结对作业二
| 这个作业属于哪个课程 | 2021春软件工程实践|W班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 寒假作业2/2 |
| 结对学号 | 221801102, 221801107 |
| 这个作业的目标 | 根据原型实现产品,记录PSP表格 |
| 其它参考文献 | golang |
git 仓库连接
https://github.com/NOS-AE/PairProject/tree/main
代码规范链接
https://github.com/NOS-AE/PairProject/blob/main/221801102%26221801107/codestyle.md
网站链接
PSP表格
221801102
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | 估计这个任务需要多少时间 | 10d | 11d |
| Development | 开发 | 58h 10min | 72h 10min |
| Analysis | 需求分析 (包括学习新技术) | 3h | 5h |
| Design Spec | 生成设计文档 | 1h | 1h |
| Design Review | 设计复审 | 1h | 2h |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10min | 10min |
| Design | 具体设计 | 5h | 8h |
| Coding | 具体编码 | 45h | 52h |
| Code Review | 代码复审 | 1h | 1h |
| Test | 测试(自我测试,修改代码,提交修改) | 2h | 3h |
| Reporting | 报告 | 1h | 1h 10min |
| Test Report | 测试报告 | 30min | 30min |
| Size Measurement | 计算工作量 | 10min | 10min |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20min | 30min |
| 合计 | 59h 10min | 73h 20min |
221801107
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 120 | 120 |
