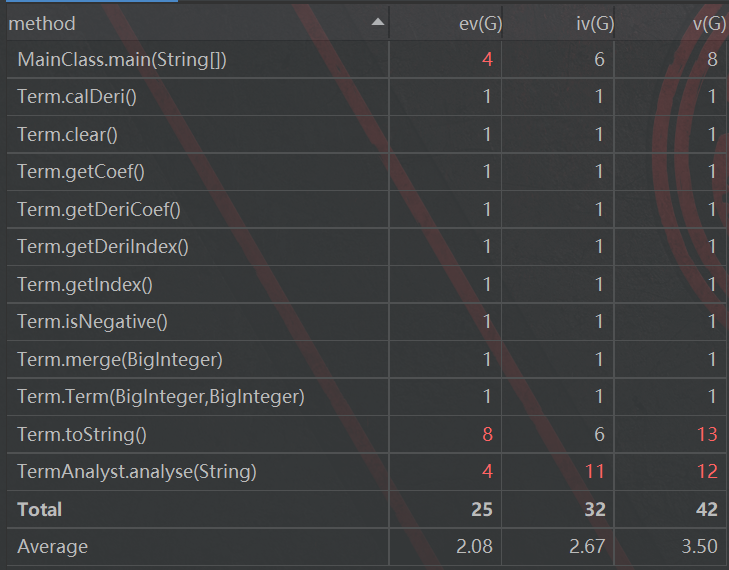


第一二次作业结构均比较简单,我的设计最小颗粒度也都是Term,所以DIT均为0
缺点:我的解析字符串部分复杂度都相当高,主要是算法设计不够优化。
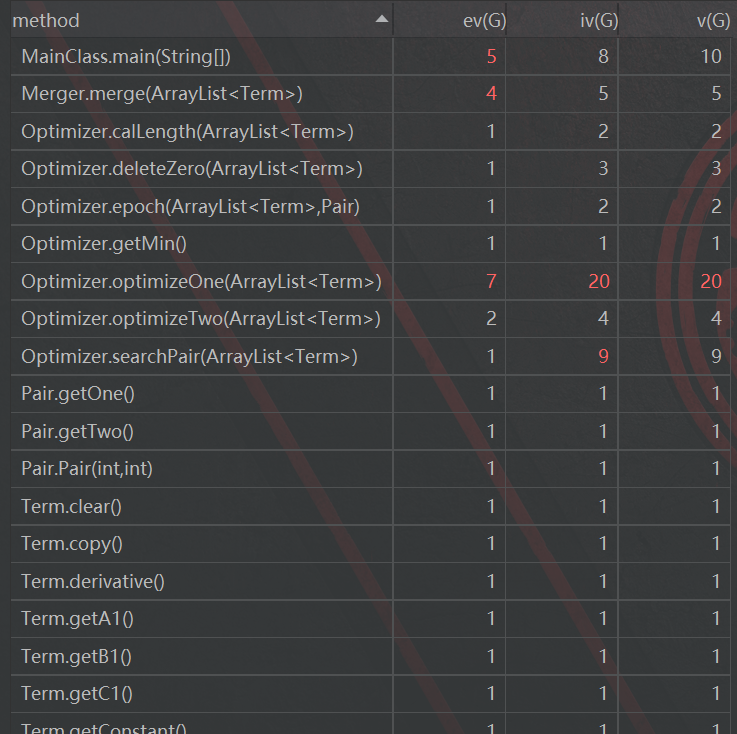
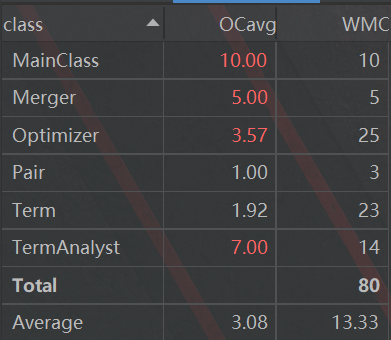
主要是对第三次作作业进行分析

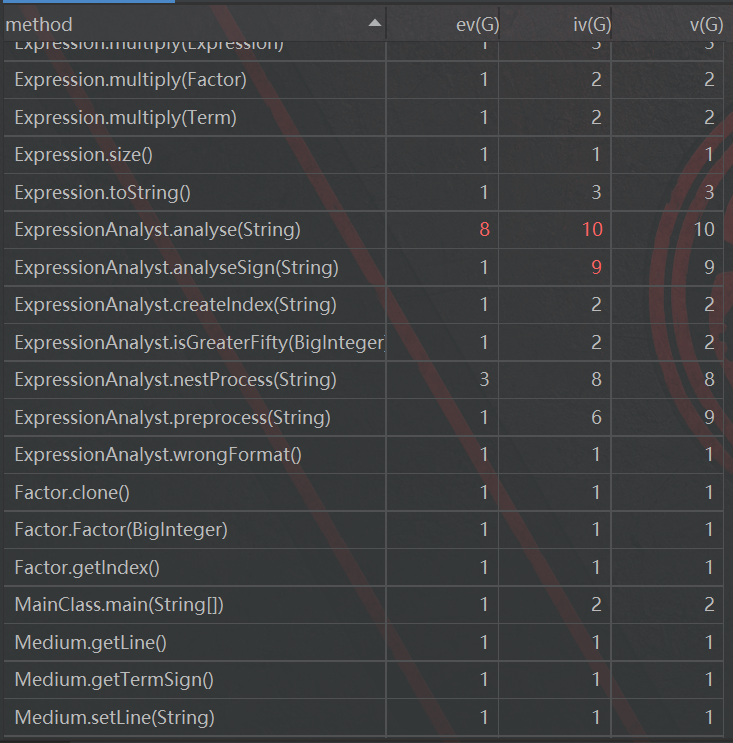
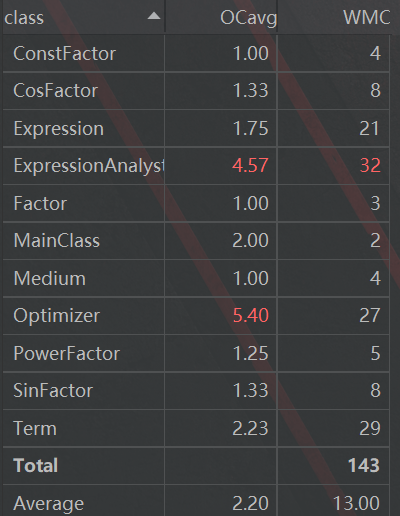
优点:实现了Expression、Term和Factor三级结构已经对各个类之间add multiply方法的部署
缺点:按照老师的说法,第三次作业的类图根本不具有可读性,但是我还是放了这张图,因为这张图恰恰反映出了我设计中的一个缺陷:类图中有大量标注为”create”的白线,表明我的类中大量方法都需要重建Term或者Factor类,提高了算法的时间复杂度(具体分析请看第二节)
此外,ExpressionAnalyst那个类复杂度过高,主要原因是我的解析字符串部分算法过于复杂,而且几个方法相互调用增加了复杂度。这次因为实现了各种因子从Factor抽象类的继承,所以DIT为1,
两个小小的困惑:
1 课件中老师提到不需要的类 (unnecessary abstraction UA)即一个类中只有数据没有方法类似于c语言中的结构体,但是我在第二次第三次作业中都用到了,分别为Pair和Medium,主要用来传递函数的返回值,因为Java中没有类似于Python的自动装包解包功能,所以函数需要传递多个返回值的时候似乎这是必要的方法,不知道Java有没有提供别的更好的方法。
2 课件中老师提到命令式的类(Imperative Abstraction IA)只提供public的方法,而没有数据方面的封装。但是此次作业其实含有大量过程,比方说优化,因而我选择新建一个Optimizer类单独实现优化算法,这看起来是达到了合理划分程序的目的,应该来讲是不错的,就是不知道这样的类有什么问题
(二)自己程序的bug
第一次作业:
公测与互测均未发现bug
第二次作业:
公测出现2个bug,互测未发现
第一个bug是在MainClass中将 x**2 优化成 x*x 时,直接将 x**2 替换了,导致诸如 x**23 会变成 x*x3 这样的情况。
原因分析:个人觉得这个bug很难讲是设计上的问题,并且也不符合二八原则,这个bug出现的位置并非是代码结构逻辑最复杂的部分,相反我只是简单的在输出最终结果之前使用了replaceAll方法。因为将x**2优化成x*x不是一个系统性的优化,纯属是我们对于性能的定义和表达式表达方法两方面结合的一个偶然结果,如果我们让表达式中的幂表示为^而非**,那么这个优化实际上就不存在了。