webdriver的环境配置
about回到顶部
环境: win10 +
想要Python通过selenium操作浏览器搞些事情,就必须有两个前提条件:
- 下载selenium模块
- 安装selenium的浏览器驱动 webdriver
selenium模块下载
pip install selenium
pip install -i https://pypi.doubanio.com/simple/ selenium
pip install -i https://pypi.doubanio.com/simple/ selenium==3.141.0
浏览器驱下载
浏览器驱动的安装时新手阶段遇到较多问题之一,因为可选择的浏览器较多,我们先来聊聊各种场景的浏览器:
- 网页浏览器,也就是我们现在经常用到的浏览器,打开浏览器有个可视化的界面供我们操作,常见的有:
- Firefox
- Safari
- IE/edge
- Opera
- 无头浏览器(Headless Browser),无头,这里是说无界面的,这种浏览器的运行是不可见的,selenium中常用的无头浏览器有:
- PhantomJS无头浏览器
- Google无头浏览器
- Firefox无头浏览器
关于无头浏览器:无头浏览器指的是没有图形用户界面的浏览器。无头浏览器在类似于流行网络浏览器的环境中提供对网页的自动控制,但是通过命令行界面或使用网络通信来执行。 它们对于测试网页特别有用,因为它们能够像浏览器一样呈现和理解超文本标记语言,包括页面布局、颜色、字体选择以及JavaScript和AJAX的执行等样式元素,这些元素在使用其他测试方法时通常是不可用的。
无头浏览器常用于:
- Web应用程序中的测试自动化。
- 拍摄网页截图
- 对JavaScript库运行自动化测试
- 收集网站数据
- 自动化网页交互
使用无头浏览器的优势:
- 对于UI自动化测试,少了真实浏览器加载css,js以及渲染页面的工作。无头测试要比真实浏览器快的多。
- 可以在无界面的服务器或CI上运行测试,减少了外界的干扰,使自动化测试更稳定。
- 在一台机器上可以模拟运行多个无头浏览器,方便进行并发测试。
关于PhantomJS无头浏览器:PhantomJS是一个可以用JavaScript编写脚本的无头web浏览器。它在Windows、macOS、Linux和FreeBSD上运行。使用QtWebKit作为后端,它为各种web标准提供了快速的本地支持:DOM处理、CSS选择器、JSON、Canvas和SVG。
另外,说一个比较悲痛的消息:PhantomJS暂停维护(可能的原因是内部问题和外部压力(Google和Firefox无头带来的压力)),所以,我们现在使用PhantomJS的话,你会看到提示:
UserWarning: Selenium support for PhantomJS has been deprecated, please use headless versions of Chrome or Firefox instead