| Estimate | 估计这个任务需要多少时间 | 120 | 120 |
| Development | 开发 | 1000 | 860 |
| Analysis | 需求分析 (包括学习新技术) | 240 | 200 |
| Design Spec | 生成设计文档 | 30 | 30 |
| Design Review | 设计复审 | 20 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| Design | 具体设计 | 30 | 30 |
| Coding | 具体编码 | 500 | 400 |
| Code Review | 代码复审 | 60 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 90 | 90 |
| Reporting | 报告 | 110 | 120 |
| Blog | 博客 | 80 | 90 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 1230 | 1080 |
成品展示
希望助教好好玩耍。以下成品在 2K 显示器上截图。实际大小可能因为您的屏幕支持的分辨率不同而不同。
- 首页

- 搜索界面
- 收藏夹界面
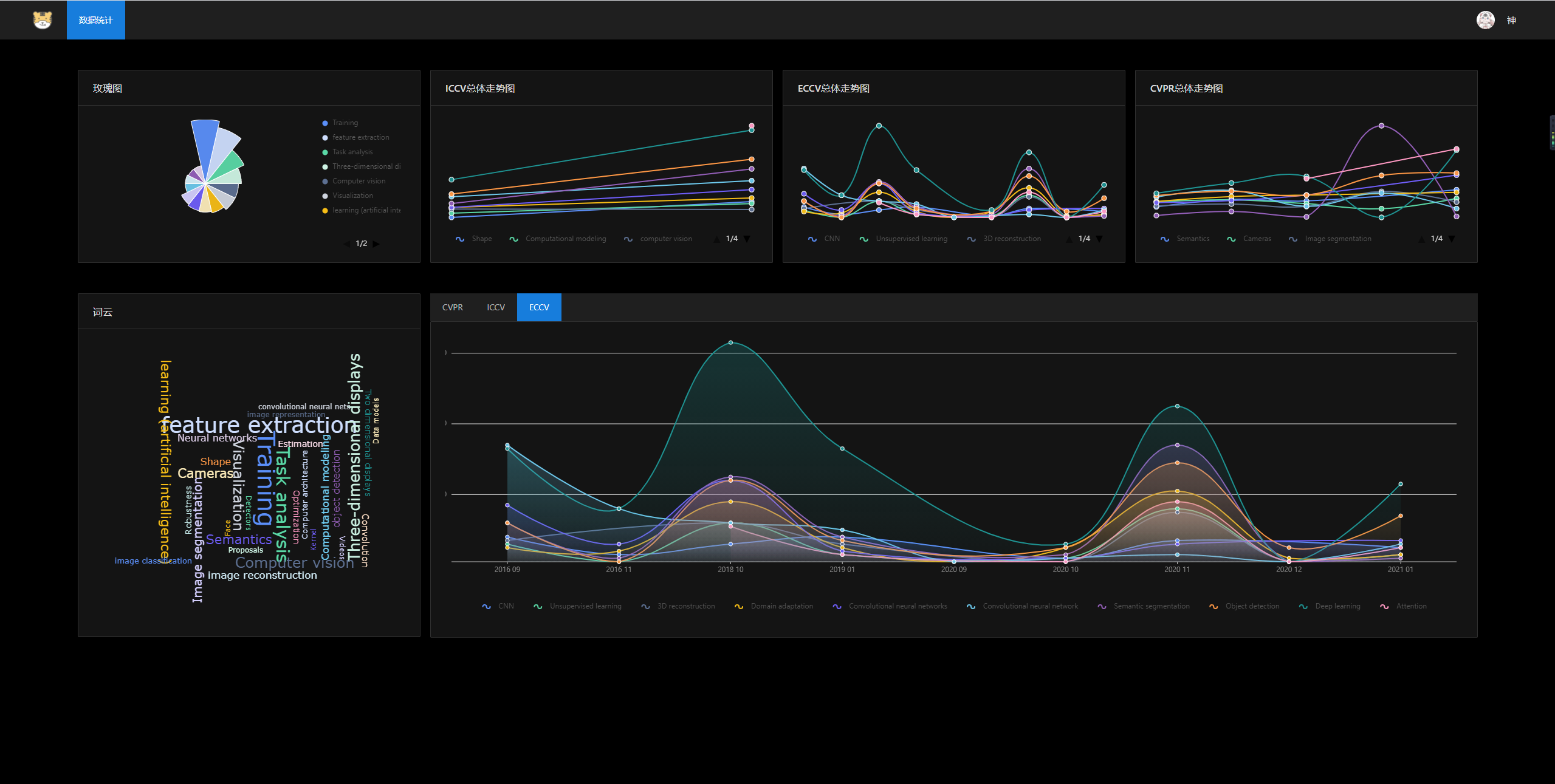
- 数据统计界面
等等,以为到这里就结束了吗?
所有的页面均支持自适应。可以在手机上观看,或者平板上观看。
- 手机端首页
- 移动端搜索界面
- 移动端收藏夹界面
- 移动端数据统计界面
这里加个平板的好了
对了,在助教的电脑上,请注意看一下自己的分辨率,或许显示会有所不同,为了更好的显示体验,请在2k屏上观看,或者在1080P上缩小查看。
等等,以为到这里就结束了吗?
所有与加载有关的界面均设置了loading,为使用者提供良好体验,并且提供即时的反馈功能。
- 搜索页动画
- 数据统计界面加载动画
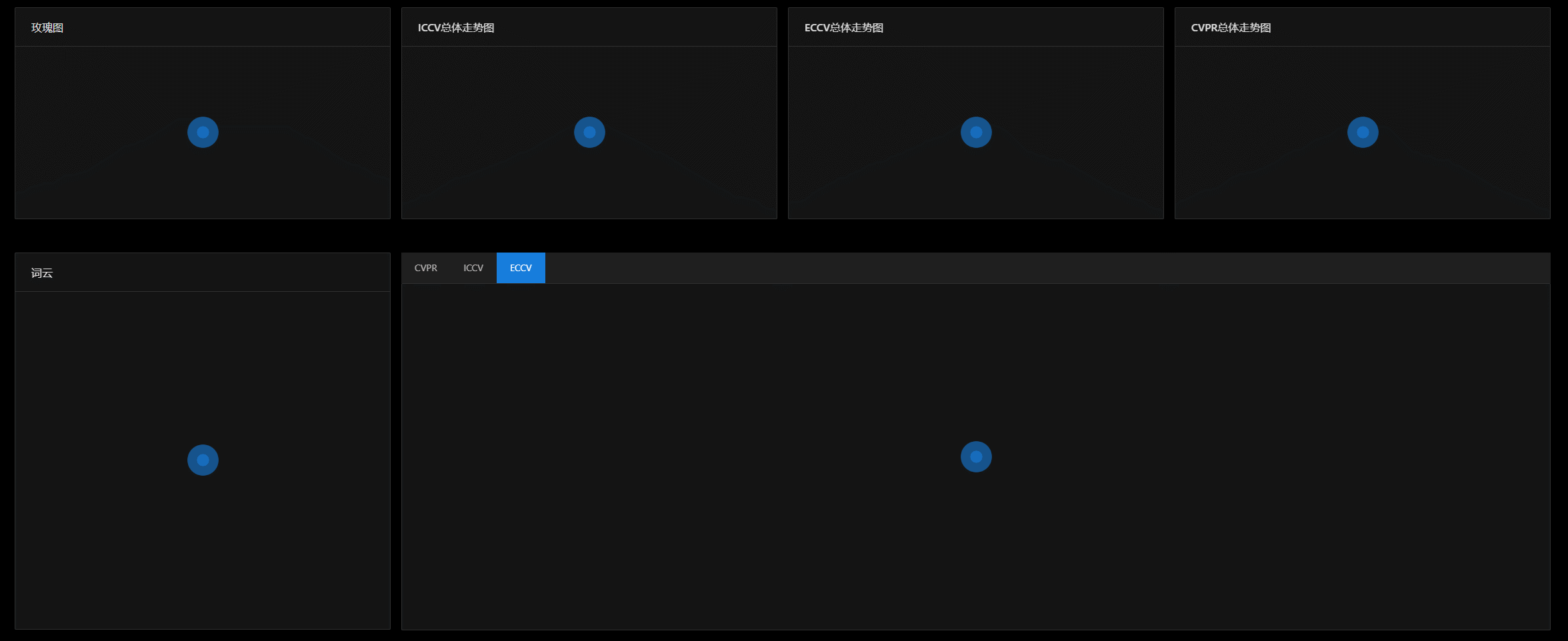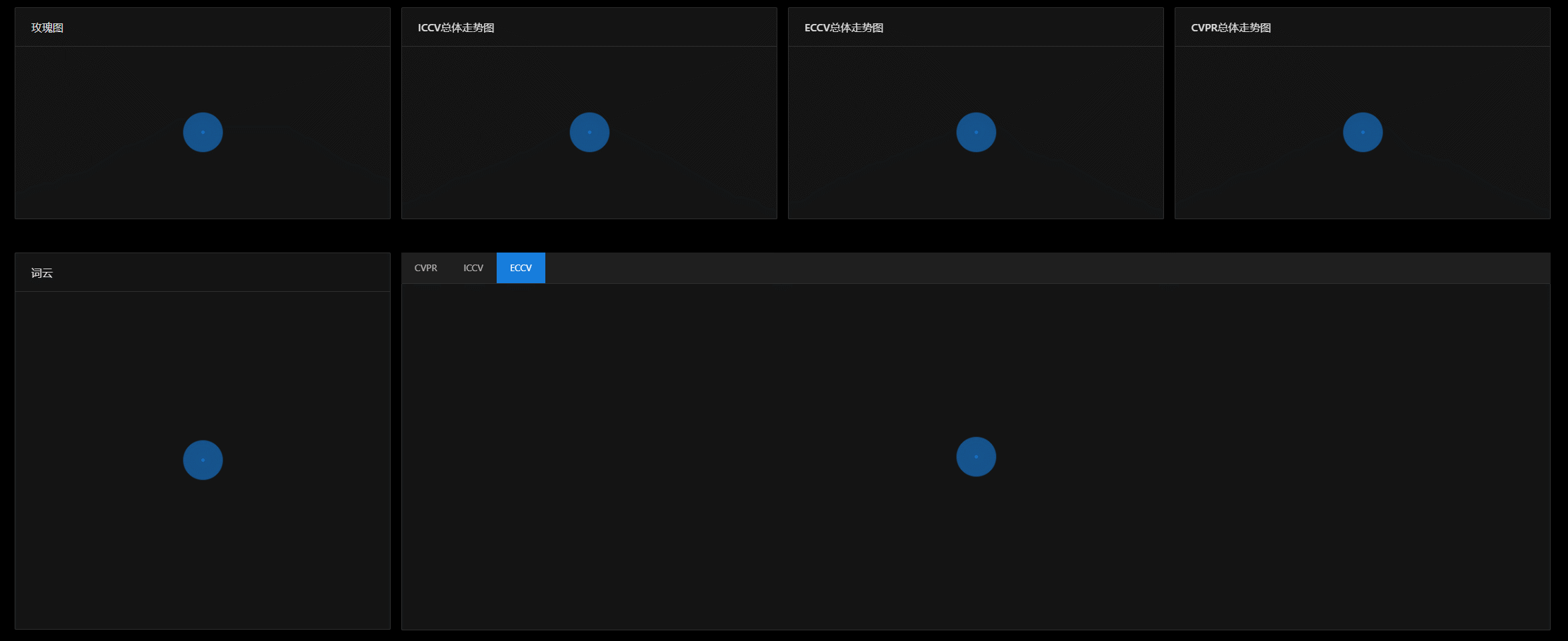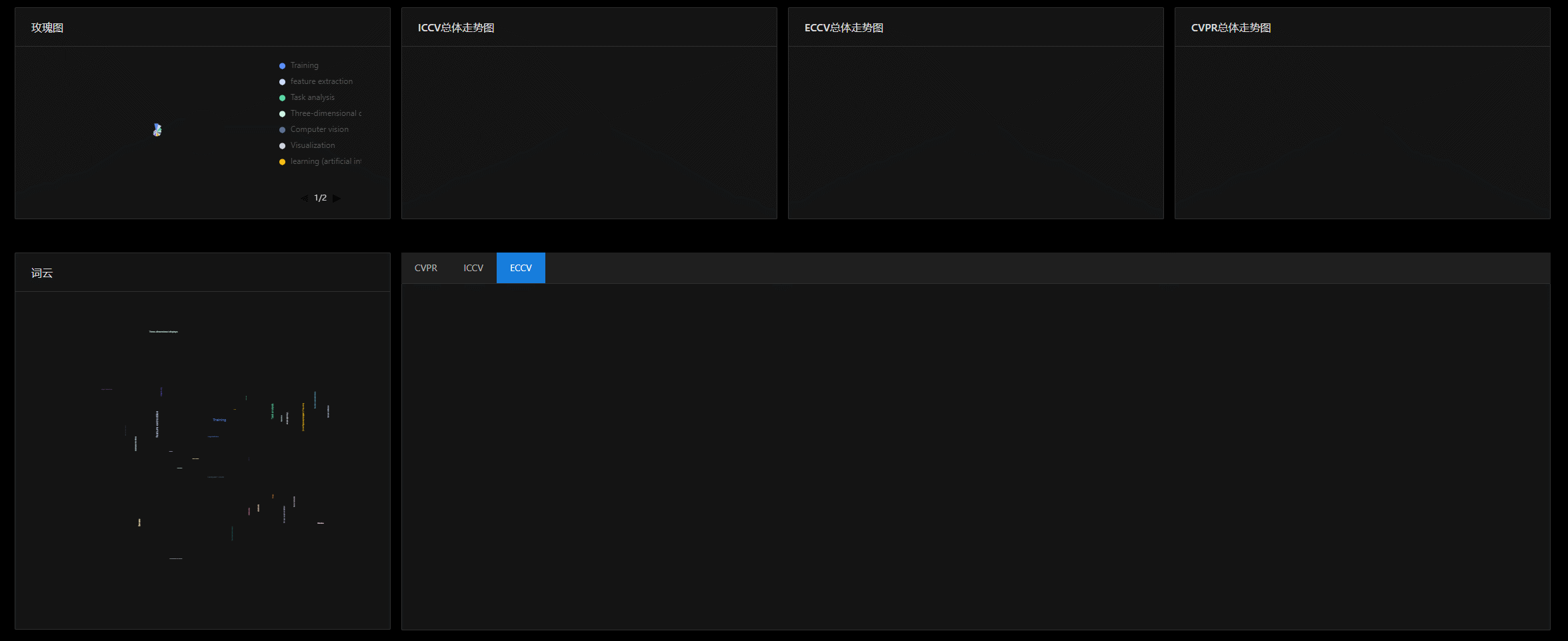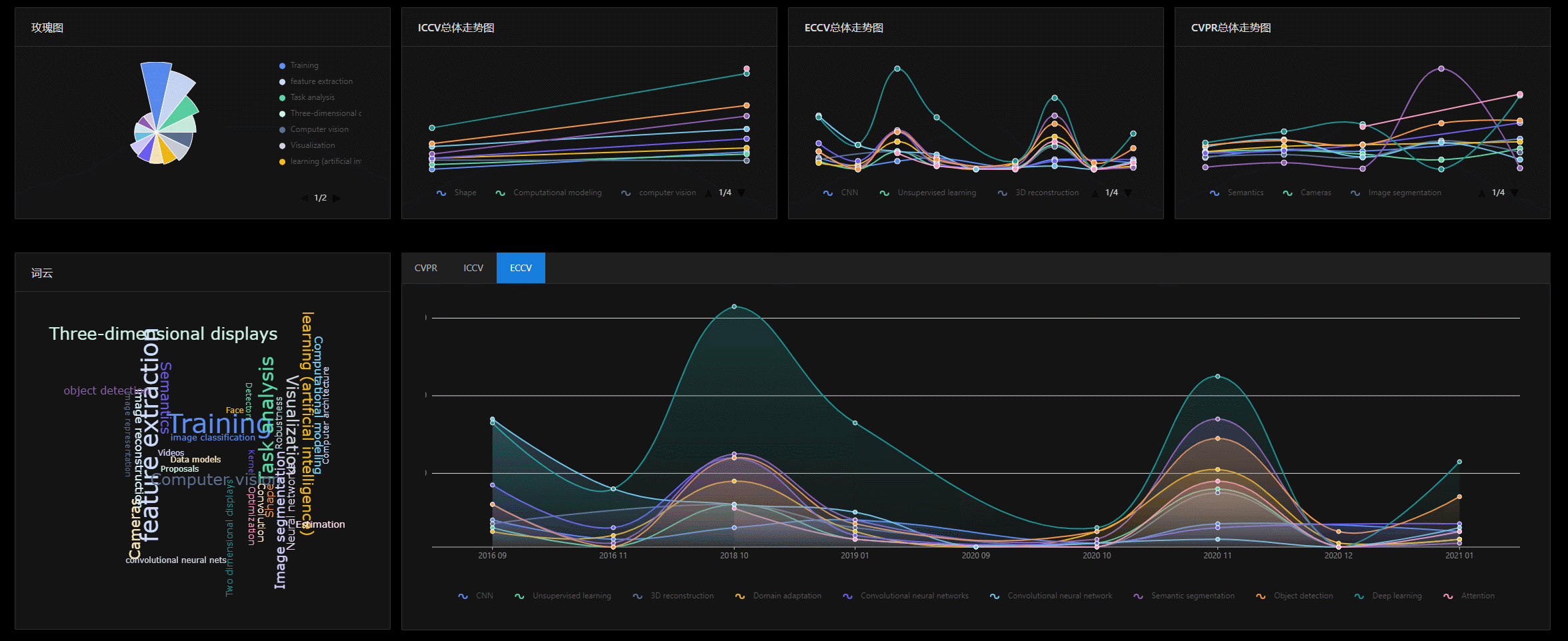
等等,以为到这里就结束了吗?