我将这个bug的原因归结于时间或者是测试上的问题,这个优化一开始并不在我考虑之列因为实际优化效果有限,在周六晚上九点多的时候我才想起来这个地方还可以勉强提升一下下性能分,修改的时候没有考虑清楚字符串替换的后果并且没有进行充分的测试就提交了,事后我仔细检查了手工的测试集,由于幂指数不为1被我归结为一般情况,我的测试集中没有出现x**24这样的数据导致了测试的不完全从而导致了bug。从中有几点可以反思,一方面要抓紧时间写作业,尽早完成开始测试否则ddl来临之前脑子容易短路,一方面第二次作业的时候没有应用自动测评系统只是使用了纯手工的测试集,很有可能测试集本身存在瑕疵,毕竟x**2XXX的数据很容易被人误认为是一般数据而非特别数据。此外,虽然replaceAll是可以完成x**2到x*x的优化的,但是如果能在toString方法内完成优化,我觉得是在设计上更优的选择,因为逻辑更为通顺封装性也更好不至于需要在MainClass中调用replaceAll。
第二个bug是有一个强测测试样例中出现了垂直制表符从而应该输出WRONG FORMAT但是我因为使用了s从而误识别为合法表达式。
原因分析:在使用s的时候其实我是非常清楚\s代表了包括空格、水平制表符、垂直制表符在内的若干种空格的,之所以我依然使用了第一次代码中的s在于我清楚的记得第一次作业中明确说明不会出现除了空格和 以外的空格,换言之不会在空格上出现非法字符集,结果我误以为第二次的指导书也有类似的说明,后来强测完之后仔细翻阅指导书确实没有类似的说明,从而导致了错误。反思来说,确实是自己阅读指导书不够细致,尤其是对于指导书迭代之后前后的差异没有仔细地校对,之后的作业已经进行了改进。
第三次作业:
公测出现2个bug,互测出现22个bug但是与公测两个bug是同质的,因而仅分析公测出现的bug。
第一个bug是对诸如 cos((Expression)),如果Expression仅包含一个因子的时候可以去括号优化。但是我对于 cos(-x) 误认为也是单因子从而也去掉了括号导致输出WRONG FORMAT。
原因分析:我的括号优化是在toString也就是在输出阶段进行的,总体而言那个区域复杂度并不高,出现问题直接原因cos(-x)非法与人的直觉是相反的,当时编程状态不佳脑子出现了错觉。但是根本原因在于自动测试系统的缺陷,针对第三次作业我使用了自动测评机自动生成数据并且对输出结果进行检验。问题在于作业的要求是符合表达式规范并且sympy检查结果合格,而我的测评机仅对结果的数值方面进行了检验而没有对是否符合表达式规范进行检验,从而对于cos (-x)这样的数据,因为sympy是可以计算cos(-x)的所以对于WF的输出依然判对,正确的做法应该是对于输出结果再次调用合法性检查并且捕捉异常,如果有WF直接判错。
第二个bug是强测中一个检查时间复杂度的样例,因为十层嵌套出现了tle。
