前言
最近在进行性能调优的时候, 碰到了这样的一段代码(为了展示问题而简化的代码):
<?php
// 第一次运行
$start = microtime(true);
for ($i = 0; $i < 100; $i++) {
for ($j = 0; $j <1000; $j++) {
for ($k = 0;$k < 10000; $k++) {
}
}
}
$end = microtime(true);
echo 'first time is ', PHP_EOL;
echo $end - $start, PHP_EOL;
// 第二次运行
$start = microtime(true);
for ($i = 0; $i < 10000; $i++) {
for ($j = 0; $j <1000; $j++) {
for ($k = 0;$k < 100; $k++) {
}
}
}
$end = microtime(true);
echo 'second time is ', PHP_EOL;
echo $end - $start, PHP_EOL;
其中的两次运行操作基本一致, 均完成了十亿次循环. 按理说他们的运行时间应该是一样的呀. 但是, 浅看结果:
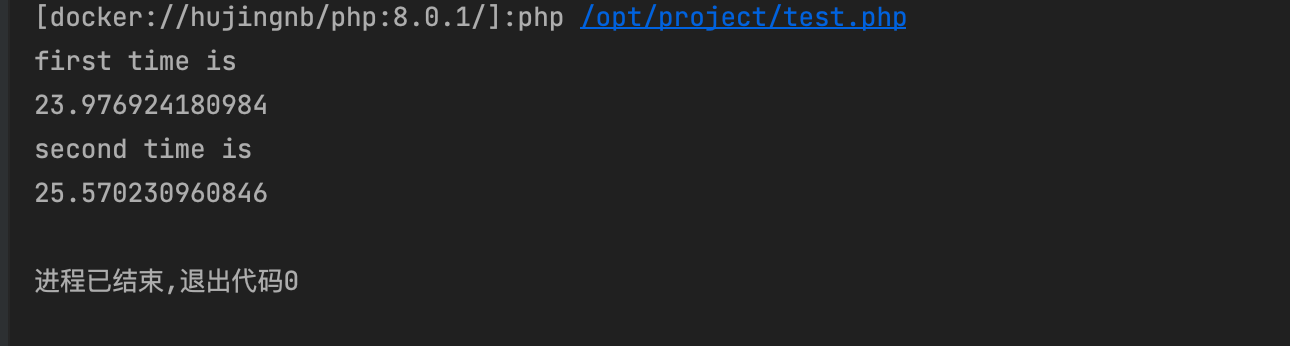
虽然每次运行的时间都不一样, 但是, 第二种方式每次都要比第一种多出来2-3秒.
what? why? 于是我想, 有没有可能是运行顺序的原因. 因此我将第二种放到前面运行, 结果也相应的颠倒了.
因此, 得出结论. 多层遍历时, 相比于由大到小(外圈大, 内圈小), 由小到大要运行的快一些. 上一边子去, 这算哪门子结论. 作为一个文化人, 自然要知道为什么会出现这种现象.
解释
为了进行揭秘, 我将代码改造了一下, 通过C来查看, 毕竟C程序可以直观的看到汇编结果. 测试程序如下:
#include "stdio.h"
#include "sys/time.h"
int main(){
struct timeval t;
int n;
long startTime, endTime;
// 第一次运行
gettimeofday(&t,NULL);
startTime = t.tv_sec * 1000 + t.tv_usec / 1000;
n = 0;
for (int i=0; i < 100; i++) {
for(int j = 0; j < 1000; j++){
for (int k = 0; k < 10000; k++){
n++; // 为了防止 CPU 优化, 在循环中做了自增的操作
}
}
}
gettimeofday(&t,NULL);
endTime = t.tv_sec * 1000 + t.tv_usec / 1000;
printf("first use time: %ld\n", endTime - startTime);
// 第二次运行
gettimeofday(&t,NULL);
startTime = t.tv_sec * 1000 + t.tv_usec / 1000;
n=0;
for (int i=0; i < 10000; i++) {
for(int j = 0; j < 1000; j++){
for (int k = 0; k < 100; k++){
n++;
}
}
}
gettimeofday(&t,NULL);
endTime = t.tv_sec * 1000 + t.tv_usec / 1000;
printf("second use time: %ld\n", endTime - startTime);
}

结果确实是第二种方式要慢上一些. 这里顺带提一句, 相同的操作, PHP程序跑了20多秒, C程序只用了不到2秒, 而且还进行了变量自增的操作. 果然, 脚本语言的性能还是差点意思啊.
我使用C编写程序, 另一个原因是为了验证这不是PHP语言特有的问题, 以进一步确认查找问题的方向.
好, 废话不多说, 经过多方查找, 最终晓得了为什么. 要解释这个现象, 还要从CPU的运行说起.
CPU 流水线
对于CPU的流水线不做深入解释, 简单过一下了.
CPU在执行指令的时候, 要经过多个步骤, 下面是一个简化的步骤:
- 取指令
- 指令译码
- 执行指令
- 输出结果
如果说, CPU为了充分利用时钟周期, 不让其空闲, 将流程改造成了一条流水线, 既取指操作将结果交给译码器之后, 不会等待指令执行结束, 而是立即读取下一条指令, 以提高执行效率. 跑起来大概就是这样:

在同一时间, 多个流水线部件同时工作.
