1. 前言
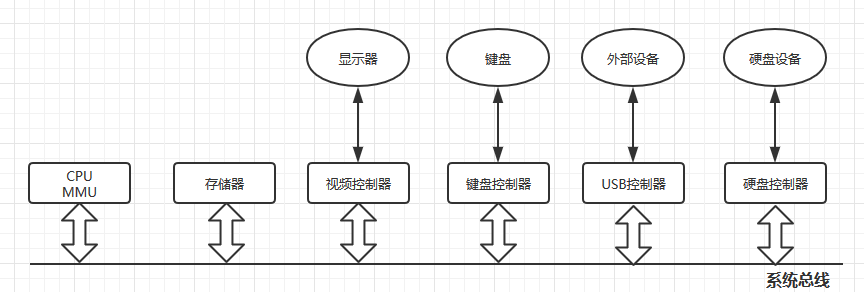
一台计算机是由一堆硬件设备组合而成,在硬件之上是操作系统,操作系统与计算机硬件密不可分,操作系统用来管理所有的硬件资源提供服务,各个硬件设备是通过 总线 进行连接起来的:
在操作系统之上,需要一个人机交互接口,我们才能使用计算机对其发送指令,这个人机交互接口就是 shell,如图:
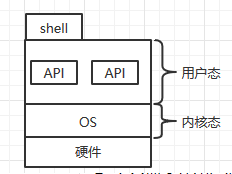
操作系统分为:
(1)用户态
(2)内核态
用户态和内核态都可以访问 CPU ,只有当用户态需要执行特权指令时,才进行 用户态 - 内核态的切换。内核模式只是为了支撑用户态为了完成某些操作的,操作系统能否产生生产力,通常是看程序是否在用户态占据了大量时间,内核模式是不产生生产力的。例如:1 + 1 只需要用户在 用户态执行。
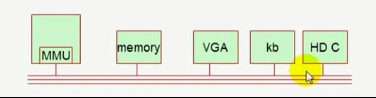
计算机五大部件:
运算器、控制器 - CPU (MMU 内存控制单元) - 内存分页(memory page)
存储器(Memory)
I/O设备(VGA、键盘、磁盘)
五大部件是通过总线连接:
2. CPU
CPU:从内存中取出指令并执行:
取指单元 - 解码单元 - 执行单元 需要三个时钟周期
cpu 作为计算机大脑,它从内存中取出指令并执行。在每个 cpu 基本周期内,首先从内存中取出指令,解码以确定其类型和操作数,在执行,然后再取指、解码并执行。
每个 cpu 都有一套可执行的专门指令集。所以 x86 处理器不能运行 arm 程序,而 arm 处理器也不能执行 x86 程序。
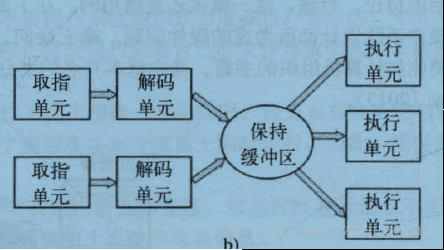
如上图,现在一般都是这种模式,其中有多个执行单元,例如:一个 CPU 用于布尔运算。两个或更多指令被同时取出、解码并装入暂存区中,直至它们执行完毕。只要有一个执行单元空闲,就检查保持缓冲区中是否还有可处理的指令,如果有,就把指令从缓冲区中移出并执行。
每个 CPU 中都有用来保存关键变量和临时数据的存储器,这些存储器通常被称为 CPU 的寄存器,指令计数器指令到下一个指令。操作系统必须清楚的明白每一个寄存器,进行上下文切换时,需要保存现场和还原现场。
保存和恢复现场都需要时间,现场是保存到内存中的, 上下文切换会花费大量时间。
CPU 主频是 cpu 内部的数字时钟信号频率,又称为 时钟频率(时钟频率:在 1 秒钟内,所能完成操作的个数)