图表界面在替换议会的时候,由于数据对应绑定到同一个组件,因此可以启动组件的动画效果。
- 数据统计界面切换动画

等等,真的结束了吗??
如果你访问一个不存在的路由会怎么样呢?hh
- 404界面

将会提示你返回主页,这个界面不存在噢。
另外还有部分小型界面,如登录框,编辑框等,就不写了,助教可以自己把玩。
结对讨论
github 讨论
1. 分支讨论
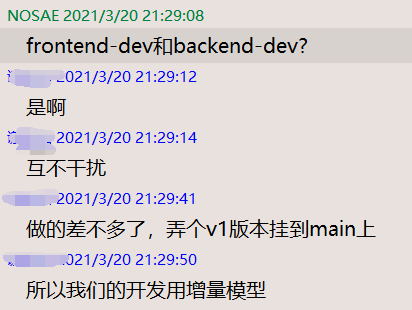
最后的解决方案是 main => dev => (frontend-dev) / (backend-dev)
如果有 hotfix 拉一个新的分支,等到 v1 版本准备就绪 将, frontend-dev/backend-dev merge 到 dev,再从dev 拉一个 release 进行发布。
2.项目执行方案讨论

最后我们使用了 github 提供的 project 进行任务的管理与运行,后来由于我们发现这样效率较低,而且我们后来都是在一个房间里编程,因此没必要搞这些东西。
3.oauth2.0 讨论
页面显示讨论
1. 首页讨论
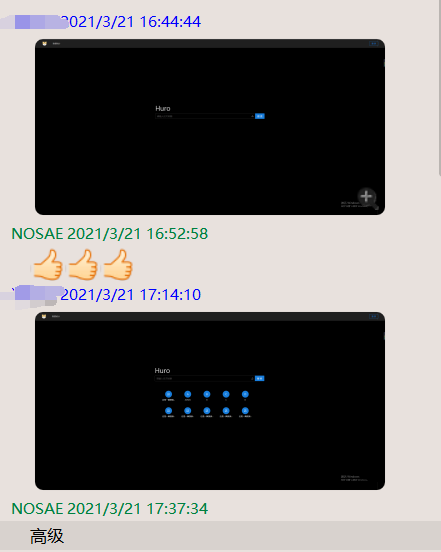
等等,我是不是说要做完弄个背景图?咕咕咕~
后端进度讨论
1. 论文爬取部分

后来爬取到了。
前后端联调讨论
1. 前后端联调 oauth2.0 问题
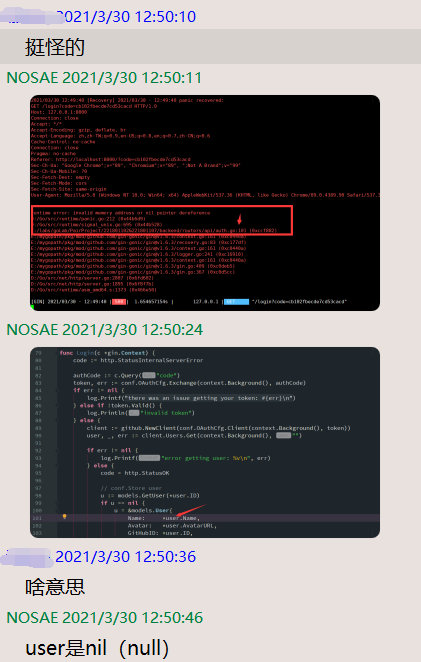
2. 接口替换,为了 nginx 好做代理转发
其实我们俩之间还有很多激情讨论,十分遗憾。由于强哥(221801102)来到我的宿舍,我们之前用口谈的方式进行交流,错过了非常多精彩的画面。着实可惜。
设计实现过程
前端部分
设计过程比较复杂,这边单独抽取一些作为展示。
1. 设立 Model 层
// import ..
