一、操作系统的概念
定义:从本质上来说操作系统就是把底层硬件抽象成了一层虚拟机,所以说计算机本身就是一个虚拟机。计算机本身并不会做任何事情,它就是一堆铁疙瘩,即使给它加电它也不会做任何事情,cpu只有在程序的指挥下才会做事情。所以,操作系统的启动就是一个自举的过程,上电的一刹那间主板上的一块ROM芯片中的代码会被自动映射到内存的低地址空间,这块ROM芯片中存的就是BIOS。
二、核心五大部件
在冯诺依曼体系中,计算机有五大部件,分别是运算器、控制器、寄存器、输入设备和输出设备。其中CPU最核心的是运算器、控制器和寄存器。
运算器:负责算术、逻辑运算等,
控制器:控制指令,包括数据的存取过程。程序就是由指令+数据组成的
寄存器(Register):将取回的数据暂存于此,同时起到中间数据计算结果存放的功能。
因此运算器在控制器的控制下不断从寄存器中读取数据处理,在计算机内部的存储器速度是最快的,称为寄存器(暂存)。之所以称为寄存器是因为里面的数据刷新频率很快可以跟CPU刷新频率同步,接下来比较快的是一级缓存、二级缓存、三级缓存,再到外面就是内存了,从内到外造价越来越低,存取速度越来越慢,容量越来越大。一级缓存又被分为一级指令缓存,一级数据缓存;二级缓存就没有这样区分了。多核CPU,每一核CPU都有自己一级、二级缓存,而三级缓存是共享的。
寄存器固然能存储数据,但是空间太小,不是存储设备的核心部件,因此必须要跟内存设备打交道
内存(RAM):由多个存储单元组成,一个字节为一个存储单元,或者一个cell为一个存储单元。每个cell都有自己的存储地址,以16进制进行编制。
CPU要想存取数据,就需要知道内存中数据的存储地址,必须要具备寻址数据功能。
北桥芯片(NorthBridge):用来处理高速信号。通常处理CPU(处理器)、RAM(内存)、AGP端口或PCI Express和南桥芯片之间的通信。即是CPU电路单元和RAM的存储电路建立关联关系
32位CPU:相当于CPU有32根地址线与内存相连,每根地址线都能传输0和1两个位的信号,即能处理的信息为2^32bits=512Mbyte,32根线总共会决定出2^32次方个位置,每一个位置都是1Byte,这是内存的基本单位,因此最多能支持的内存为2^32Byte=4GB。同理64位CPU,4G*4G相当于40多亿个4G。

CPU完成寻址的线路、数据读取的线路、控制指令线路,如果每个线路都配上32根地址线就变得相当复杂,因此CPU将这些线路进行复用(线路复用),通过控制位来区分哪些是数据读取、哪些上寻址等
PAE(物理地址扩展):Physical Address Extension。在32位(bit)寻址总线的基础上再增加4bit相当于2^36Byte=64G,但是需要操作系统内核支持寻址64G的能力。32位操作系统无论内核是否支持PAE,单个进程的所能使用的地址空间超不过3G,剩下1G映射给内核了。例如MySQL就是单进程多线程运行,在32位操作系统上最多能使用的内存只有2.7G,因此最好使用64位的操作系统安装64位的MySQL。
这里牵扯到一个问题,为什么缓存可以提高速度?是因为程序的局部性原理,就是我们常说的二八法则。一段程序中执行频率最高的代码往往只有20%,80%的代码很少用到,而这20%的代码完成了整个程序80%的功能。我们可以将这20%的代码缓存到cpu一级缓存或者二级缓存中,因为cpu中的cache的速度和cpu的时钟频率最接近,这样就可以提高程序运行的速度,