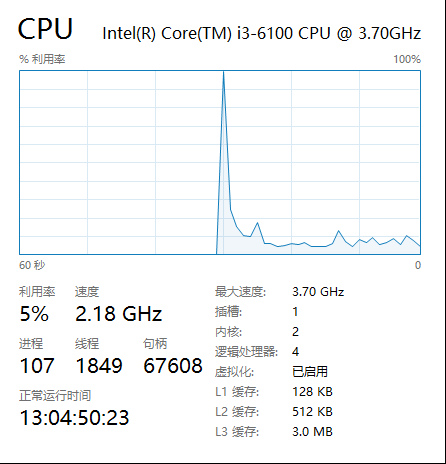
在这台主机上, 主频为:3.7GHz,意味着 一秒内可以产生 37亿次脉冲频率,所以说主频越高的处理器,性能越强劲。但是由于 cpu 内部结构复杂,一般主频越高产生的热量也越高,而 cpu 主频的提升到 4GHz 以上时,产生的热量将会非常高,长时间高温无法保证 cpu 将继续稳定的工作,cpu 热量越高会自动降频,因此想要继续提升 cpu 性能只能另寻他路,这就产生了 多核心、多线程的 CPU
多核心、超线程(多线程):
一颗 cpu 在某时刻可以运行两个线程,超线程模式;
一个进程在执行时只能用到一个 cpu 线程,通过程序的多个线程将指令在不同的 cpu 上执行(并行编程);
线程是共享进程所打开的文件描述符的,共享进程的所有资源。Linux 并非真正的线程操作系统,但是 Linux 的进程非常轻量级,每个线程在 Linux 内核看来仍然是一个进程。
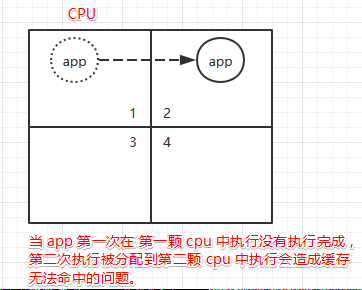
当一个程序第一次在 1号 cpu 执行时,没有执行完毕保存现场,第二次执行时,却在 2 号 cpu 上执行,会造成缓存没办法命中的问题。内核为了保证 cpu 核心是被负载均衡使用的,哪个cpu核心空闲,就在哪个 cpu 上执行。
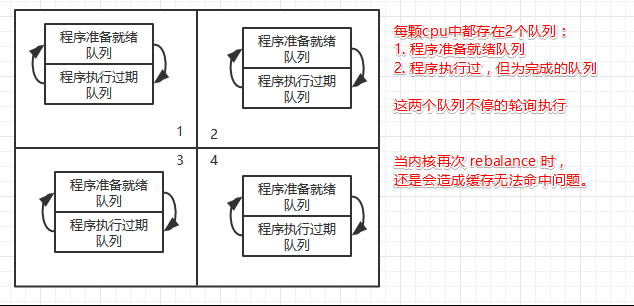
内核在管理 cpu 时,每个 cpu 都有 2 个执行进程的队列,等待进程的队列、过期队列,当等待进程队列执行完,在将两个队列反转执行,避免复制,内核会定期将 cpu 队列进行 rebalance ,但是会有一个问题,缓存命中的问题。
使用 cpu 亲和性可以提高进程的缓存命中。
对称多处理器:SMP
对称多处理器结构(SMP,Symmetric Multi-Processor)
服务器最开始是单CPU,然后才进化到了双 CPU 甚至多 CPU 的 SMP 架构。所谓 SMP 架构指的是 多路 CPU 无主次,共享内存、总线、操作系统等。此时每个 CPU 访问内存任何地址所耗费的时间是相等的,所以也称为 一致存储器访问结构。
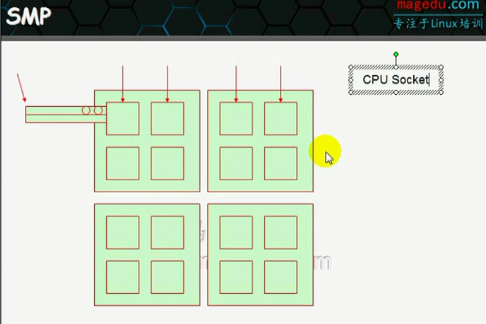
大家共享同样的内存,所以扩展能力有限,因为 cpu 数量增加了,内存访问冲突也会增加。为了进一步提高 cpu 数量的同时还能保证效率, NUMA 架构出现了, 将多个 SMP 进行松耦合。
非一致存储访问结构(NUMA, Non-Uniform Memory Access)