// some other interfaces
export interface SearchModelType {
namespace: ModelNameSpaces.Search;
state: SearchModelState;
effects: {
/** 搜索 */
search: Effect;
};
reducers: {
changePage: ImmerReducer<SearchModelState>;
changeTotal: ImmerReducer<SearchModelState>;
saveData: ImmerReducer<SearchModelState>;
saveLastSearchList: ImmerReducer<SearchModelState>;
changeCodeStatus: ImmerReducer<SearchModelState>;
};
}
export const initialState: SearchModelState = {
keywords: item,
page: 1,
pageSize: 12,
total: 0,
list: [],
lastSearchList: [],
};
const SearchModel: SearchModelType = {
namespace: ModelNameSpaces.Search,
state: initialState,
effects: {
// 异步代码
},
reducers: {
// 同步代码
},
};
export default SearchModel;
通过单独设置Modal层,将业务逻辑和服务调用层,界面层分离。利用 dva 将数据部分整合起来,并使用 typeScript 设置类型, 利用 Immer.js 设置不可变值。
将业务逻辑相同的地方绑定,做到高耦合,低内聚。
2. 设立 Service 层
import { BASE_URL } from '@/constants';
import request from 'umi-request';
const login = (code: string) => {
return request.get(`${BASE_URL}/login`, {
params: {
code,
},
});
};
const logout = () => {
return request.get(`${BASE_URL}/logout`);
};
export { login, logout };
将数据接口统一抽离到 service 层单独封装,利用 BASE_URL 设置不同环境下的 api 访问地址。
其他地方不一一介绍了,贴一个目录结构图吧
3. 目录结构图
├─assets
├─components
│ ├─chartLoading
│ ├─circleLetter
│ ├─constants
│ ├─editModal
│ ├─iconText
│ ├─lineChart
│ ├─loginModal
│ ├─roseChart
│ ├─smallLineChart
│ ├─themeSearch
│ └─wordCloud
├─constants
├─layouts
├─models
├─pages
│ ├─favorite
│ ├─oauth2.0
│ ├─search
│ └─statistic
├─services
├─types
└─utils
各个结构都分层了,结构清晰,可以作为长期维护的项目。
后端部分
1. 框架使用:主要用到gin http框架,colly爬虫框架,mysql储存论文 用户等信息,redis做爬虫与搜索结果缓存
2. 架构:MVC,由于前后端分离,只有MC
M:
// base model with some universal fields
type Model struct {
ID uint `gorm:"primarykey" json:"-"`
CreatedAt time.Time
UpdatedAt time.Time
}
C(各个路由处理逻辑就不展示了):
apiV1 := r.Group("/api/v1")
{
apiV1.GET("/auth", api.Auth)
apiV1.GET("/auth-callback", api.Callback)
apiV1.GET("/login", api.Login)
authGroup := apiV1.Group("/").Use(middleware.Auth())
{
cors.Default()
authGroup.GET("/logout", api.Logout)
authGroup.POST("/search", api.Search)
authGroup.GET("/fav", api.GetUserFav)
authGroup.GET("/op-fav", api.OpUserFav)
authGroup.POST("/ed-fav", api.EditUserFav)
authGroup.GET("/cloud", api.GetWordCloud)
authGroup.GET("/words", api.GetWords)
}
}
3. 爬虫:使用cron开启定时爬虫,更新paper
c := cron.New(cron.WithParser(
cron.NewParser(
cron.SecondOptional | cron.Minute | cron.Hour | cron.Dom | cron.Month | cron.Dow),
),
)
// run at every Sunday midnight
_, err := c.AddFunc("0 0 0 * * ?", func() {
crawler.Start()
})
if err != nil {
log.Println(err)
}
c.Start()
4. 项目结构
├─.idea
│ ├─codeStyles
│ └─dictionaries
├─conf
├─crawler
├─docs
├─middleware
├─models
│ └─json
├─pkg
│ ├─cache
│ └─utils
├─routers
│ ├─api
│ └─swag
├─templates // for test
└─test
代码说明
前端
这里也是代码比较多,我将单独抽离几个区域进行说明
1. types 总仓库
import { initialState as UserInitialState } from '@/models/user';
import { initialState as SearchInitialState } from '@/models/search';
import { initialState as FavoriteInitialState } from '@/models/favorite';
import { initialState as StatisticInitialState } from '@/models/statistic';
type UserModel = typeof UserInitialState;
type SearchModel = typeof SearchInitialState;
type FavoriteModel = typeof FavoriteInitialState;
type StatisticModel = typeof StatisticInitialState;
enum ModelNameSpaces {
User = 'User',
Search = 'Search',
Favorite = 'Favorite',
Statistic = 'Statistic',
}
type RootStore = {
[key in ModelNameSpaces.User]: UserModel;
} &
{
[key in ModelNameSpaces.Search]: SearchModel;
} &
{
[key in ModelNameSpaces.Favorite]: FavoriteModel;
} &
{
[key in ModelNameSpaces.Statistic]: StatisticModel;
};
export { ModelNameSpaces, RootStore };
这里对于所有的 Model 层进行了一个整合,并导出根仓库,供各个页面使用。
2. Layout 共用部分
// import ....