原因分析:这是一个显然的设计失误导致的bug。首先从作业一开始我就没有关心过程序的时间复杂度,因为输入样例只有60(之前是50)个字符,估算了一下sin(x)就长达6个字符,60个字符存在的项数极少,应该不会出现tle的状况,但是忽略了极端数据的存在。其次是我类中具体方法的失误,对于Expression和Term两个类,我都设计了全套的add或multiply方法,对应数学意义上的加与乘,但是为了规避可能出现的深浅复制的问题,我将Expression和Term类设计成实际上“不可变的”,就如同String一样,每次String修改时,都要重新创建一个新的String,每次调用add或multiply方法时,照理讲只用在Expression或Term内含的那个ArrayList增加一个元素即可,但是我选择了将ArrayList里面的东西全部复制到一个新的ArrayList里面。层层嵌套导致求导的结果较为复杂,从而当调用derivative()方法时,反复的add与multiply都需要进行新建ArrayList,从而时间复杂度过大。但是作业的总体结构是没有问题的,因而修改主要是降低add与multiply方法的复杂度。
总结:
本单元三次作业出现了4个bug,其中前3个我认为都属于细节问题,与帕累托原则也不符,可以通过细致的测试避免的,不过由于拖延症没有最终避免bug的产生。最后一个tle错误,绝对是设计失误的典型,尤其是我对程序时间复杂度没有加以控制,这是非常值得反思的一点。此外从输入的角度而言,对于特殊数据如x**2XXXX、边界数据cos(-x)和极端数据多层嵌套考虑不周。
(三)自己发现别人程序bug所采用的策略
第一次作业由于题目简单我们屋没有被发现任何bug,第二次作业也仅发现了少量bug,从而主要对第三次作业hack别人做详尽分析。
我采用的是自动测评+手工测试集联合hack策略。测试之前需要对被测代码输入输出进行改造,从而使其适应自动化测评。
自动化测评主要需要考察其效率并且尽可能提高覆盖率。效率方面第三次作业可以达到1000个表达式每小时,但是CPU占用率百分之百此时电脑无法做任何事情,最好能利用一夜的时间放在那跑。
现在来看,我的自动化测评有四个缺陷,第一个缺陷上文已经提到就是没有对输出进行合法化检查从而极有可能漏hack一些同学的代码,第二个缺陷就是每次自动测评只能对一份代码进行检查,从而导致每次调用python脚本生成一个随机数据,这个数据检查一份代码之后即被丢弃,从而导致检查7份代码需要随机生成7份数据,在效率方面很不优。第三个缺陷在于我没有及时修改随机生成数据的参数,因为互测时对于数据的要求更为严格比方说指数不能为负等等,因为没有及时修正导致了非法数据的出现。第四个缺陷在于没来得及为自动测评机添加输出WRONG FORMAT数据的功能,虽然这一次没有因此出现问题,但是确实是测试集上的不完备。
而手工测试集的出现是为了弥补自动测评的一些先天不足,经过和同学们的广泛讨论,我手工搜集、构造了一些自动测评很难产生的数据。第一方面是TLE相关的测试集,主要有如下:
sin(sin(sin(sin(sin(sin(sin(sin(sin(sin(sin(x*x)))))))))))
长度正好60,用来检查多成表达式嵌套可能导致的TLE