NUMA 架构中,多个 SMP 通过 Crossbar switch 交换矩阵进行互联。
每个SMP有自己的内存,同时还可以访问其他SMP 的内存,但是需要经过高速交换矩阵,很显然 SMP 访问自己的内存速度非常高,但是访问远程 SMP 的内存还需要经过交换矩阵,延迟增加,可以看出NUMA 通过牺牲内存的访问延迟来达到更高的扩展性。
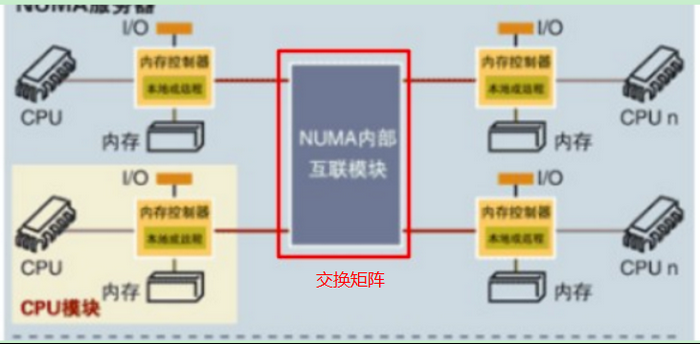
总之,SMP与NUMA架构对软件程序方面影响扩展性不大,一台主机内都使用单一的操作系统。缺点是CPU数量增加,访问远端内存的时延也会增加,性能不能线性增加。此时MPP架构就出现了。
海量并行处理结构:(MPP,Massive Parallel Processing)
MPP说白了就是将多台独立的主机组成集群。显然在此架构下,每个节点都有各自的CPU、内存、IO总线、操作系统,完全松耦合。最关键的是MPP集群中的软件架构也相应的改变了,这样MPP的效率随节点数量增加就可以线性增加了。MPP,可以理解为刀片服务器,每个刀扇里的都是一台独立的smp架构服务器,且每个刀扇之间均有高性能的网络设备进行交互,保证了smp服务器之间的数据传输性能。相比numa 来说更适合大规模的计算,唯一不足的是,当其中的smp 节点增多的情况下,与之对应的计算管理系统也需要相对应的提高。
SMP 和 NUMA 的区别:是否共享内存
SMP:
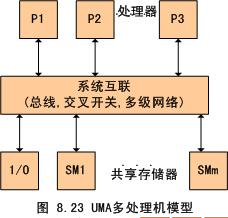
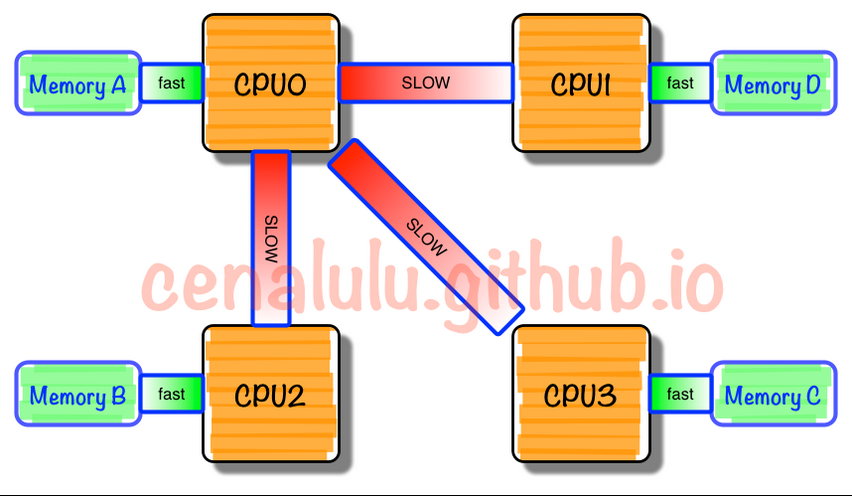
NUMA:
在NUMA架构下,如果通过上层软件来使得程序尽量少的读取远端的内存,NUMA效率也会线性增加。但是实际上NUMA操作系统仍然是同一个,内存仍然是全局均匀的,所以访问远端内存是不可避免的。

MMP:
将多个独立的 smp 架构系统组成集群,每个节点都有独立的 cpu、内存、IO总线、操作系统,完全松耦合。MMP 是通过节点高速互联进行交互。
3. 内存
早期的计算机内存,只有物理内存,而且空间是极其有限的,每个应用或进程在使用内存时都得小心翼翼,不能覆盖别的进程的内存区。
为了避免这些问题,就提出了虚拟内存的概念,其抽象了物理内存,相当于对物理内存进行了虚拟化,保证每个进程都被赋予一块连续的,超大的(根据系统结构来定,32 位系统寻址空间为 2^32,64 位系统为 2^64)虚拟内存空间,进程可以毫无顾忌地使用内存,不用担心申请内存会和别的进程冲突,因为底层有机制帮忙处理这种冲突,能够将虚拟地址根据一个页表映射成相应的物理地址。这种机制正是虚拟化软件做的事,也就是 MMU 内存管理单元。