const { Header, Content } = ALayout;
const Layout = ({ children }: IRouteComponentProps) => {
const dispatch = useDispatch();
const { avatar, isLogin, username } = useSelector((store: RootStore) => {
const { [ModelNameSpaces.User]: UserModel } = store;
return UserModel;
});
// decls
return (
// some components
);
};
export default Layout;
这里 Layout 是导航栏,单独抽离出来供各个界面使用,另外,是否助教发现了这里
useSelector((store: RootStore) => {
const { [ModelNameSpaces.User]: UserModel } = store;
return UserModel;
这一步恰好利用了数据总仓库提供的数据类型,做类型推导,在编译器可以提供智能的语法提示
3. 其他
其他还有很多,这里就不一一展示了,如果助教有兴趣可以联系我 221801107 进行前端方向各个部分的讨论。
后端
1. 爬虫
ECCV论文:使用colly框架,结合goquery,选择html上需要的元素(比如论文标题)
func init() {
cECCV.OnHTML("#kb-nav--main .title", onECCVTitle) // css选择器回调,获取对应的数据
cECCV.OnHTML(".FulltextWrapper", onECCVDetails)
cECCV.OnError(func(response *colly.Response, err error) {
log.Println(err)
})
}
CVPR、ICCV论文:在ieeexplore这个网站上爬取,其实也不算爬取,因为这个网站的论文列表和详情都是异步加载的,直接爬爬不到html元素,所以借助浏览器F12获取到了论文搜索的API接口,直接把接口拿下来然后解析json数据,论文详情的API找不到,但是在doc里面找到了一串json字符串,并且发现里面的内容刚好就是论文详情,所以用正则将其拿下来,并且解析。
// colly没有onJSON接口,并且论文详情的json虽然在doc里,但是是在script中的,也无法依赖onHTML进行监听回调
// 只能手动处理一下,我在这里是通过res的content-type判断是论文列表还是论文详情
func onResponse(r *colly.Response) {
contentType := r.Headers.Get("Content-Type")
if strings.Contains(contentType, "text/html") {
onIEEE(r)
} else if strings.Contains(contentType, "application/json") {
onJSON(r)
}
}
2. http API使用gin进行处理
对于用户认证,使用session的方式维持会话,对于认证过程,使用了gin中间件
apiV1 := r.Group("/api/v1")
{
apiV1.GET("/login", api.Login) // 对于登录不需要认证
