SparkContext将应用程序代码分发到各Executors,最后将任务(Task)分配给executors执行
- Application: Appliction都是指用户编写的Spark应用程序,其中包括一个Driver功能的代码和分布在集群中多个节点上运行的Executor代码
- Driver: Spark中的Driver即运行上述Application的main函数并创建SparkContext,创建SparkContext的目的是为了准备Spark应用程序的运行环境,在Spark中有SparkContext负责与ClusterManager通信,进行资源申请、任务的分配和监控等,当Executor部分运行完毕后,Driver同时负责将SparkContext关闭,通常用SparkContext代表Driver
Driver重点:创建和关闭sparkcontext.
- Executor: 某个Application运行在worker节点上的一个进程, 该进程负责运行某些Task, 并且负责将数据存到内存或磁盘上,每个Application都有各自独立的一批Executor, 在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutor Backend。一个CoarseGrainedExecutor Backend有且仅有一个Executor对象, 负责将Task包装成taskRunner,并从线程池中抽取一个空闲线程运行Task, 这个每一个oarseGrainedExecutor Backend能并行运行Task的数量取决与分配给它的cpu个数
excutor重点:某个Application运行在worker节点上的一个进程,该进程负责运行某些Task,运行Task的数量取决与分配给它的cpu个数。
Work为子节点。
Job:根据Job构建基于Stage的DAG
Stage:多个taskset(task集合)
Task:执行的任务的最小单位。
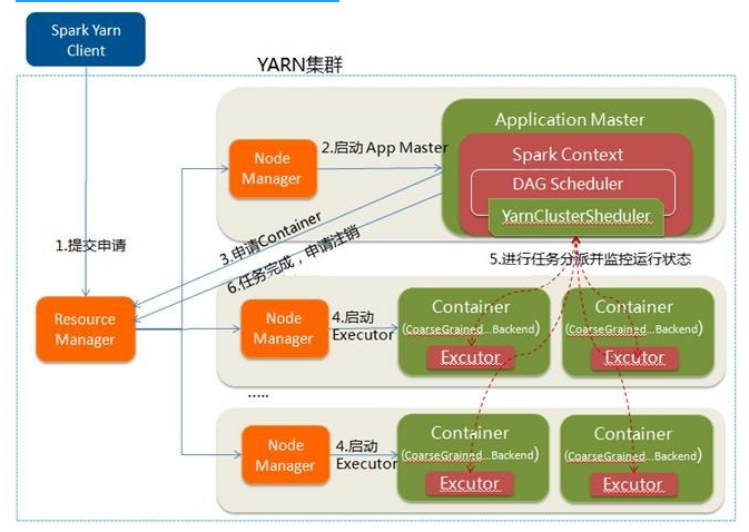
Spark Cluster模式:
- 在YARN-Cluster模式中,当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:
- 第一个阶段是把Spark的Driver(创建sparkcontext,构建环境)作为一个ApplicationMaster在YARN集群中先启动;
- 第二个阶段是由ApplicationMaster创建应用程序,然后为它向ResourceManager申请资源,并启动Executor来运行Task,同时监控它的整个运行过程,直到运行完成
- YARN-cluster的工作流程分为以下几个步骤
待续