warnings.warn('Selenium support for PhantomJS has been deprecated, please use headless '
闲话少叙,先来看具体怎么安装和使用!
网页浏览器回到顶部
相对于无头浏览器来说,网页浏览器有以下优势:
- 配置相对简单
- 执行过程可视化,便于调试
- 模拟真实的用户操作
Chrome回到顶部
Chrome的驱动下载地址:
这里以淘宝镜像为例。
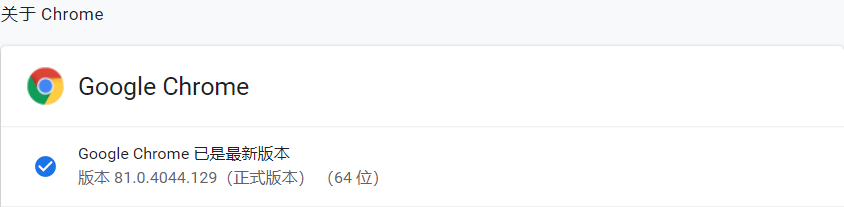
- 查看你的Chrome浏览器的版本。打开你的Chrome浏览器的
设置▶帮助▶关于Google Chrome(G),这里我的Chrome的版本是81.0.4044.129
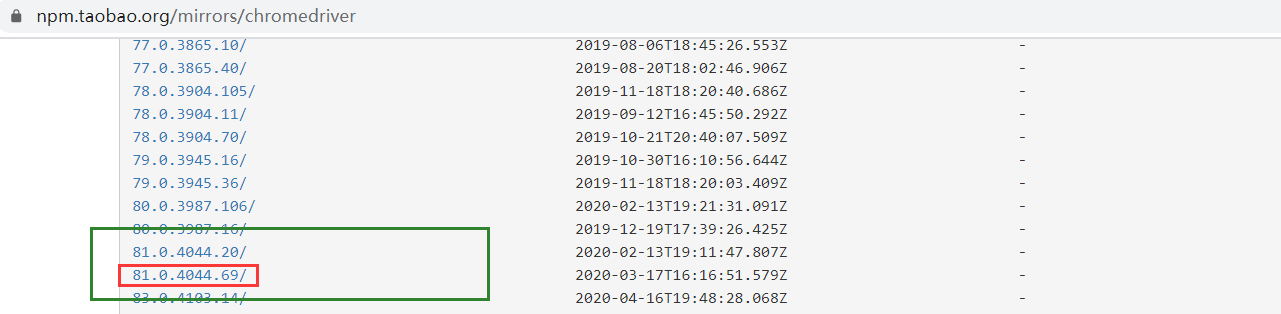
2. 打开淘宝镜像链接:https://npm.taobao.org/mirrors/chromedriver,如下图,可以看到,有两个81版本的驱动,我们选择一个最贴近浏览器版本的驱动版本81.0.4044.69
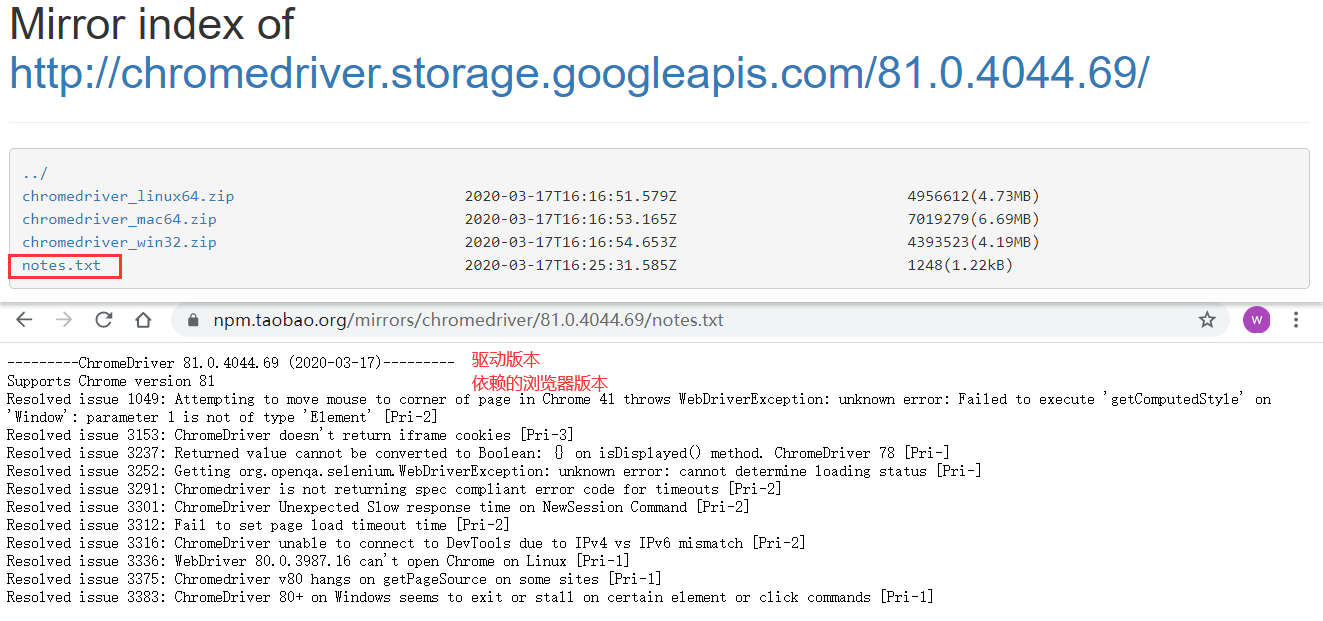
- 那我们选择的对吗?现在点击
81.0.4044.69/这个驱动下载链接中,查看notes.txt文件。可以看到,notes.txt文件中说了三件事,浏览器驱动的版本、依赖浏览器的版本、该版本的驱动解决了哪些问题。通过依赖的浏览器驱动版本我们可以知道,这个就是我们想要的那个驱动。
- 回到之前的驱动下载页面,根据系统选择不同的安装包,这里我选择
chromedriver_win32.zip。点击链接立即下载到本地。

- 压缩包内就一个
chromedriver.exe可执行文件,将该文件移动到Python的安装目录中的Scripts目录(因为该目录已经添加到了系统Path中,你移动到别的目录也行,只要将目录添加到系统的Path中)

- 可以尝试测试一下了:
from selenium import webdriver
def foo():
"""
如果报如下错误:
selenium.common.exceptions.WebDriverException: Message: 'chromedriver' executable needs to be in PATH. Please see https://sites.google.com/a/chromium.org/chromedriver/home
原因是在执行时,没有在path中找到驱动,这里的解决办法是实例化driver对象时,添加executable_path参数,引用驱动的绝对路径
"""</span>
<span class="hljs-comment"># driver = webdriver.Chrome(executable_path="C:Python36Scriptschromedriver.exe") # 解决如上报错</span>
