1 Practical aspects of Deep Learning
1.1 Train/Dev/Test sets
在小样本的机器学习中,可以分为60/20/20。
在大数据训练中,不需要划分很多的开发集和测试集。假如共有一百万数据,可以只取其中1万条作为开发集,1万条作为测试集。剩下的作为训练集。
某些时候会没有开发集。但是这么叫不确切,应该成为没有测试机。
注意:这里的train/dev/test应该是同一个数据集里。例如图片什么的需要相同的分辨率。
1.2 bias/variance问题
通过train和dev的错误率判断模型的high bias和high variance问题
判断建立在人能做到的最优误差(optimal error)上
high bias:
训练集误差远大于最优误差
high variance:
开发集误差远大于最优误差
high bias & high variance
两者都远大于最优误差
1.3 Basic Recipe for Machine Learning
机器学习(改进的)基本方法
先解决high bias,再解决high variance,当两者都不高时,就改进好了。
1.3.1 解决high bias
- 更复杂的网络
- 更长的训练时间
- 改变网络结构
1.3.2 解决high variance
- 更多的数据
- regularization(规范化)
- 改变网络结构
1.3.3 关于权衡两者
过去的机器学习方法由于运算量或数据量需要权衡,需要权衡bias和variance。
现在的方法不需要权衡你可以同时拥有更大的网络、和更多的数据
1.4 Regularization(正则化)
1.4.1 逻辑回归
L2正则化
L1正则化
L1能让某些w为零,使模型稀疏。但是作用不大。L2是最最常用的
实际使用也可以加上b的规范化。逻辑回归只对w规范化,因为w个数多,b只有一个,可以忽略掉。加上之后计算比较麻烦。
1.4.2 神经网络
L2正则化
每层中,每个w平方求和
加入这个函数后梯度计算
L2正则化也被称为权重衰减,因为加入约束时,将在梯度更新时让w更小些。从下式可以看出。
dropout正则化:见1.6
1.5 为什么正规化能防止过拟合
两种思考方式:
1.5.1 从网络结构上思考
如果参数λ十分大,会使得许多w变为0(实际上是一个非常接近0的数字),就会使得网络被大大简化,变为欠拟合。
λ设置正好,则网络会拟合的刚刚好
1.5.2 从激活函数上思考
假如激活函数是tanh,当w很小时,z很小,那么在tanh上0的附近,函数接近线性。网络就可以类比为使用线性激活函数。网络也很简单,不会过拟合。
1.5.3 注意
在观察J和迭代次数的曲线时,J的方程需要包含正规化项
1.6 dropout正则化
对于一个测试样本,在隐层的每一个节点,以一定的概率,随机的丢弃某些节点,形成简单的网络进行训练。
1.6.1 实现
第一步,产生辅助变量d[l]表示节点的丢弃/保留
随机生成一个0-1之间均匀分布的辅助变量d[l],并以keep_prob概率保留。小于为1,大于为0。最终d[l]将会是一个只有0、1的数组。
第二步,使用d[l]丢弃部分节点。
a[l]_new = a[l]*d[l]
第三部,是最终结果缩放到没有丢弃的同一尺度
a[l]_new /= keep_prob
因为丢弃了部分节点,最终数据将为原始数据的keep_prob倍。除了之后缩放会原来的尺度。
1.6.2为什么dropout有用
因为dropout的存在,对于一个神经元来说,前一层每一个输入都可能消失,变得不可靠。所以需要将权重分在各个神经元,而不是集中在其中一个。所以产生了类似正则化的效果。但是dropout和正则化还是有一点不同的。
没懂(2:00部分):But it turns out that drop out can formally be shown to be an adaptive form without a regularization. But L2 penalty on different weights are different, depending on the size of the activations being multiplied that way