一般缓存算法设计的思路都是:最近最少使用原则。将最近最少使用的数据从缓存中移除,毕竟缓存的空间是有限的,要是缓存和内存的价格一样,那就没必要设计缓存了。程序的局部性原理分为空间局部性和时间局部性:空间局部性是指一段代码被访问了,那么它周围的代码也极有可能被访问到。时间局部性是指某一时刻一段代码被访问了,那么过一会儿这段代码极有可能被再次访问。
N路关联:PC机一级缓存空间通常为64KB,而内存远远大于一级缓存。但是CPU读取数据一定是来自一级缓存的,一级缓存没有就去二级缓存寻找,找到即替换一级缓存中的,反之一层一层往下找,直到内存中。由于一级缓存与内存差异巨大,CPU命中需要数据的概率极低。RAM中的每个存储单元都可以直接缓存在一级缓存中的每一个位置,这叫直接映射,因此为了提高命中率引入了N路关联技术。原理上将RAM分为几片,同理一级缓存也分为对应的几片,如下图,所谓1路关联(1 way),内存中的00、08、16、24只能缓存在set 0单元上,01、09、17、25只能缓存在set1单元上,如果00已经在set0单元上,此时08想缓存在set0上,就要将00置换掉

2路关联
如下图,00、08可以同时缓存在set0单元上,而16、24想缓存时需要置换前两个
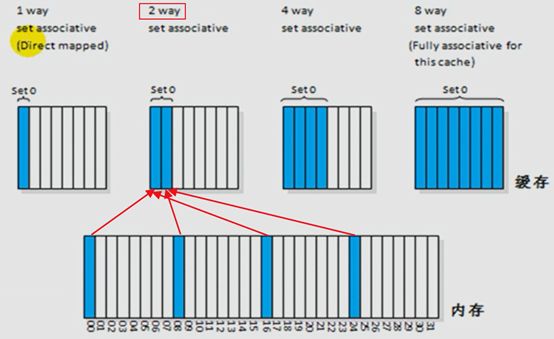
4路关联
如下图,00、08、16、24可以同时缓存在set0单元上,而01、09、17、25想缓存时需要置换前四个

完全关联

通写策略(write-through):在数据更新时,同时写入缓存Cache和后端存储。此模式的优点是操作简单;缺点是因为数据修改需要同时写入存储,数据写入速度较慢。
回写策略(Write-back):在数据更新时只写入缓存Cache。只在数据被替换出缓存时,被修改的缓存数据才会被写到后端存储。此模式的优点是数据写入速度快,因为不需要写存储;缺点是一旦更新后的数据未被写入存储时出现系统掉电的情况,数据将无法找回。
显卡(video card):跟CPU数据交互量上非常大的,也是接在北桥上的,是一个高速总线。
IO设备:除了CPU中的运算器、控制器、寄存器之外的设备都是IO设备,IO设备分为低速IO和高速IO。高速IO通常指的的PCI总线
为了衔接计算机系统中各个速度比cpu慢的设备,早期的主板上集成有北桥芯片和南桥芯片(现在的主板可能已经不是这么设计了),南桥芯片是将各慢速设备汇总起来一起接入北桥芯片,所以桥接芯片说白了就是汇总各外部设备最终完成和cpu的交互。south bridge上接的通常称为ISA总线,早期的PCI总线都是接到南桥上的,接入北桥的称为PCI-E,PCI-E总线的速度比PCI总线的速度要快得多得多。常见的磁盘总线都是PCI格式的,SCSI、IDE、SATA统称为PCI总线,PCI(外部设备互连)只是一种统称。鼠标、键盘是串行接口的,通常U盘是通过PCI总线连接南桥-北桥-CPU进行数据交互的。如果把U盘做成PCI-E接口,线路带宽足够大,而U盘太慢了,此时把N个U盘并行连接当作一个存储盘使用,由一根PCI-E总线连接北桥与CPU进行数据交互,这种称为固态硬盘。现在很多固态硬盘接口都上SATA接口,建议购买PCI-E接口的固态硬盘。那么问题来了,计算机接了这么多的外部设备,cpu如何区分不同的IO设备呢?类比计算机区分和互联网通信的各个进程的方法,计算机区分不同的和外部通信的进程靠的是套接字,也就是ip地址+端口号。这里cpu区分不同IO设备靠的也是端口号,称为IO端口,在一台计算机上IO端口的数目也是65535个。任何一个硬件设备通过IO总线接入计算机的时,它必须一开机就申请注册一批连续的IO端口。
