1,下载Hadoop安装包到 /usr/local目录下
2,解压
tar zxvf hadoop-2.6.0.tar.gz
修改主机名和IP之间的映射:
vi /etc/hosts
3,切到下图目录下:
/usr/local/hadoop-2.6.0/etc/hadoop
4,vi编辑hadoop-env.sh
vi hadoop-env.sh
向其中插入该行 export JAVA_HOME=/usr/local/jdk1.8.0_91
5,vi编辑core-site.xml
vi core-site.xml
向其中插入代码(不包括configuration):
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://xxxxxx:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop-2.6.0/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
如图:(记得将文中的*****改成你的主机名)

5,vi编辑yarn-site.xml文件
vi yarn-site.xml
向其中插入如下代码:(不包括configuration)
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
</configuration>
6,vi编辑hdfs-site.xml
vi hdfs-site.xml
在其中插入:(同上不包括configuration)
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
如下图:

7,文件重命名:
mv mapred-site.xml.template mapred-site.xml
8,启动格式化
bin/hdfs namenode -format
格式化操作不可重复,若要重复则需要在后面添加 -force强制执行
9,之前的ssh免密登录失败了,发现每登录一个节点的时候还是需要验证密码,所以,免密登录重新来解决
ssh-keygen -t rsa ssh-copy-id -i Ubuntu-1
后面是你的主机名称,如下图

再登录时已经不需要验证密码了,至于为什么之前那个办法在xshell上的免密是有用的,在这里登录的时候却没用,原因我还没有弄清楚
10,登录命令
sbin/start-all.sh
在登录的时候遇到了一个问题,分别登录datanode和namenode的时候,后面登录的那个总是能登录上去,前面那个就无法登录了,后来找了好多解决的办法,最后找到下图问题才得到了解决:

解决后如下图:
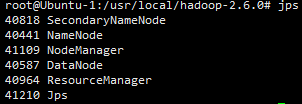
11,关闭进程
sbin/stop-all.sh
--------------------------------------------------------
下面是单独启动进程的命令
//启动hdfs sbin/hadoop-daemon.sh start namenode sbin/hadoop-daemon.sh start datanode //启动yarn sbin/yarn-daemon.sh start resourcemanager sbin/yarn-daemon.sh start nodemanager
---------------------------------------------------------------------------------------------
最后的最后,
应该将hadoop的path加到系统配置文件中,否则执行命令时会报错
vi /etc/profile
在profile文件中插入
export PATH=$PATH:$/usr/local/hadoop-2.6.0/bin:$PATH
如图:

再执行:
source /etc/profile
将文件进行重载就可以了。