driver = webdriver.Chrome()
driver.implicitly_wait(time_to_wait=<span class="hljs-number">10</span>)
driver.get(<span class="hljs-string">'https://www.baidu.com'</span>)
print(driver.title) <span class="hljs-comment"># 百度一下,你就知道</span>
driver.quit()
if name == 'main':
foo()
效果就是打开一个浏览器,然后代码获取了百度主页的title,然后关闭浏览器。
Firefox回到顶部
- 还是要先查看Firefox的浏览器版本,
设置▶帮助▶关于 Firefox,可以看我的Firefox版本是74。

- 打开Firefox的驱动下载地址:https://github.com/mozilla/geckodriver/releases,在最新的
v0.26.0版本的描述中,推荐Firefox的版本≥60,而我们的Firefox版本正符合;下拉根据系统选择不同的压缩包,这里我选择geckodriver-v0.26.0-win64.zip。

- 下载到本地是一个
geckodriver.exe可执行文件,同样的,你将该文件移动到Python安装目录中的Scripts目录(跟Google的驱动放一起,不会放的,参考Google驱动的第5步)。

- 测试:
from selenium import webdriver
def foo():
"""
如果报如下错误:
selenium.common.exceptions.WebDriverException: Message: 'geckodriver' executable needs to be in PATH.
原因是在执行时,没有在path中找到驱动,这里的解决办法是实例化driver对象时,添加executable_path参数,引用驱动的绝对路径
"""
<span class="hljs-comment"># driver = webdriver.Firefox(executable_path="C:Python36Scriptsgeckodriver.exe") # 解决如上报错</span>
driver = webdriver.Firefox() <span class="hljs-comment"># 解决如上报错</span>
driver.implicitly_wait(time_to_wait=<span class="hljs-number">10</span>)
driver.get(<span class="hljs-string">'https://www.baidu.com'</span>)