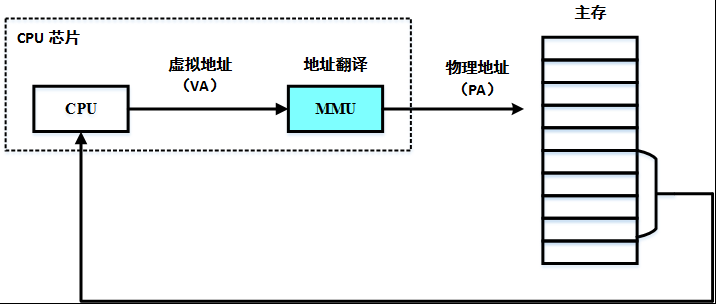
内存虚拟化也分为基于软件的内存虚拟化和硬件辅助的内存虚拟化,其中,常用的基于软件的内存虚拟化技术为 “影子页表”技术,硬件辅助内存虚拟化技术为 Intel 的 EPT(Extend Page Table,扩展页表)技术。
常规软件内存虚拟化
虚拟机本质上是 Host 机上的一个进程,按理说应该可以使用 Host 机的虚拟地址空间,但由于在虚拟化模式下,虚拟机处于非Root模式,无法直接访问Root 模式下的 Host 机上的内存。
这个时候就需要 VMM 的介入,VMM 需要 intercept (截获)虚拟机的内存访问指令,然后 virtualize(模拟)Host 上的内存,相当于 VMM 在虚拟机的虚拟地址空间和 Host 机的虚拟地址空间中间增加了一层,即虚拟机的物理地址空间,也可以看作是 Qemu 的虚拟地址空间(稍微有点绕,但记住一点,虚拟机是由 Qemu 模拟生成的就比较清楚了)。所以,内存软件虚拟化的目标就是要将虚拟机的虚拟地址(Guest Virtual Address, GVA)转化为 Host 的物理地址(Host Physical Address, HPA),中间要经过虚拟机的物理地址(Guest Physical Address, GPA)和 Host 虚拟地址(Host Virtual Address)的转化,即:
GVA -> GPA -> HVA -> HPA
其中前两步由虚拟机的系统页表完成,中间两步由 VMM 定义的映射表(由数据结构 kvm_memory_slot 记录)完成,它可以将连续的虚拟机物理地址映射成非连续的 Host 机虚拟地址,后面两步则由 Host 机的系统页表完成。如下图所示。
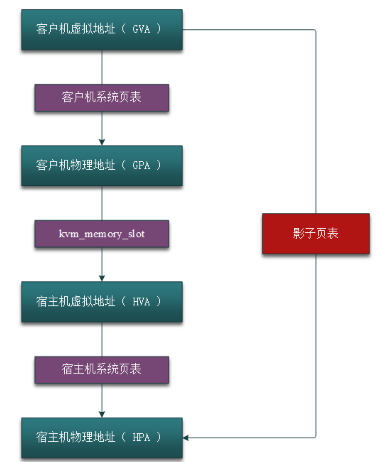
这样做的目的有两个:
(1)提供给虚拟机一个从零开始的连续的物理内存空间;
(2)在各虚拟机之间有效隔离、调度以及共享内存资源。
影子页表技术
接上图,我们可以看到传统的内存虚拟化方式,虚机每次内存访问都需要 VMM 介入,并由软件进行多次地址转换,其效率是非常低的。因此才有影子页表技术和EPT技术。