对于CPU的工作流水线, 还有一些问题, 比如指令的依赖, 下一条指令的输入是上一条指令的输出 等等问题, 在这篇文章中按下不表.
指令预测
好, 现在知道了CPU是通过流水线执行的. 但这个流水线碰到比较的跳转指令就不好使了.
比如有一个条件判断指令, 若为真则跳转到 B 执行, 否则继续执行. 此时, CPU这条流水线如何处理呢? 碰到这种情况不进行处理, CPU空转等待下一条指令也是可以的. 但是还是有些浪费CPU性能.
假设条件判断的两种情况概率各50%, CPU也可以假设条件判断后继续执行, 若预测正确, 则皆大欢喜. 若预测错误, 将预先执行的操作销毁后重新执行即可. 这样, 只要销毁的操作开销不大, 就可以提高整体性能.
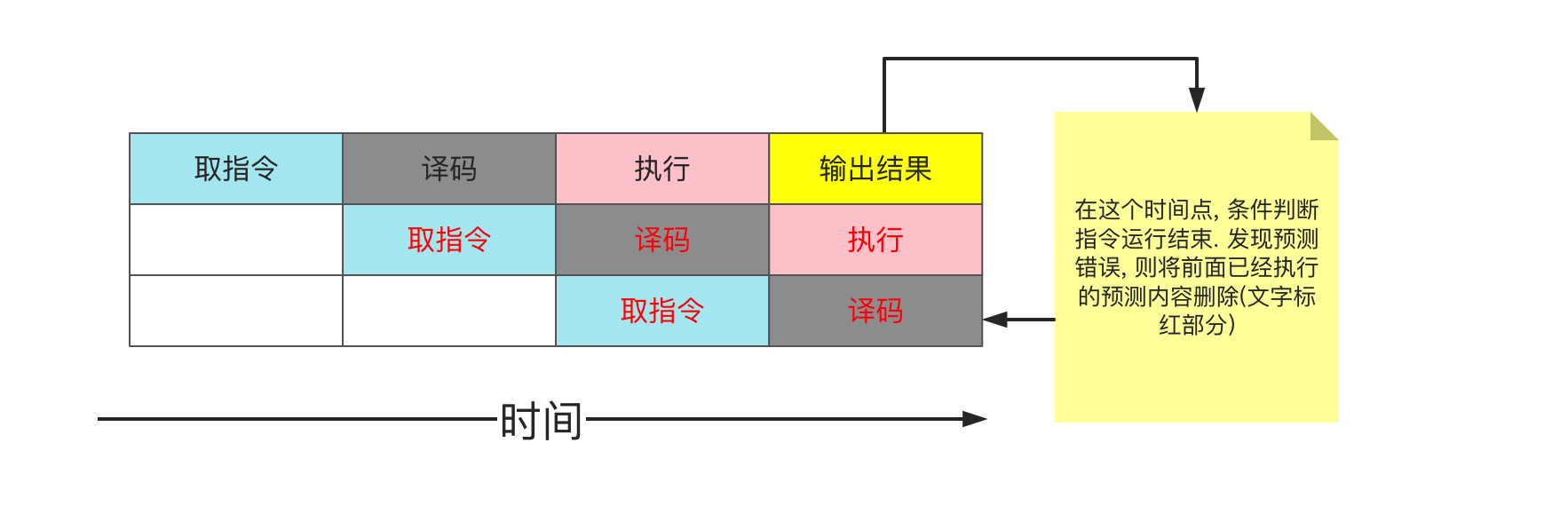
但是, 前辈们对于50%的预测成功概率是不能满足的. 因此又提出了动态预测, 也就是说依据历史来进行预测, 若上一次为真, 则本次为真, 若上次为假, 则本次为假. 如此可将预测成功率提高至90%. (现代CPU 的预测实现会更复杂一些)
对于指令的预测详情可查看维基百科的解释: 分支預測器
for 指令实现
在有了CPU指令预测概念后, 我们通过一段小小的C程序, 来看一下for循环是如何实现的:
int main(){
int n = 0;
for (int i=0; i < 100; i++) {
n++;
}
}
通过命令查看其汇编结果
gcc -g for-simple.c && objdump -dSl ./a.out
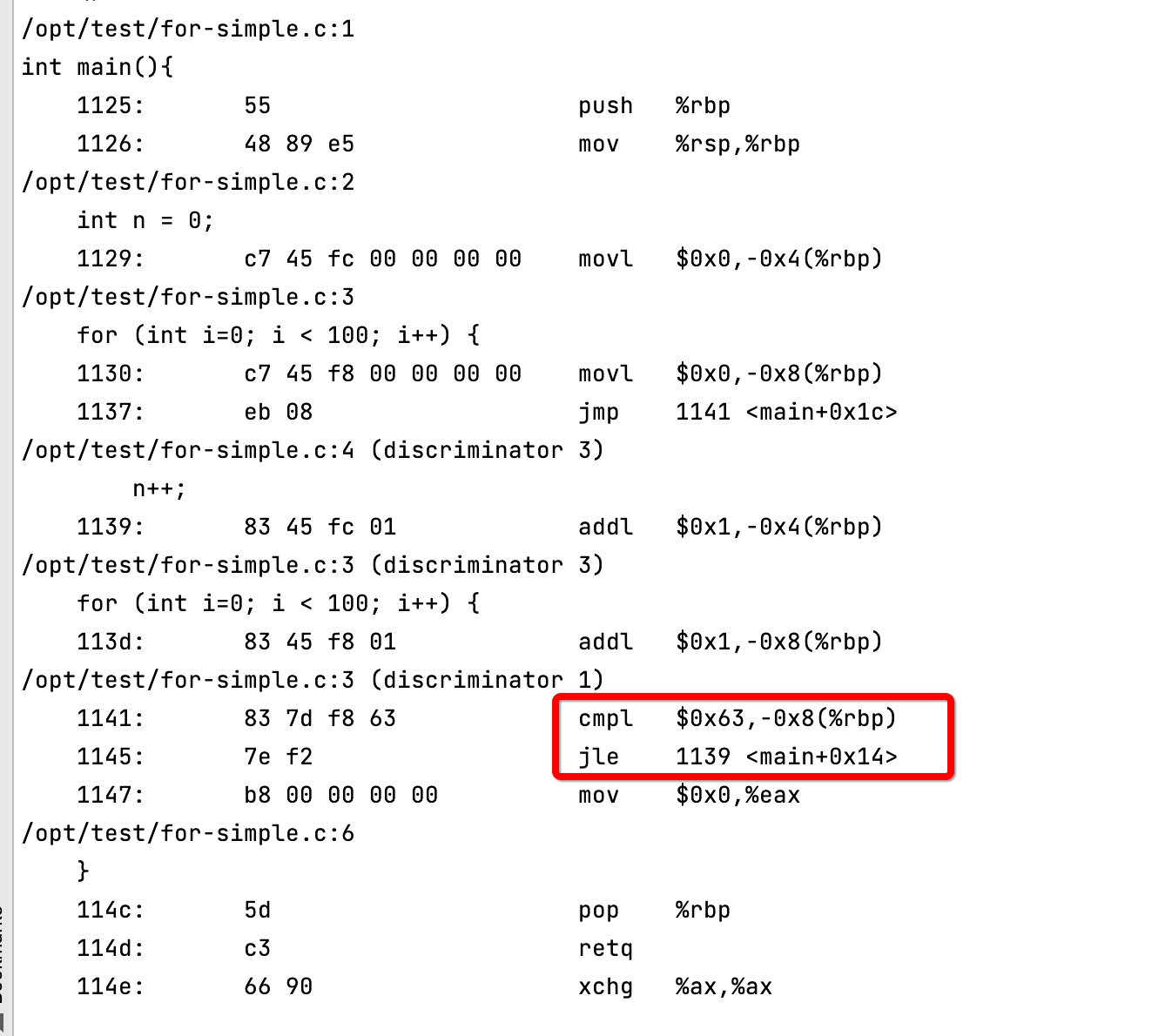
这就是用来实现for循环遍历的逻辑了. 113d步将i变量加一, 然后红框部分判断i<100, 若成立则跳转到1139继续执行.