print(driver.title) <span class="hljs-comment"># 百度一下,你就知道</span>
driver.quit()
if name == 'main':
foo()
这里在再补充一个错误,我之前的Firefox的版本是最新版,但我本机运行有问题,所以在使用selenium操作的时候,报了这个错误:
selenium.common.exceptions.TimeoutException: Message: connection refused
经过查询是我的Firefox浏览器有问题,我就降级装了个74版本的。但这只是个例。
Safari回到顶部
首先保证你的Python和selenium模块安装完成:
# 使用brew命令安装python3.7
brew install python3
# 安装selenium模块
pip3 install selenium==3.141.0
来看如何配置Safari。
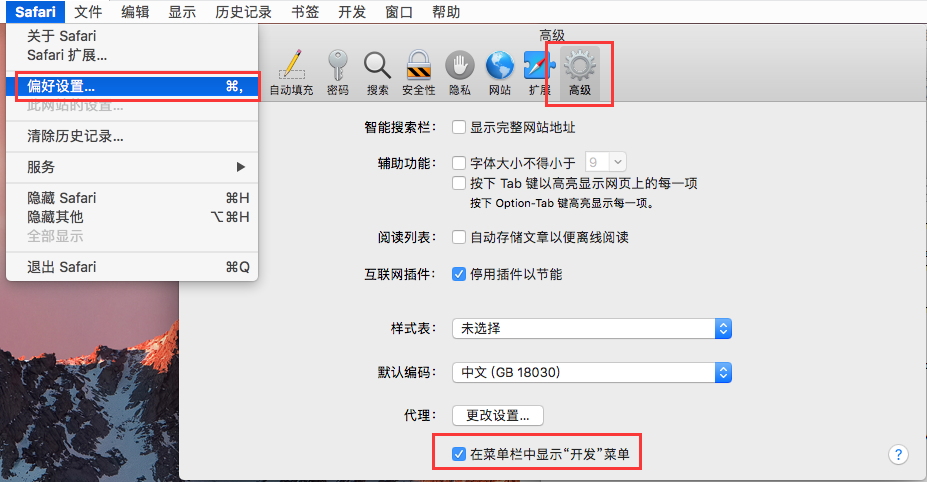
从macOS El Capitan和Sierra上的Safari 10开始,每个版本的浏览器都包含WebDriver支持。要启用支持:
Enable the Developer menu from Safari preferences # 从Safari首选项中启用“开发人员”菜单
Check the Allow Remote Automation option from with the Develop menu # 从“开发”菜单中选中“允许远程自动化”选项
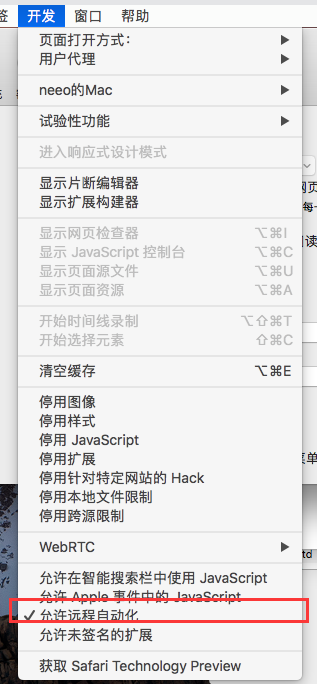
然后,在首次启动之前,终端输入:
/usr/bin/safaridriver -p 1337
然后按照提示输入密码,使webdriver获得授权。
现在可以执行测试了:
from selenium import webdriver
def foo():
driver = webdriver.Safari()
driver.implicitly_wait(time_to_wait=<span class="hljs-number">10</span>)
driver.get(<span class="hljs-string">'https://www.baidu.com'</span>)
print(driver.title) <span class="hljs-comment"># 百度一下,你就知道</span>
driver.quit()
if name == 'main':
foo()
如下报错是提示你没有勾选
