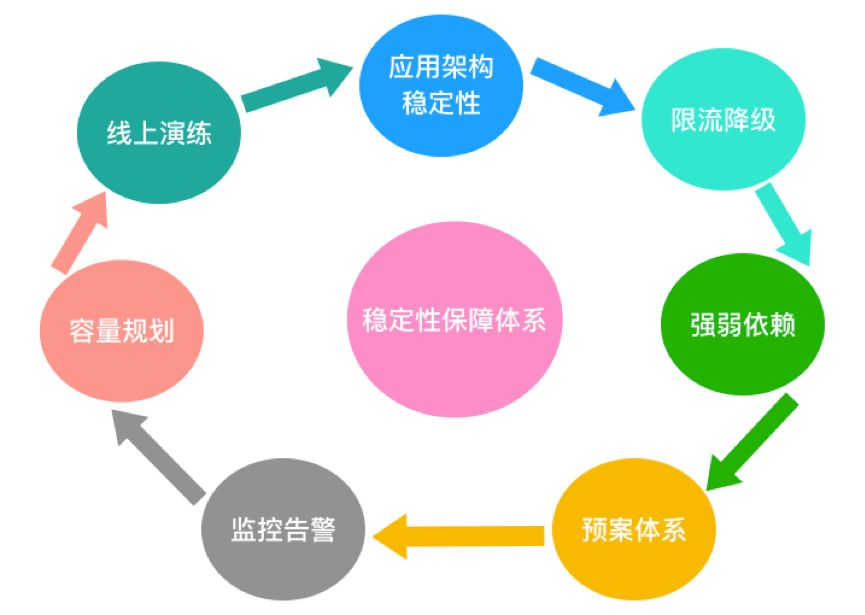
应用架构稳定性
“面向失败和故障的设计”,尽可能做一个“悲观主义者”
限流降级
监控预警
强弱依赖治理
容量评估

第一阶段:主要依靠经验值、理论值等来预估的,或者是靠“拍脑袋”的。
前几年资本市场情况比较好,互联网公司比较典型的现象:老板,我需要买100台服务器,50台跑应用,20台跑中间件,10台做数据库…预计可以扛住日均1000W访问量,每天100W订单…
靠谱一点的人还能扯出 “MySql并发连接数在几core几G大概能到xxx”、 “Redis官方称可以达到10W TPS”之类的参考值,这种至少听起来还有那么一点道理。不靠谱的人呢。那可能就真是瞎说的一个数字,或者会说“我上家公司就用了这么多支撑的”,其实纯靠拍脑袋的。
总之,这都是很不靠谱的。会造成资源分配不合理,有些浪费而有些饥荒。
第二阶段:通过线下压测手段来进行。线下压测通常是压测的单接口、单节点,压测结果可以帮助我们了解应用程序的性能状况、定位性能瓶颈,但是要说做整体的容量规划,那参考价值不大。因为实际情况往往复杂太多,网络带宽、公共资源、覆盖场景不一致、线上多场景混合等各种因素。根据“木桶短板”的原理,系统的容量往往取决于最弱的那一环节。正所谓 “差之毫厘,失之千里”。
第三阶段:通过线上单机压测来做。比较常见的手段有:线上引流、流量复制、日志回放等。其中线上引流实施起来最简单,但需要中间件统一。通过接入层或服务注册中心(软负载中心)调整流量权重和比例,将单机的负载打到极限。这样就比较清楚系统的实际水位线在哪里了。
第四阶段:全链路压测,弹性扩容。全链路压测就是模拟用户真实的访问路径构造请求,对生产环境做实际演练。
故障演练
“混沌工程”是近年来比较流行的一种工程实践,概念由Netflix提出,Google、阿里在这方面的实践经验比较丰富(或者说是不谋而合,技术顶尖的公司大都很相似)。通俗点来讲就是通过不断的给现有系统“找乱子”(进行实验),以便验证和完善现有系统的高可用性、容错性等。引用一句鸡汤就是:“杀不死我的必将使我更强大”
https://github.com/Netflix/chaosmonkey
https://www.infoq.cn/article/2016/11/chaos-monkey-upgrade
ref