sin((x+cos((x+sin((x+cos((x+sin((x+cos((x+cos(x)))))))))))))
长度正好60,由于算法的差异,部分代码在此测试集上会TLE
-(((((((((((((((((((((((((((((x)))))))))))))))))))))))))))))
长度正好60,用来检查多层嵌套可能导致的TLE
第二部分同学沿用了第二次作业将x**2优化成x*x的算法,在第三次作业中可能会出现一个问题,x**2是因子而x*x是表达式,因而在sin(x**2)中如果将x**2替换为x*x就会WRONG FORMAT,针对此我也手工构造了一个测试样例
关于是否结合代码结构:结合。总的来讲第一二次作业我仔细读过同学们的代码试图发现bug,但是未果,不过学到了很多有用的知识是真的(比方说BigInteger类中有一个BigInteger.One表示值为1的BigInteger可以使得很多写法变得简洁明了)第三次作业,有一个经验就是,做了大量优化的同学更容易出现TLE问题,而写法更加面向过程的同学则容易在细节上出现失误,此时需要用自动测评大量样例暴力hack
(四)应用对象创建模式
关于对象创建模式,由于前两次作业我的设计颗粒度都是Term(项),并且根据题目要求,Term的形态都是统一的,应用对象设计模式的意义不大。但是第三次作业,我的表达式解析那一方法复杂度尤为高,现在想来,在那个方法应用简单工厂模式非常有意义,因为有常数、幂、正弦和余弦四种因子,简单工厂模式可以大幅度降低代码的复杂度,还可以免受方法最多60行的困扰。
重构的具体说明:
首先设计简单工厂模式,通过输入的字符串来分析创建哪种factor并且返回。
将表达式解析的analyse方法中,(此方法极为复杂长度勉强压缩到60行),当预处理完成之后,再捕捉到到因子字符串的时候,直接送入工厂类中进行构造而不是像现在将解析因子种类、幂指数的值的工作放在analyse方法中。
(五)对比与心得体会
对比:
我的代码缺陷在于对于字符串的分析极为繁琐,没有好好划分分析所需各个方法的功能。此外的话,其实我觉得他们很多很优秀的地方我也做到了,比方说Expression、Term和Factor三级结构,解析与求导与优化分离,字符串进行预处理,求导返回的是Expression扩展性较强。不过有一点就是关于表达式树,我这次采用的是ArrayList容器,因为考虑到这次的运算只有add与multiply两种,利用容器元素之间的默认关系即可表达,但是如果加上除法那么ArrayList就不够用了,最好使用二叉树结构,所以我的代码在表达式操作的扩展性不强。
心得体会:
(具体技术性的东西之前都说过啦)
OO作业的工作量很大,所以需要:
1 保持良好的心态与合理的作息,才能保证长时间的高效coding
2 多与同学交流 可以发现新思想新方法
3 不断学习,有很多地方现在想想当初实现的效率都有巨大的缺陷,浪费了很多时间
最后,老师您要是看到了的话能不能回答一下那两个小问题呢 谢谢!