影子页表简化了地址转换的过程,实现了 Guest 虚拟地址空间到 Host物理地址空间的直接映射。要实现这样的映射,必须为 Guest 的系统页表设计一套对应的影子页表,然后将影子页表装入 Host 的 MMU 中,这样当 Guest 访问 Host 内存时,就可以根据 MMU 中的影子页表映射关系,完成 GVA 到 HPA 的直接映射。而维护这套影子页表的工作则由 VMM 来完成。
由于 Guest 中的每个进程都有自己的虚拟地址空间,这就意味着 VMM 要为 Guest 中的每个进程页表都维护一套对应的影子页表,当 Guest 进程访问内存时,才将该进程的影子页表装入 Host 的 MMU 中,完成地址转换。
我们也看到,这种方式虽然减少了地址转换的次数,但本质上还是纯软件实现的,效率还是不高,而且 VMM 承担了太多影子页表的维护工作,设计不好。为了改善这个问题,就提出了基于硬件的内存虚拟化方式,将这些繁琐的工作都交给硬件来完成,从而大大提高了效率。
EPT 技术
这方面 Intel 和 AMD 走在了最前面,Intel 的 EPT 和 AMD 的 NPT 是硬件辅助内存虚拟化的代表,两者在原理上类似,本文重点介绍一下 EPT 技术。
如下图是 EPT 的基本原理图示,EPT 在原有 CR3 页表地址映射的基础上,引入了 EPT 页表来实现另一层映射,这样,GVA->GPA->HPA 的两次地址转换都由硬件来完成。
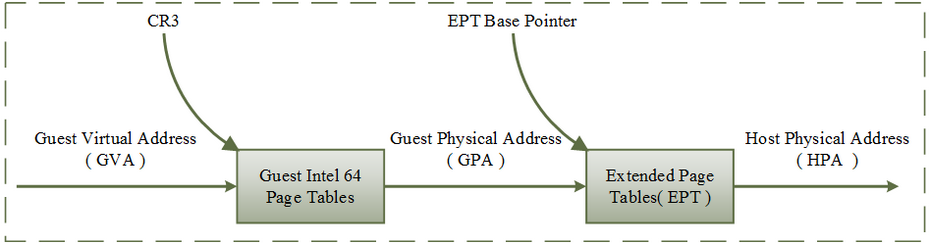
这里举一个小例子来说明整个地址转换的过程。假设现在 Guest 中某个进程需要访问内存,CPU 首先会访问 Guest 中的 CR3 页表来完成 GVA 到 GPA 的转换,如果 GPA 不为空,则 CPU 接着通过 EPT 页表来实现 GPA 到 HPA 的转换(实际上,CPU 会首先查看硬件 EPT TLB 或者缓存,如果没有对应的转换,才会进一步查看 EPT 页表),如果 HPA 为空呢,则 CPU 会抛出 EPT Violation 异常由 VMM 来处理。
如果 GPA 地址为空,即缺页,则 CPU 产生缺页异常,注意,这里,如果是软件实现的方式,则会产生 VM-exit,但是硬件实现方式,并不会发生 VM-exit,而是按照一般的缺页中断处理,这种情况下,也就是交给 Guest 内核的中断处理程序处理。
在中断处理程序中会产生 EXIT_REASON_EPT_VIOLATION,Guest 退出,VMM 截获到该异常后,分配物理地址并建立 GVA 到 HPA 的映射,并保存到 EPT 中,这样在下次访问的时候就可以完成从 GVA 到 HPA 的转换了。