selenium.common.exceptions.SessionNotCreatedException: Message: Could not create a session: You must enable the 'Allow Remote Automation' option in Safari's Develop menu to control Safari via WebDriver.
意思是:必须在Safari的“开发”菜单中启用“允许远程自动化”选项,才能通过WebDriver控制Safari。如果你之前设置了,这里以不会报错了。
IE回到顶部
必要的配置
- 在
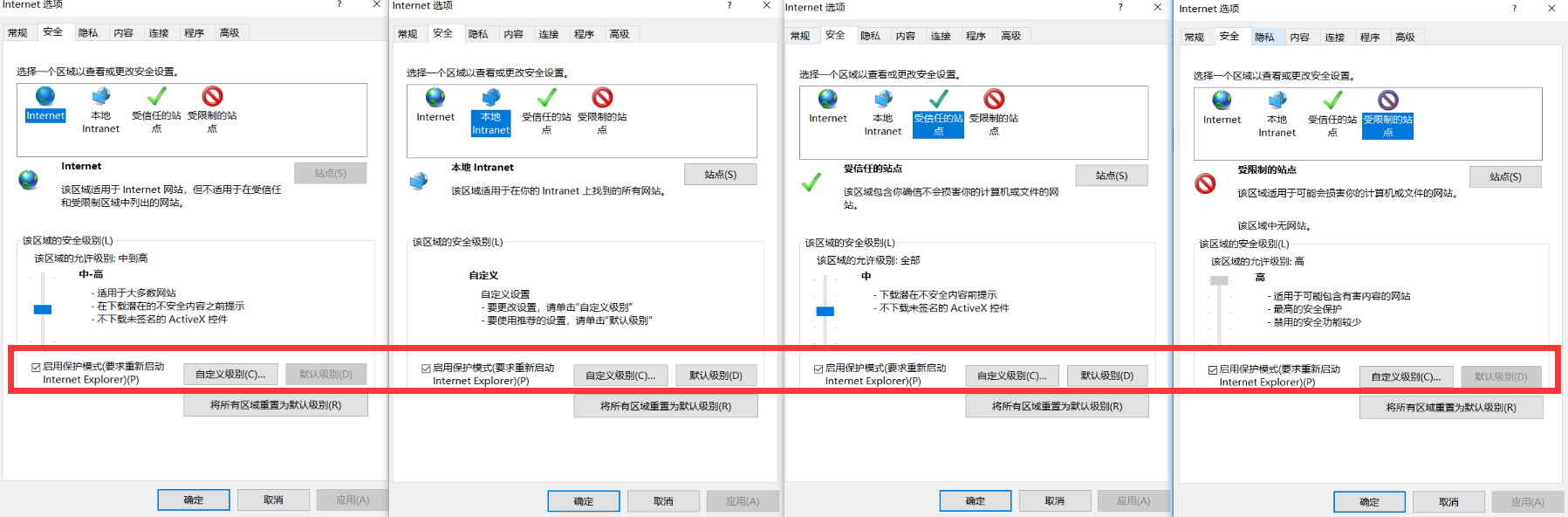
设置▶缩放中,将比例调整为100%。 - 在
设置▶Internet 选项▶安全选项,如下图,将四个选项都勾选启用保护模式。
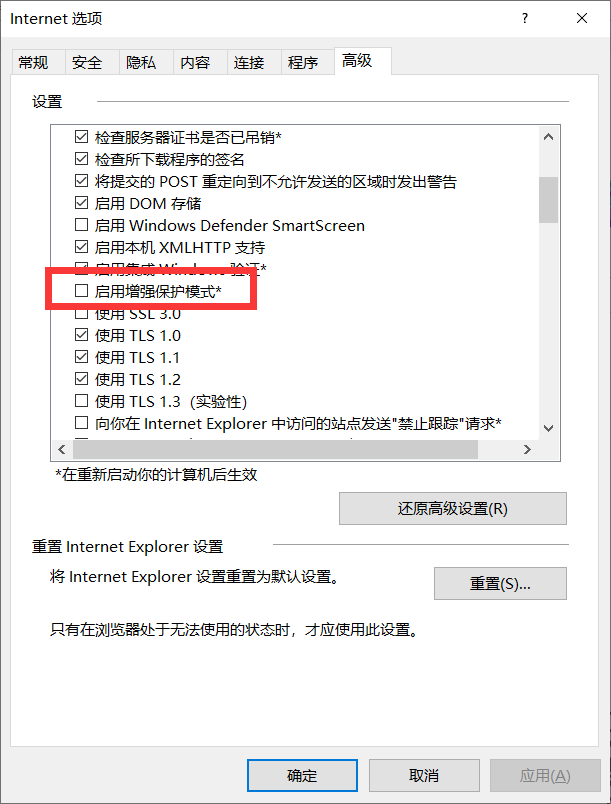
3. 针对IE10和更高的版本,必须在IE选项设置中的高级页中,取消增强保护模式。
重启IE浏览器。
webdriver驱动安装
- 由于IE的webdriver驱动依赖selenium模块的版本,所以,我们先来查看selenium模块的版本,这里我的selenium模块的版本是
Version: 3.141.0:
C:UsersAnthony>pip36 show selenium
WARNING: pip is being invoked by an old script wrapper. This will fail in a future version of pip.
Please see https://github.com/pypa/pip/issues/5599 for advice on fixing the underlying issue.
To avoid this problem you can invoke Python with '-m pip' instead of running pip directly.
Name: selenium
Version: 3.141.0
Summary: Python bindings for Selenium
Home-page: https://github.com/SeleniumHQ/selenium/
Author: UNKNOWN
Author-email: UNKNOWN
License: Apache 2.0
Location: c:python36libsite-packages
Requires: urllib3
Required-by: Appium-Python-Client
- 下载IE浏览器的webdriver驱动,访问http://selenium-release.storage.googleapis.com/index.html定位到跟selenium版本一致的链接并且进入该链接内。

- 这里一定要选择跟你的selenium版本一致的压缩包;另外,我的系统是64位的,但这里我选择32位的压缩包,原因是据不可靠消息,32位相对于64位性能更好!
