前言
在一般情况下,Hibernate需要将执行转换为SQL语句从而性能低于JDBC。但是在经过比较好的性能优化之后,性能还是让人相当满意的,特别是应用二级缓存之后,甚至可以获得比较不使用缓存的JDBC更好的性能。
优化总结
具体分析
第一点:数据库设计
前边博客介绍过 数据库设计,今天我们还从这开始,表的设计就是建楼的基础,如何让基础简洁而结实这是最重要的。
优化策略:
1. 建索引
2. 减少表之间的关联
3. 简化查询字段,没用的字段不要,已经对返回结果的控制,尽量返回少量数据
4. 适当的冗余数据,不过分最求高范式
第二点:HQL优化
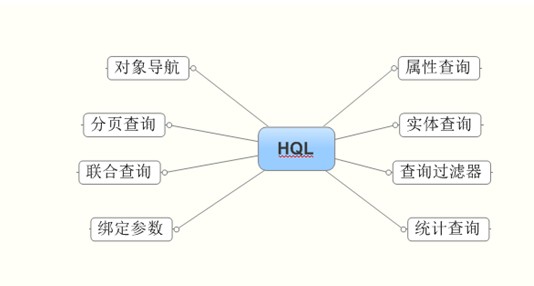
(HQL知识图)
假如想好好了解一下的建议看一下这篇博客HQL详细使用,我个人认为写的还可以,知识总结的很细致。
总结:
1. 实体查询:可以使用sql语句查询
2. 实体的更新和删除:hibernate3中直接提供更加灵活更加效率的解决方法
3. 属性查询:动态构造实例对象,对结果集进行封装
4. 分组与排序:
A. Order by子句
B. Group by子句与统计查询
C. 优化统计查询:内连接,外连接
5. 参数绑定:和jdbc一样,对hibernate的参数绑定提供了丰富的支持。
第三点:缓存
运行机制:
介于应用程序和物理数据源之间,其作用是为了降低应用程序对物理数据源访问的频数,从而提高运行性能。
缓存被广泛应用的用于优化数据库。当一些数据被从数据库中读取出来的时候,我们可以把它们放到缓存里。这样我们可以再次使用的时候直接从缓存中取出来,这样我们的效率就提高了很多。控制范围:
一级缓存是session对象的生命周期通常对应的一个数据库事务或者一个应用事务,它是事务范围内的缓存
二级缓存是一个可插拔的缓存插件,它是由SessionFactory负责管理。由于SessionFactory对象的生命周期和应用程序的整个过程对应,所以二级缓存是进城范围或者集群范围内的缓存。用于初始化很少更改的数据、不重要的数据,不会并发访问的数据。
Hibernate缓存的一些问题和建议:hibernate的缓存
第四点:捉取策略
1. 捉取优化:Hibernate在关联关系之间进行导航,充分利用Hibernate提供的技术
2. 如何捉取
立即捉取:当捉取宿主对象时,同时捉取其相关对象和关联集以及属性
延迟加载:当捉宿主对象时,并不捉取其关联对象,而是当对其对象进行调用时才加载。
3. 捉取粒度:设置捉取个数
第五点:批量数据处理(修改和删除)
在Hibernate2中,如果需要对任何数据进行修改和删除操作都需要先执行查询操作,在得到数据后才进行修改和删除。
1. 不适用Hibernate API而是直接使用JDBC API来做原生态SQL语句进行查询,这种方法比较好,相对来说较快。
2. 运用存储过程
3. 一定量范围内可以使用hibernate API,但是特大数据量不行。
第六点:结果集的使用:
结果集的使用:list()和iterator()区别
查询方式:
list只能利用查询缓存(但在交易系统中查询缓存作用不大),无法利用二级缓存中的单个实体,但是list查出的对象会写入二级缓存,但它一般只生成较少的sql语句,很多情况就是一条。
iterator则利用二级缓存,对于一条查询语句,它会先从数据库中找到所有符合条件的记录的ID,在通过ID去缓存找,对于缓存中没有的记录,在构造语句从数据库查出,第一次的执行会产生N+1条SQL语句。
产生结果:
用list可能会溢出
通过Iterator,配合缓存管理API,在海量数据查询中可以很好的解决内存问题。
综合考虑:
一般List会填充二级缓存,却不能利用二级缓存,而Iterator可以读二级缓存,然而无法命中的话,效率很低效。一般处理方法,就是第一次查询使用list,随后使用iterator查询。
总结
Hibernate优化总结还有主配置、方法选用、事物控制没有涉及到,因为它们相对来说这些方面比较简单,但是还是很重要的。
在实施一个项目的时候我们没有必要想这些问题,做项目的时候第一步运行起来,第二步优化一下。在很多小型项目中第二步一般都不会去做,所以说我们做工程的时候还是要牢记运行出来,假如自己作为研究或者这个问题比较严重的话我们才考虑优化。
Hibernate调优方面没有最有只有更优,让我们不断积极找到优化的方法,来优化我们的程序,来优化我们自己。
关于Hibernate优化方面,希望大家留下宝贵的意见,多对交流!