python xpath解析网页用到的是lxml库,lxml的使用方法可以官方文档 http://lxml.de/lxmlhtml.html
xpath 的定位查找,可以查看 http://www.runoob.com/xpath/xpath-tutorial.html
上面的两个教程说的挺详细的,但第一个是英文的,看不起来不是很方便。第二个教程主要是说节点语法的,没有具体的获取内容的方法。
所以,均益在这里总结一下python xpath常用的方法,相信足够用了。
首先说明一下,lxml对处理的字符必须要求是unicode格式,如果网页源代码是utf-8格式,可以用decode(‘utf-8’, ‘ignore’),gbk可以用decode(‘gbk’,’ignore’)
其次,获取xpath最简单方便的就是用浏览器的copy xpath功能,这里以火狐浏览器的来举例。如图按F12打开检查Firebug功能,选择html元素,右键复制xpath
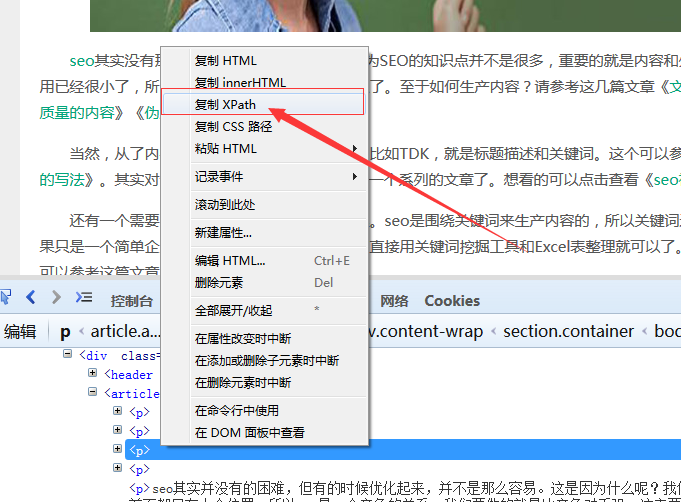
以下是具体的代码,里面注释,套用就行,非常方便
# -*- coding: utf-8 -*-
#xpath 解析网页
import urllib2
from lxml import etree
html = urllib2.urlopen('http://junyiseo.com/seoxinde/276.html').read()
#lxml对处理的字符必须要求是unicode格式如果网页源代码是utf-8格式,可以用decode('utf-8', 'ignore'),gbk可以用decode('gbk','ignore')
html = html.decode('utf-8', 'ignore')
#启用xpath解析
tree = etree.HTML(html)
#获取属性值/@href /@src
link = tree.xpath('/html/body/section/div[2]/div/article[1]/header/h2/a/@href')
print link
#获取文字内容a链接 /text()
text = tree.xpath('/html/body/section/div[2]/div/article[3]/header/h2/a/text()')
print text
#获取深层次标签的文本内容
wenben = tree.xpath('/html/body/section/div[2]/div/article')
for i in wenben:
n = i.xpath('string(.)')
print n