任何一个硬件设备的电路可能跟CPU内部电路不一致,因此每一个外部设备都有控制器、适配器,控制器和适配器是将外部设备的信号转换成连接CPU总线上能理解的信号,相当于翻译官,同时控制外部设备的传输速率、校验等功能。所谓驱动就是指挥控制器芯片与硬件工作的。
轮巡(poll):CPU连接这么多外接设备,是如何区分电信号是来自硬盘、鼠标还是网卡,它每隔几毫秒去轮巡一次,查看这些设备有没有信号传输。
中断(interrupt):因poll效率非常低,因此每个设备发送信号时通知CPU来查看,CPU怎么得知是哪个设备的信号呢?可能你会想到通过IO端口来识别,IO端口是实现数据交互而不是识别信号交互的
中断控制器(Interrupt Controller):CPU外置芯片,接收中断信号。当某个外部设备(例如网卡卡)传来信号,CPU中断当前操作,将此信号接收至内存中。中断控制器上连接着中断线,每根线代表一个设备(不是固定的设备),用来区分外部设备,线路是可以复用的,
直接内存存取(DMA):如果CPU需要处理每个外部设备发来的信号,将会使CPU很繁琐,因此引用DMA来解决这个问题。由CPU在内存中划好某次传输数据所需空间,并授权某根线路给DMA使用。它允许不同速度的硬件装置来沟通,而不需要依赖于 CPU 的大量中断负载。否则,CPU 需要从来源把每一片段的资料复制到暂存器,然后把它们再次写回到新的地方。在这个时间中,CPU 对于其他的工作来说就无法使用。
在实现DMA传输时,是由DMA控制器直接掌管总线,因此,存在着一个总线控制权转移问题。即DMA传输前,CPU要把总线控制权交给DMA控制器,而在结束DMA传输后,DMA控制器应立即把总线控制权再交回给CPU。一个完整的DMA传输过程必须经过DMA请求、DMA响应、DMA传输、DMA结束4个步骤。
在物理内存当中,最低地址那段空间,最容易寻址的那段空间的起始地址就预留给DMA,一般16M,在DMA最前面还有1M使用的空间是留给BIOS。
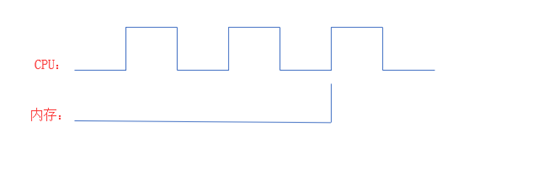
CPU工作频率比较快,内存工作频率比较慢,当内存传输数据给CPU时,CPU大部分时间上处于空闲状态的,因此CPU与慢设备打交道时,会浪费许多时钟周期。CPU内部有一个时间产生器(晶体振荡器),始终产生着时钟脉冲。如下图CPU已经转了好几个周期才开始与内村打交道。CPU为了协调步伐一致,要规划好多少个周期后与内存交互。一般上在时钟周期的上升沿(即高电平与低电平进行切换时)进行交互。
操作系统:CPU与外部设备交互经常步伐不一致,为了合理利用CPU资源,即衍生出了Monitor(监控器),发展到后来就成为OS(操作系统),再后来操作系统把计算机抽象成虚拟机。
之所以把操作系统称为虚拟机,是因为我们只有一块cpu芯片(可能是多核心的),只有一块内存,鼠标只有一个,键盘只有一个........但是每个进程都想独占这一整套资源。cpu通过时间片轮转的方式将一个cpu芯片虚拟成多个cpu进行,内存的虚拟通过分页机制,将内存切割成一个个固定大小的页面。好了,现在已经把计算机系统中最重要的两个部件运算器和存储器虚拟出来了(其实就是虚拟的cpu和内存),剩下的那些IO设备如何虚拟呢?其实在IO虚拟不需要专门去做,因为当前哪个进程获得了系统使用权,IO设备就交给整个进程。
进程:一个程序有许多功能,但加载程序的部分功能到CPU中执行的实例称为进程,相当于一个独立运行单位。
多个独立进程同时运行,CPU、缓存、内存、IO设备上如何合理的分配资源的?