authGroup := apiV1.Group("/").Use(middleware.Auth()) // 使用Auth中间件认证
{
cors.Default()
authGroup.GET("/logout", api.Logout)
authGroup.POST("/search", api.Search)
authGroup.GET("/fav", api.GetUserFav)
authGroup.GET("/op-fav", api.OpUserFav)
authGroup.POST("/ed-fav", api.EditUserFav)
authGroup.GET("/cloud", api.GetWordCloud)
authGroup.GET("/words", api.GetWords)
}
}
// 认证中间件
func Auth() gin.HandlerFunc {
return func(c *gin.Context) {
sess, _ := conf.Store.Get(c.Request, conf.AuthSessKey)
// 判断token是否存在,并且用登录时保存的githubID从数据库取出用户,避免再次从github认证
if _, ok := sess.Values["githubAccessToken"]; ok {
id := sess.Values["githubID"].(int64)
user := models.GetUser(id)
c.Set("user", user)
c.Next()
} else {
utils.JSONUnauthorized(c, http.StatusUnauthorized, http.StatusText(http.StatusUnauthorized), nil)
c.Abort()
}
}
}
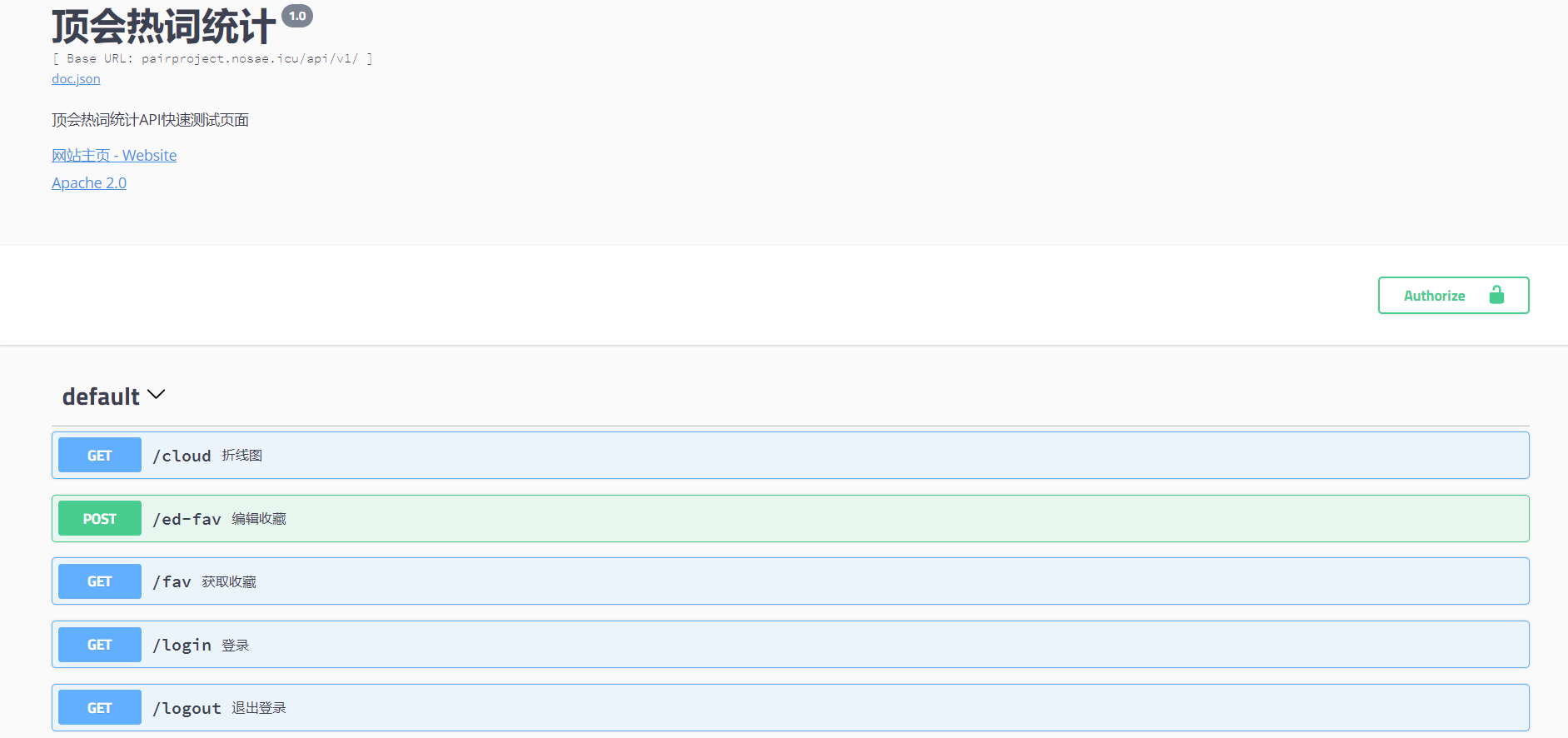
3. go-swag生成api测试页面,方便进行API测试
心路历程和收获
221801107
这次收获还是比较大的,总的来说如下。
- 学习了 umi 框架的使用
- 学习了 自适应 应该如何做比较合适
- 学习了 约定式 路由的使用
- 和队友沟通的过程也很愉快,收获了开心
221801102
- 增长了对后端开发的了解
- 学习了gin框架和colly爬虫库
- 这次github OAuth认证搞死我们了,主要是因为github OAuth用的是accessToken模式认证,有各种字段的配置,一个字段不对就导致出现各种各样的错误,再加上github服务器在国内就不好访问,增加了debug的困难,最离谱的就是有的用户没有Name字段只有Login字段,但是报错却不报那个地方,导致整了很久。
- 增加了debug能力
- 学会了服务器的配置和使用
评价结对队友
221801107 => 221801102
这次是第二次和队友一起做结对作业,队友很棒,也是在一起完了很久的朋友了。其实我俩都是做前端的原本,他是做安卓,我是做前端界面。这一次他选择做后端,学习GO语言,花了非常多的时间,很辛苦。而且遇到问题也可以很快解决,很稳定。合作很愉快。
221801102 => 221801107
我之前没使用go写过项目,后端经验基本为0,其中遇到了很多问题,都亏有一个循循善诱的队友,毕竟他也做过后端来做项目,还是比较有经验的,我直接起飞,虽然到ddl的时候,github认证上出了各种问题,但是他都很积极地和我一起解决问题,尽管他没学过go。