1.6.3 注意
同一个样本,不同训练次数每次都随机
测试集不要使用dropout,也不需要再缩放
在前向,反向传播时,使用同一个d[l]
输入、输出层不使用dropout
不同的层可以根据可能过拟合的概率,设置不同的keep_prob。对于有可能过拟合的层,keep_prob设置低一点。
dropout是解决过拟合问题的,如果没有过拟合问题,可以不使用。在cv领域是个必备的,因为cv领域数据特别多。
当设置了dropout后,J和迭代次数的关系将变化,不会一直下降。给debug带来困难,可以先将所有dropout设置为1进行调试 ,判断其他地方程序没有问题。
1.7 其他防止过拟合方法
1.7.1 扩增数据集
收集更多的数据
将当前数据集进行旋转、对称等扩增
1.7.2 early stopping(早停)
在画迭代次数和J的曲线是,同时画训练集和开发集的曲线,当开发集上升时,就提前停止迭代。
早停有好处是因为当初始化时w很小,过拟合时w很大。停止点会有一个中等大小的w。
早停会引入一些耦合问题,但是也有不需要从不同λ中选择的好处。
总的来说,更推荐使用L2正则化方法
1.8 Normalization(归一化)
1.8.1 定义
将x减去平均值,移动到0点附近。再归一化方差。
其中(sigma^2=frac{1}{m}sum_{i=1}^{m}(x^{[i]})^2)是归一化方差
1.8.2 作用
因为归一化之后每个维度范围差距不会很大,有利于梯度下降方法等方法来优化代价函数。
如果每个特征大小差距不大,使用归一化没有太大改进,但是不会有坏处,所以可以无脑使用
1.9 梯度消失/爆炸
当w和单位阵I不同时,当经过很多层之后,梯度会变成指数倍,将变得很大或很小。这就是梯度消失或爆炸,这会造成梯度下降算法低效。
使用特别的初始化权重方法可以解决这个问题。例如Xavier initialization。
在初始化时,将随机初始化权重再乘以一个附加项。不同的激活函数的附加项不同。
可以将这个初始化作为超参数调节,但是优先级应该很低。
1.10 梯度检验
使用梯度的数值解和反向传播的解进行比较,判断程序是否正确。
数值解其实就是导数,定义如下。
具体实现是,将原来的(J(w,b))中的w和b放在一起,认为是一个参数( heta),求解(J( heta))的导数,和反向传播的导数比较。比较两个的欧式距离。
对于这个式子,分子是两个值的欧氏距离,分母是为了预防这些向量太大或太小,使方程变成比率。
实际中如果计算出来的值小于(10^{-7})说明导数逼近可能是正确的。
如果在(10^{-5})范围,可能要去检查所有相,确保没有一项误差过大。
如果在(10^{-3})范围,仔细检查是否有bug。需要根据每个θ来找bug。
1.11 梯度检验需要注意事项
只有debug时才进行梯度检查
debug时,看是哪部分的梯度差距很大,找到对应的层,找问题
计算梯度时,记得规范化项也需要求导
不要和dropout同时使用。dropout会使得J的计算苦难。实际使用中,可以先将keep-pro设置为1.
有时梯度计算可能只在参数接近0时正确,可以在几次迭代后再进行梯度检验。
1.12 What is L2-regularization actually doing?
L2-regularization relies on the assumption that a model with small weights is simpler than a model with large weights. Thus, by penalizing the square values of the weights in the cost function you drive all the weights to smaller values. It becomes too costly for the cost to have large weights! This leads to a smoother model in which the output changes more slowly as the input changes.