1、 CPU:将时间切割成各个独立单位,在时间的维度完成切片进而完成CPU虚拟。
2、 缓存:有足够空间可用即不需要做什么,如果没有的话,则要进行保存。但是这个进程还没有执行完,CPU分配的时间已经到下一个进程了,此时就要保存现在这个进程的指令数(CPU内部的指令计数器:寄存器),也就是保存现场,再次回来就要恢复现场
3、 内存:将空间切片,内核预留一部分,依次分给进程1、进程2等等以此类推,如果是这样划分的话,进程随时启动,随时终止,或者有的进程需要的空间大,有的小,划分的空间进程不够用,有的划分得太多,所以得引入内存保护机制。如此只能将内存按固定大小进行切割,例如按4k大小为一个单位(存储槽)进行切割,每个存储槽为一个页框(page frame),每个存储槽存储的数据叫一个页面(page),在页面和页框上加一个页和页框的映射机制,这个映射上面的进程都各自认为自己拥有所有内存。进程空间(指令区+代码区+数据区+bss段+堆+栈)如,指令一个页,代码一个页,数据两个页等,如下图,代码区和栈由控制芯片映射到内存中的某个页框上,并不是连续的页框。站在进程的角度来讲,它所需数据的地址是线性地址,而真正数据上存放在物理地址,因此需要通控制芯片进行查找,如此多的数据,控制芯片是如何快速查找的呢?其实在控制芯片里将两者的对应关系划分成了页目录(一级目录、二级目录、三级目录等)

4、I/O设备:要跟硬件(即I/O设备)打交道必须通过内核,由内核转给进程。
cpu芯片只有一块,在某一时刻,要么是内核进程在上面运行,要么是用户空间进程在上面运行,内核在cpu上运行时称为内核模式,进程在cpu上运行时称为用户模式。而在内存中内核占据的那段内存空间称为内核空间,用户进程占据的空间叫用户空间。用户模式时,进程是不能直接控制硬件的。这是因为在cpu内部,cpu制造商将cpu能运行的指令划分为4层(仅对x86架构而言),ring0,ring1,ring2,ring3,由于历史原因,ring1和ring2并没有使用,linux只用了ring0和ring3。ring0称为内核模式,也称为特权指令模式,可以直接操控硬件,ring3是用户模式,可以执行一般指令。
当一个运行中的进程要打开文件或者操作麦克风,它发现自己没有权限执行特权指令,于是就会发起系统调用,一旦产生系统调用进程就会退出,从用户模式切换到特权模式,称为模式切换。由内核负责将数据装载至物理内存(物理内存为内核与各进程用户都划分了一段自己的空间)先到内核空间中,再转至进程用户空间,然后映射到线性地址上,这个时候内核再唤醒用户进程进行数据交互。如果有多个进程,即进程队列,这里就牵扯到进程的状态了,这里简单介绍几个。就绪状态:就绪是指在所有进程队列中,这个进程所需的所有资源都已经准备好了。没有就绪的称为睡眠状态,而睡眠状态又分为可中断睡眠和不可中断睡眠,区别是:可中断睡眠是指随时可以唤醒的,不可中断睡眠是指内核为它准备的数据还没有准备好,即使唤醒它,它也不能干活。可中断睡眠不是因为资源没有准备好而睡眠,只是一个阶段的活已经干完了,下一阶段的活儿还没来,于是它就去睡觉了,你可以随时叫醒它,所以称可中断睡眠。而不可中断睡眠一般是因为IO而进入睡眠状态的。
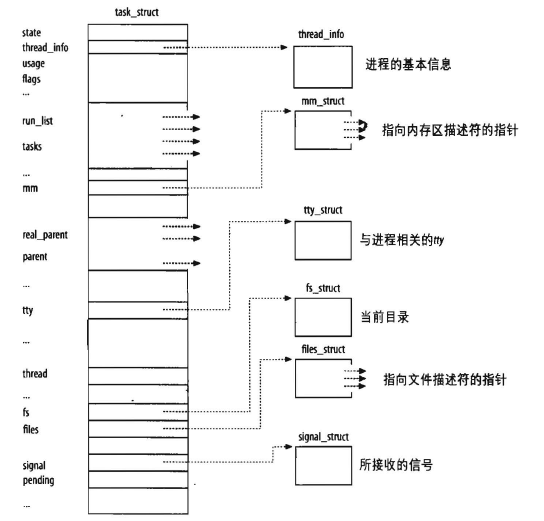
进程结构:进程是通过双向链表(List)来管理的,而这个链表是有次序的。如下图:通过其中一个可以找到下一个,每个进程在Linux内核内部靠一个独立的数据结构来管理,这个结构叫Task_structure(C语言描述独立数据组织的数据结构),而这个整体文件也被称作进程描述符(类似文件的元数据)。每个进程都有进程描述符,在创建一个进程时,首先创建一个进程描述符,并添加到双向链表上,删除则在此表上删除描述符。

从内核观点看,创建一个进程除了要给进程分配系统资源(CPU 时间、内存等),还要在内核的内存空间中给它维护一个进程描述符文件。这个文件保存着当前进程的所有相关信息,这个文件结构如下:
进程切换(Context switch):又称为上下文切换。如下图A进程和B进程进行切换。