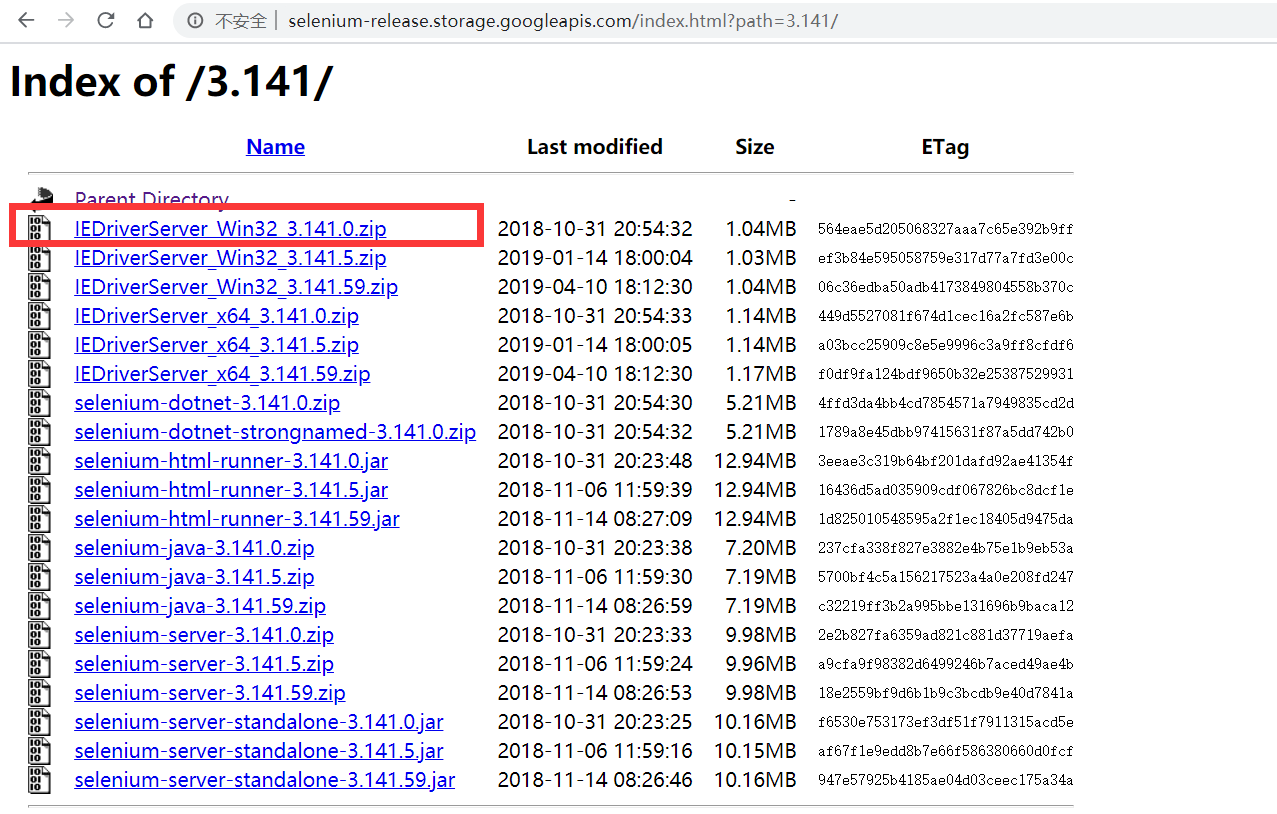
- 将
IEDriverServer.exe可执行文件拷贝到Python的安装目录中的Scripts目录内。

- 现在,可以测试了。
from selenium import webdriver
def foo():
"""
如果报如下错误:
selenium.common.exceptions.WebDriverException: Message: 'IEDriverServer.exe' executable needs to be in PATH. Please download from http://selenium-release.storage.googleapis.com/index.html and read up at https://github.com/SeleniumHQ/selenium/wiki/InternetExplorerDriver
原因是在执行时,没有在 path中找到驱动,这里的解决办法是实例化driver对象时,添加executable_path参数,引用驱动的绝对路径
"""
<span class="hljs-comment"># driver = webdriver.Ie(executable_path="C:Python36ScriptsIEDriverServer.exe") # 解决如上报错</span>
driver = webdriver.Ie() <span class="hljs-comment"># 解决如上报错</span>
<span class="hljs-comment"># driver = webdriver.Firefox()</span>
driver.implicitly_wait(time_to_wait=<span class="hljs-number">10</span>)
driver.get(<span class="hljs-string">'https://www.baidu.com'</span>)
print(driver.title) <span class="hljs-comment"># 百度一下,你就知道</span>
driver.quit()
if name == 'main':
foo()
无头浏览器回到顶部
我们日常使用浏览器的步骤为:启动浏览器、打开一个网页、进行交互。而无头浏览器指的是我们使用脚本来执行以上过程的浏览器,能模拟真实的浏览器使用场景。
有了无头浏览器,我们就能做包括但不限于以下事情:
- 对网页进行截图保存为图片或 pdf。
- 抓取单页应用(SPA)执行并渲染(解决传统 HTTP 爬虫抓取单页应用难以处理异步请求的问题)。
- 做表单的自动提交、UI的自动化测试、模拟键盘输入等。
- 用浏览器自带的一些调试工具和性能分析工具帮助我们分析问题。
- 在最新的无头浏览器环境里做测试、使用最新浏览器特性。
- 写爬虫做你想做的事情。
无头浏览器很多,包括但不限于:
- PhantomJS, 基于 Webkit
- SlimerJS, 基于 Gecko
- HtmlUnit, 基于 Rhnio
- TrifleJS, 基于 Trident
- Splash, 基于 Webkit
这里我们简单来说,在selenium中使用无头浏览器。
PhantomJS回到顶部
PhantomJS是一个无界面的、可脚本编程的WebKit浏览器引擎,其快速,原生支持各种Web标准: DOM 处理, CSS 选择器, JSON, Canvas, 和 SVG。
- PhantomJS是一个基于webkit内核、无界面的浏览器,即它就是一个浏览器,只是其内的点击、翻页等人为相关操作需要程序设计实现;
- PhantomJS提供Javascript API接口,可以通过编写JS程序直接与webkit内核交互;
- PhantomJS的应用:无需浏览器的 Web 测试、网页截屏、页面访问自动化、网络监测。
官网:https://phantomjs.org/
github:https://github.com/ariya/phantomjs/
下载安装
- 打开下载链接:https://phantomjs.org/download.html,根据自己的系统平台,下载相应的包,我这里是Windows 64位系统,所以,我选择下载windows版本的,phantomjs-2.1.1版本下载地址:
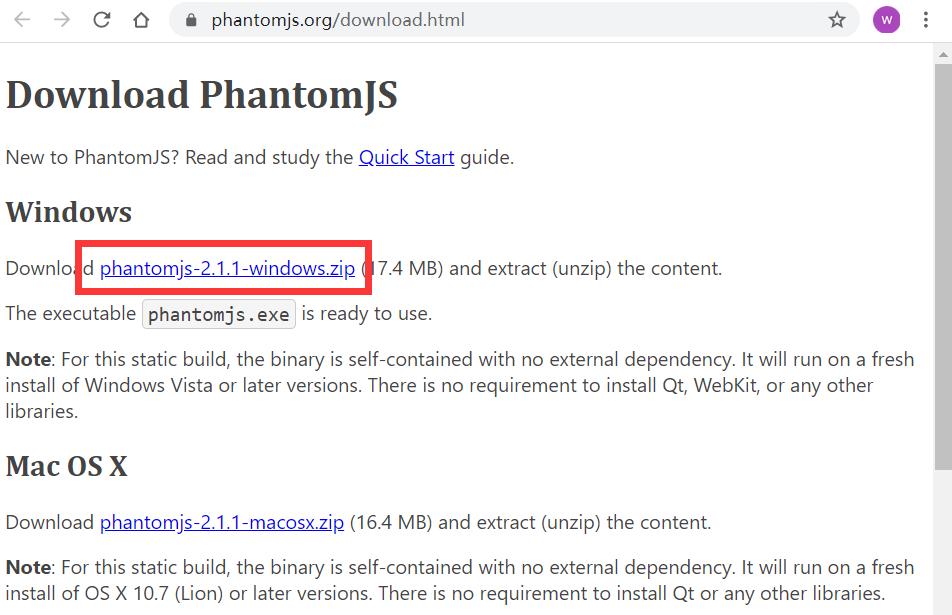
- 将压缩包解压到没有中文、空格的目录,我这里解压到Python的安装目录中的
Scripts目录。

- 将
phantomjs-2.1.1-windows的bin目录添加到系统path中。
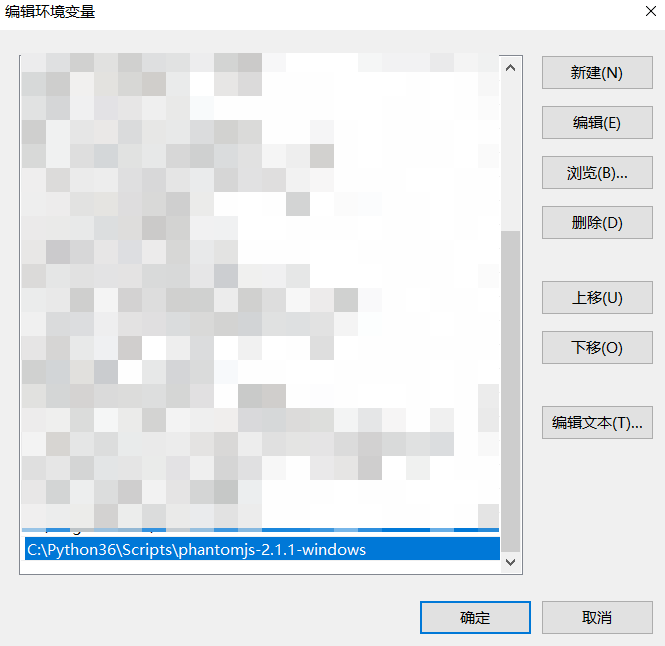
- 测试。
from selenium import webdriver
def foo():
"""
如果报如下错误:
selenium.common.exceptions.WebDriverException: Message: 'phantomjs' executable needs to be in PATH.