L2正则化建立再认为小权重的网络比大权重简单。因此,当在代价函数里惩罚权重平方和,会使得权重变小。会使得当输入变化时,输出的变化会变小变平缓。
2 Optimization algorithms
2.1 Batch vs Mini-batch
Batch:一次使用所有m个数据进行训练
Mini-batch:将m个数据按照划分为多份,一次一份数据进行训练。使用上标{t},来表示第t份数据
Mini-batch是深度学习常用的方法,能够加快训练的速度。
2.2 迭代次数和J的曲线
batch:J持续下降
mini-batch:J会波动,但是整体趋势是下降的。因为J是在不同的小训练集上的,可能某个小训练集简单,某个小训练集难,就造成了波动。
2.3 选择mini-batch大小
当size = m就变成 batch。缺点:运算时间过长
当size = 1就变成随机梯度下降(stochastic gradient descent)。计算上有噪声,但是不影响收敛。缺点:失去了矢量化带来的优势
实际中一般在1-m之间,优点:使用矢量化的优势,计算比较快;而且不需要等待所有m个样本都训练完。
2.3.1 选择方法
训练集为小样本(m < 2000):batch
训练集为大样本:mini-batch.一般为2的倍数。(64-128-256-512...),并且需要适合cpu/gpu的存储,计算过程中不能超出存储。
2.4 Exponentially weighted averages(指数加权平均)
2.4.1 定义
例如,对( heta(t))进行指数加权平均
(v(t))可以理解为前(frac{1}{1-β})天的数据
(β = 0.90)为前10天,(β = 0.98)为前50天,(β = 0.5)w为前两天。增大β会使曲线平缓,并向右移动。减小β则陡峭,变换迅速些。
这种方法是近似的平均,但是计算上十分简单。一行代码。
v = beta*v + (1-beta)*theta
2.4.2 理解
展开这个式子,如下式。每个θ乘的是一个指数下降的内容。
当在第(frac{1}{1-β})项后,指数项将小于(frac{1}{e}),比较小,近似认为没有作用。所以近似是前(frac{1}{1-β})项的平均。
2.4.3 Bias correction
直接使用指数加权平均,前几项会从很接近0的数开始。不真实反应数据
使用下式修正。最开始有作用,可以修正。但当t很大时,分母接近0,几乎没有作用了。
在机器学习中,一般不在乎初期的偏差。如果你关心的话,可以使用偏差修正。
2.5 Momentum(动量)
定义:计算梯度的指数加权平均,然后使用这个梯度来更新权重
目的:加速直向目标方向的速度,减慢垂直方向的速度
实现:
实际中这个方法不需要bias correction,经过几个循环就会步入正轨,仅仅前几个周期较接近0
实际中β=0.9是个普遍默认选择
直观体验,蓝色为原始,红色为添加momentum,紫色为α过大发散。动量方法使得在垂直方向上变小,就可以使用更大的学习率了。
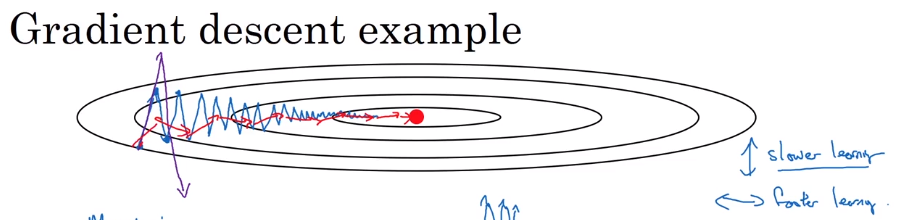
2.6 RMSprob(均方根传递)
定义:计算梯度的均方根相关的东西,然后使用这个更新权重
目的:在梯度下降方法时,加速/保持当前点在指向最优值的方向速度,减慢垂直于最优质方向的速度
实现:
备注:(varepsilon)为了防止分母为0,一般设置很小,例如(varepsilon=10^{-8})。
直观体验如下,(w)是希望变快的方向,(b)是希望减慢的方向。可以看出,(w)方向数值较小,(b)方向数值较大。就是说(s_{dw})较小,(s_{db})较大。所以(dw)除以较小的数会使其不变或者变大,加速/保持(w)方向速度。而(db)除以较大的数,会使其变小,减慢(b)方向的速度。最终造成图中绿色的效果。正因为这样,可以加大学习率,加速算法收敛,还不怕发散。
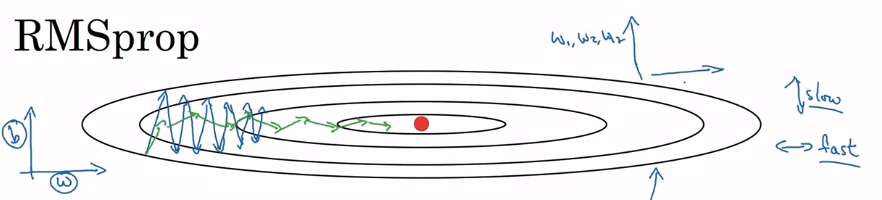
2.7 Adam(Adaptive Moment Estimation 自适应矩估计)
可以大范围使用的优化方法。
将momentum和rms放在一起。需要使用bias correction
