在老版本的ES(例如2.3版本)中, index的shard数量定好后,就不能再修改,除非重建数据才能实现。
从ES6.1开始,ES 支持可以在线操作扩大shard的数量(注意:操作期间也需要对index锁写)
从ES7.0开始,split时候,不再需要加参数 index.number_of_routing_shards
需要注意的是: 这个split的过程中, 它会先复制全量数据,然后再去做删除多余数据的操作,需要注意磁盘空间的占用。
具体参考官方文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.5/indices-split-index.html
https://www.elastic.co/guide/en/elasticsearch/reference/6.1/indices-split-index.html
split的过程:
1、创建一个新的目标index,其定义与源index相同,但是具有更多的primary shard。
2、将segment从源index硬链接到目标index。(如果文件系统不支持硬链接,则将所有segment都复制到新索引中,这是一个非常耗时的过程。)
3、创建低级文件后,再次对所有文档进行哈希处理,以删除属于不同shard的documents
4、恢复目标索引,就像它是刚刚重新打开的封闭索引一样。
为啥ES不支持增量resharding?
从N个分片到N + 1个分片。增量重新分片确实是许多键值存储支持的功能。仅添加一个新的分片并将新的数据推入该新的分片是不可行的:这可能是一个索引瓶颈,并根据给定的_id来确定文档所属的分片,这对于获取,删除和更新请求是必需的,会变得很复杂。这意味着我们需要使用其他哈希方案重新平衡现有数据。
键值存储有效执行此操作的最常见方式是使用一致的哈希。当分片的数量从N增加到N + 1时,一致的哈希仅需要重定位键的1 / N。但是,Elasticsearch的存储单位(碎片)是Lucene索引。由于它们以搜索为导向的数据结构,仅占Lucene索引的很大一部分,即仅占5%的文档,将其删除并在另一个分片上建立索引通常比键值存储要高得多的成本。如上节所述,当通过增加乘数来增加分片数量时,此成本保持合理:这允许Elasticsearch在本地执行拆分,这又允许在索引级别执行拆分,而不是为需要重新索引的文档重新编制索引移动,以及使用硬链接进行有效的文件复制。
对于仅追加数据,可以通过创建新索引并将新数据推送到其中,同时添加一个别名来覆盖读取操作的新旧索引,从而获得更大的灵活性。假设旧索引和新索引分别具有M和N个分片,与搜索具有M + N个分片的索引相比,这没有开销。
索引能进行split的前提条件:
1、目标索引不能存在。
2、源索引必须比目标索引具有更少的primary shard。
3、目标索引中主shard的数量必须是源索引中主shard的数量的倍数。
4、处理拆分过程的节点必须具有足够的可用磁盘空间,以容纳现有索引的第二个副本。
下面是具体的实验部分:
tips:实验机器有限,索引的replica都设置为0,生产上至少replica>=1
# 创建一个索引,2个主shard,没有副本
curl -s -X PUT "http://1.1.1.1:9200/twitter?pretty" -H 'Content-Type: application/json' -d' { "settings": { "index.number_of_shards": 2, "index.number_of_replicas": 0 }, "aliases": { "my_search_indices": {} } }'
# 写入几条测试数据
# 查询数据
# 对索引锁写,以便下面执行split操作
# 写数据测试,确保锁写生效
# 取消 twitter 索引的alias
# 开始执行 split 切分索引的操作,调整后索引名称为new_twitter,且主shard数量为8
# 对新的index添加alias
结果:
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "new_twitter"
}
补充:
查看split的进度,可以使用 _cat/recovery 这个api, 或者在 cerebro 界面上查看。
# 查看新索引的数据,能正常查看
# 对新索引写数据测试,可以看到失败的
# 打开索引的写功能
# 再次对新索引写数据测试,可以看到此时,写入是成功的
# 此时,老的那个索引还是只读的,我们确保新索引OK后,就可以考虑关闭或者删除老的 twitter索引了。
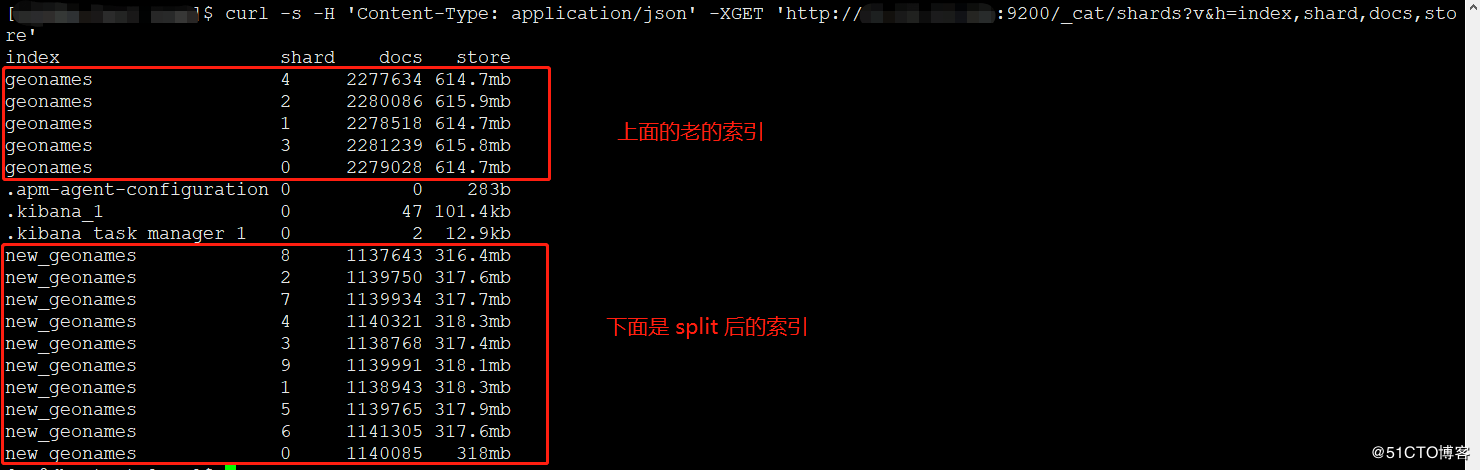
贴一张 生产环境执行后的index的截图,可以看到新的index的每个shard体积只有老index的一半,这样也就分摊了index的压力:
转自https://blog.51cto.com/lee90/2467377?source=dra