OPTICS是基于DBSCAN算法的缺陷提出来的一个算法。
核心思想:为每个数据对象计算出一个顺序值(ordering)。这些值代表了数据对象的基于密度的族结构,位于同一个族的数据对象具有相近的顺序值。根据这些顺序值将全体数据对象用一个图示的方式排列出来,根据排列的结果就可以得到不同层次的族。
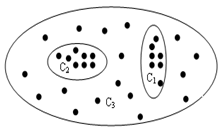
考察DBSCAN,可以发现,对一个恒定的MinPts值来说,取值较小时得到的聚类结果完全包含在根据较大的取值所获得的聚类结果中。
如图,当取值较小时,得到的聚类结果是C1和C2,当取值较大时,得到的聚类结果是C3。
可以看到,C1和C2是包含在C3中的。换句话说,C1、C2、C3间具有层次关系,C3可以看作是C1和C2的父亲,而C1和C2可以看作是C3的孩子。
因此,在生成族的时候,最好能够将位于不同层次上的族同时构建出来,而不是根据某个特定的值仅仅构建其中的一层。
为了同时构建不同层次上的族,数据对象应当以特定的顺序来处理。这个顺序称为族序(cluster-ordering),它决定了对象扩展时的次序。
为了使较低层次上的族(这些族的数据密度较大)能够首先构建完成,在进行对象扩展时,应该优先选择那些根据最小的取值而密度可达的对象。
基于这个思想,每个数据对象需要存储两个值,一个是核心距离(core-distance),另一个是可达距离(reach-distance)。
核心距离:给定一个数据对象集合D,两个参数和MinPts,一个对象O,如果O是一个核心对象,则O的核心距离(core-dist)是使得O能成为核心对象的最小半径值(该值小于等于)。如果O不是核心对象,则O的核心距离没有定义。
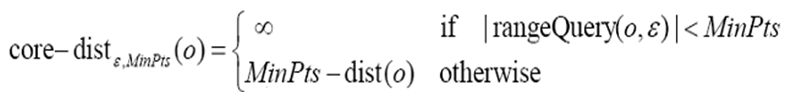
其中|rangeQuery(O, )|<MinPts表示在O的-邻域的数据对象的个数小于MinPts个,说明在这种情况下O不是一个核心对象。
反之,当O是一个核心对象时,MinPts-dist(O)表示的就是使得O的-邻域能够包含MinPts个数据对象的最小半径值。
例如,给定MinPts=5, 则表示的半径就是对象O的核心距离
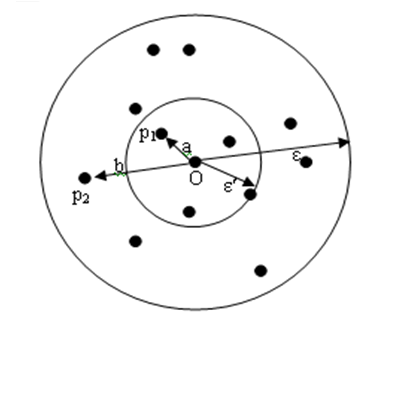
可达距离:给定一个数据对象集合D,两个参数和MinPts,一个对象O,如果O是一个核心对象,则O与另一个对象p间的可达距离(reachbility-distance)是O的核心距离和O与p的欧几里得距离之间的较大值。如果O不是一个核心对象,O与p之间的可达距离没有定义。
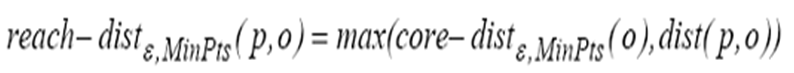
由于p1和O之间的距离a小于对象O的核心距离,即dist(p1, O) < core-dist(O),所以p1和O之间的可达距离就是对象O的核心距离。即reach-dist(p1, O) = core-dist(O)= 。
由于p2和O之间的欧几里得距离b大于对象O的核心距离,即dist(p2, O) > core-dist(O),所以p2和O之间的可达距离就是p2和O之间的欧几里得距离。即reach-dist(p2, O) = dist(p2, O)。
OPTICS算法的工作过程
- 第一个阶段计算每个对象的核心距离和可达距离,生成族序;
- 采用和DBSCAN算法类似的工作过程。同样从任意一个数据对象p开始,如果p是一个核心对象,则根据输入的两个参数和MinPts,提取所有从p直接密度可达的数据对象,计算它们的核心距离和可达距离,并将它们放入待处理队列Q中。
- 接下来,算法从Q中选取一个具有最小可达距离值的对象q进行进一步的扩展。同样,首先检查q是否是核心对象,如果是,则根据输入参数和MinPts,提取所有从q直接密度可达的数据对象,计算它们的核心距离和可达距离,并将它们放入待处理队列Q中。如果q不是核心对象,则什么都不做。
- 需要注意的是,对q进行扩展时,还需要对队列Q中的数据对象的可达距离进行更新,保证其存储的是到最近的核心对象的距离。算法一直进行到所有的数据对象都被处理过为止。
- 第二个阶段进行聚类,在聚类的过程中,只需要用到第一阶段所生成的对象之间的族序信息,不再需要其它的信息。
- 根据第一阶段所生成的族序和特定的i(0i )值,生成相应的族。具体过程是:根据族序逐个处理每一个对象。
- 对任一对象p,首先看p的可达距离是否大于i。如果是,则说明在p之前所处理过的对象,没有一个对象到p是可达的。(这是因为,如果某个对象到p可达的话,p的可达距离不可能大于i)。因此,如果p的可达距离大于i的话,需要进一步考察p的核心距离。
- 如果p的核心距离小于i,则说明p是一个核心对象,这时创建一个新族
- 否则,将p标记为噪声。
- 如果p的可达距离小于等于i的话,则直接将p标记为当前族。