超参数选择:需要调α,剩下的使用默认值就好。
2.8 learning rate decay(学习率衰减)
如果学习率不变,优化算法无法收敛,在接近最优值时较远的附近徘徊。
如果学习率在接近过程中慢慢衰减,可以做到一开始收敛的很快,接近最优值时能在最优值很近很近的地方徘徊。
epoch:在所有的数据上训练一遍
方法:
其他方法:
或者每隔一段时间α减半,离散衰减
或者人为设定衰减
吴心得:α在调试时会有巨大影响,衰减率影响的优先级很低
2.9 local optima
在深度学习中,更容易碰到的时鞍点(saddle point),而非局部最优点。局部最优点需要在每一个维度都是(局部)最优点,出现概率很低。
鞍点是梯度为0的点,鞍点会使得迭代变慢。
MomentumRMSpropAdam等优化算法能够加速学习。
2.10 优化补充
随机梯度下降会比梯度下降快
mini-batch划分完最后一个可能会小于划分值,需要单独处理。
3 Hyperparameter tuning, Batch Normalization and Programming Frameworks
3.1 超参数重要性(吴恩达观点)
第一:α
第二:Momentum的β、hidden units、mini-batch size
第三:layers、learning rate decay
不调整:adam的β1、β2、ε
迭代次数也是超参数,但是这里没有讲。在练习题里出现了。
3.2 如何尝试超参数
随机的选择,不要按照网格(grid)方式。因为你并不知道哪个参数让效果更好。
而且随机选择能让你在相同的次数里,尝试更多的情况。如果使用网格,参数的情况会被重复使用。
先粗调一个不错的范围,然后在其中精调。
3.3 超参数规模和随机方法
hidden node : 50-100
layers : 2-4
α: 0.001-1 (使用log的方式分布随机值) python: (10^r),r在a~b之间。a = log(0.001),b = log(1)
β: 0.9-0.999 (使用log的方式随机1-β)(β=1-10^r)
3.4 实际中超参数调节
不同领域的超参数调节方法不同,但是可以获得灵感。
对于同一个领域,可能经过一段时间,数据发生变化,过去的超参数并不适合现在的情况。需要每个一段时间重调。
两种调节策略,panda(只训练一个模型)和caviar(鱼子酱,并行训练多个模型),区别源于计算量。
3.5 batch normalization
作用:使得神经网络更加鲁棒,对超参数不再那么敏感。
归一化对逻辑回归有意义,所以想对每一层的输入进行归一化。让均值为0,标准单位反差。
将z[i]归一化,默认用这个,还有人归一化a[i]
实现,这里γ和β是可以放到反向传播里自学习的参数,用来改变归一化的均值和方差尺度。
在下面的情况下,又会回到没有归一化的原始情况。
3.6 神经网络中使用batch normalization
从z算a中间,插入归一化。加入了β和γ参数
对于mini-batch,使用当前部分数据计算
使用时,可以不考虑b参数。因为在归一化中,要满足均值为0,b的作用就没有了。(大概感觉就是加上b就是多了一个平移,但是归一化又会移回来)。他的作用会被β替代。
备注:反向传播的时候,梯度计算要考虑到归一化这个问题。
3.7 为什么batch normalization起作用
最简单的理解就是相当于和输入做归一的效果
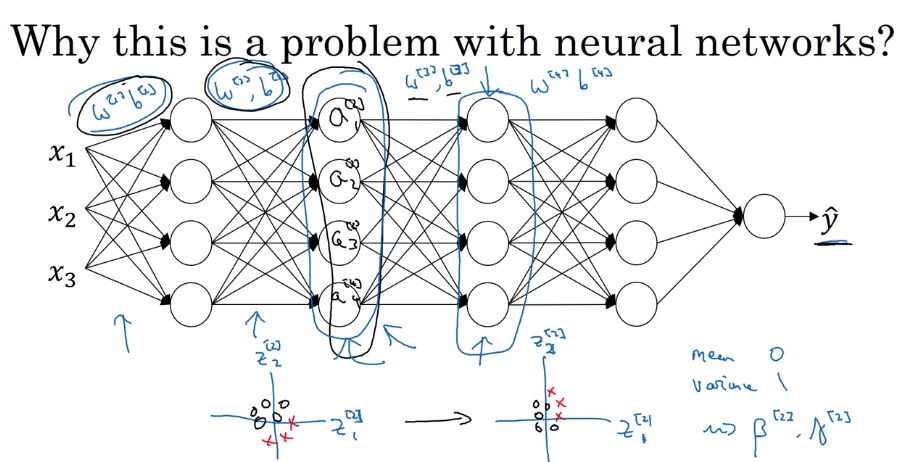
协变量转移问题,黑猫-普通猫识别。
从第二层开始考虑。如果没有batch norm,出现协变量转移问题时,后面的层无法应对这个问题。如果有,那么会使得这一层的平均值和方差不变。解决这种问题。所以可以做到,减少前面层和后面层之间的耦合。课件页如下
在mini-batch中,batch norm有一定正则化的作用,但是作用有限。所以可以和dropout和正则化一起使用。使用大的batch size能减弱正则化作用。实际上不把他理解为正则化。
3.8 测试时如何使用batch norm
由于测试时只有少量的数据,关于平方和方差的计算需要改变。
使用指数加权平均训练集多个mini-batch,来计算μ和σ