也就是说, 在1145这个地方, 发生了我们上面所述分支预测的情况. 既在for循环结束时, 判断是回到开始位置继续遍历, 还是继续执行, 此时需要进行预测. 按照我们前面的推论, CPU按照动态预测, 根据历史进行预测. 则前99次结果均相同, 继续循环, 最后一次退出循环时预测失败. 对于一次普通的for循环, 预测失败仅1次. 成功率还是蛮高的哈.
解惑
好, 现在已经准备充分, 可以回过头来重新看看我们前面的例子, 对于这样的一个循环(动态预测方式):
int main(){
for (int i=0; i < 100; i++) {
for(int j = 0; j < 1000; j++){
for (int k = 0; k < 10000; k++){
// CPU 在这里进行分支预测, 仅最后一次预测失败. 共失败1次
}
// CPU 在这里进行分支预测, 共失败999次, 最后一次成功
// 因为上一次第三层循环退出, 因此本次预测退出循环, 但结果继续第二层循环
}
// CPU 在这里分支预测, 共失败99次
}
}
(这里为了方便计算, 上面的99都近似为100进行计算了, 否则数字根本没法看)
则, 共预测失败100*1000*1=10^5次.
再计算一下, 若最外层循环10000次呢? 则会预测失败: 10000*1000*1=10^7次.
前面也提到了, 当预测失败时, 需要将预测的已执行内容销毁, 占用些许的CPU时钟周期. 同时被销毁的已执行内容也已经消耗了时钟周期. 因此, 相同的逻辑, 预测失败次数多的, 相应其耗时就会增加.
简单了解一下, 果然, 任何一个不平常的现象后面, 都有其出现的原因.