原因是在执行时,没有在 path中找到驱动,这里的解决办法是实例化driver对象时,添加executable_path参数,引用驱动的绝对路径
"""
driver = webdriver.PhantomJS(executable_path=<span class="hljs-string">r"C:Python36Scriptsphantomjs-2.1.1-windowsinphantomjs.exe"</span>) <span class="hljs-comment"># 解决如上报错</span>
driver.implicitly_wait(time_to_wait=<span class="hljs-number">10</span>)
driver.get(<span class="hljs-string">'https://www.baidu.com'</span>)
print(driver.title) <span class="hljs-comment"># 百度一下,你就知道</span>
driver.quit()
if name == 'main':
foo()
之前说 PhantomJS 和新版的selenium已经分手,所以你在使用的时候,会有这提示,注意,这是提示,不是报错!

解决办法!要么视而不见,要么按照提示去使用Google或者Firefox的无头浏览器吧。
Google无头回到顶部
自2017年中以来,Chrome用户可以选择以headless模式运行浏览器(chrome 59.0)。此功能非常适合运行前端浏览器测试,而无需在屏幕上显示操作过程。在此之前,这主要是PhantomJS的领地,但Headless Chrome正在迅速取代这个由JavaScript驱动的WebKit方法。Headless Chrome浏览器的测试运行速度要快得多,而且行为上更像一个真正的浏览器,虽然我们的团队发现它比PhantomJS使用更多的内存。有了这些优势,用于前端测试的Headless Chrome很可能成为事实上的标准。
所以,我们来看Google无头浏览器怎么玩的吧!毕竟这是以后无头浏览器阵营的扛把子!
说起来,Google的无头浏览器配置倒也简单,只需要要在实例化driver对象的时候,添加参数即可。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# 创建一个参数对象,用来控制chrome以无界面模式打开
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 创建浏览器对象
driver = webdriver.Chrome(chrome_options=chrome_options)
# driver = webdriver.Chrome() # 不加 chrome_options 参数就是正常的打开一个浏览器,进行操作
driver.implicitly_wait(10)
# 访问URL
driver.get('https://www.baidu.com')
print(driver.title) # 百度一下,你就知道
driver.quit()
Firefox无头回到顶部
Google搞了无头浏览器之后(2017年5月),小老弟Firefox也不甘落后,从 55.0 开始也支持了HEADLESS模式(2017年9月)。
配置也相当的简单。
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
# 创建浏览器对象
options = Options()
options.add_argument("-headless")
driver = webdriver.Firefox(firefox_options=options)
# driver = webdriver.Firefox() # # 不加 firefox_options 参数就是正常的打开一个浏览器,进行操作
driver.implicitly_wait(10)
# 访问URL
driver.get('https://www.baidu.com')
print(driver.title) # 百度一下,你就知道
driver.quit()
不得不说,大厂就是大厂,Google和Firefox的联手打压下,再加上PhantomJS的内部矛盾,导致在短短的几个月后(2018年4月),PhantomJS的核心开发者团队宣布不再维护该项目,老大哥终将落幕了啊!
哦,忘了说了,据不可靠消息说:
- Google无头相对于UI的浏览器节省30%左右的时间。
- Firefox无头相对于UI的浏览器节省3%左右的时间。
这话不是我说的,是:http://www.suchcode.com/topic/592/WebDriver测试的无头执行 - Firefox浏览器。
哦,还有,phantomjs 都不维护了,还讲它干嘛?那是因为我们可以在截网页长图的时候使用。暂时我还没有找到使用Chrome和Firefox截长图的办法!只能使用 phantomjs 了啊!