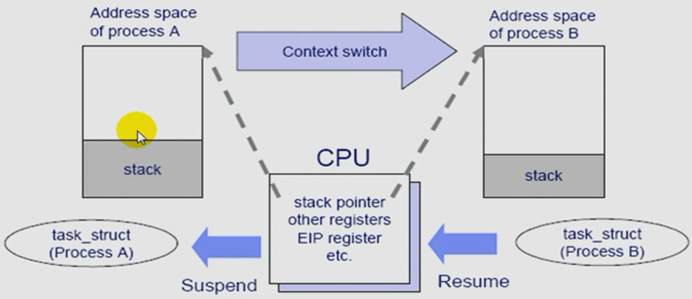
假如,B进程替换A进程,A的进程描述符(task_struct)要被CPU挂起(suspend),意味着在CPU上的占位符(stack pointer)、其他寄存器(other registers)、指令计数器(EIP register)等等所维持的数据都需要保存到A进程描述符文件当中(称为保存现场),而进程描述符是由内核维护着,描述符大小是固定的。当A进程被挂起,B进程就被执行进来,这个过程叫恢复现场(resume)。可以看出上下文切换也是需要花时间的,而且上下文切换是由内核来完成,意味着每一次进程切换都要从用户模式转到内核模式,然后再到用户模式如此这样运行下去,不可能一个进程直接到另一个进程,必须由内核完成,则整体时间被分为两部分(用户模式所占据的时间(%us)+内核模式所占据的时间)。所有内核占据的这部分时间就是下图的%sy所占据时间

通常内核模式是不应该占据太多时间的,如果占用时间过多大都是进程切换,中断次数等过多导致的,而进程大部分时间是跟用户模式打交道的。
进程抢占:根据时钟中断抢占,也就是系统时钟(内部时钟频率),称为嘀嗒(tick)。
注:Linux有系统时钟和硬件时钟。
Tick每秒嘀嗒的次数称为时间解析度,中断次数Hz
100Hz:一秒嘀嗒100次,每秒100次时间中断
1000Hz:一秒嘀嗒1000次,1ms嘀嗒一次
通常每次滴答都会产生可抢的时钟中断
调度器:其任务是在程序之间共享CPU时间, 创造并行执行的错觉, 该任务分为两个不同的部分, 其中一个涉及调度策略, 另外一个涉及上下文切换。内核必须提供一种方法, 在各个进程之间尽可能公平地共享CPU时间, 而同时又要考虑不同的任务优先级.
调度器的一个重要目标是有效地分配 CPU 时间片,同时提供很好的用户体验。调度器还需要面对一些互相冲突的目标,例如既要为关键实时任务最小化响应时间, 又要最大限度地提高 CPU 的总体利用率.
调度器的一般原理是, 按所需分配的计算能力, 向系统中每个进程提供最大的公正性, 或者从另外一个角度上说, 他试图确保没有进程被亏待.
进程分类:
交互式进程(I/O):例如编辑器,大量时间等待IO上与CPU打交道比较少
批处理进程(CPU):守护进程,大量CPU时间
实时进程(Real-time):立即响应,优先级最高
|
类型 |
描述 |
示例 |
|
交互式进程(interactive process)
|
此类进程经常与用户进行交互, 因此需要花费很多时间等待键盘和鼠标操作. 当接受了用户的输入后, 进程必须很快被唤醒, 否则用户会感觉系统反应迟钝 |
shell, 文本编辑程序和图形应用程序 |
|
批处理进程(batch process) |
此类进程不必与用户交互, 因此经常在后台运行. 因为这样的进程不必很快相应, 因此常受到调度程序的怠慢 |
程序语言的编译程序, 数据库搜索引擎以及科学计算 |
|
实时进程(real-time process) |
这些进程由很强的调度需要, 这样的进程绝不会被低优先级的进程阻塞. 并且他们的响应时间要尽可能的短 |
视频音频应用程序, 机器人控制程序以及从物理传感器上收集数据的程序 |
如何设定是批处理进程优先级高呢还是交互式进程高呢?如果批处理进程优先级高,对于交互式进程的应用,例如编辑器输入一个字母或者数字半天没有响应;如果交互式进程优先级高,对于CPU来说大部分时间是空闲的,所以很浪费资源。因此调度器引用了以下分配策略:
CPU密集型(批处理进程):时间片长,优先级低
IO密集型(交互式进程):时间片短,优先级高
进程优先级(priority)定义:1、实时优先级;2、静态优先级。优先级范围从1~139
实时优先级:用1~99表示,数字越小,优先级越低
静态优先级:用100~139表示,数字越小,优先级越高
实时优先级比静态优先级高,通常内核进程都是实时优先级。优先级为RT就是实时优先级(1~99),而20是从100之后的20(即120),原因它的nice值是为0,这是站在用户模式是讲。如下图:
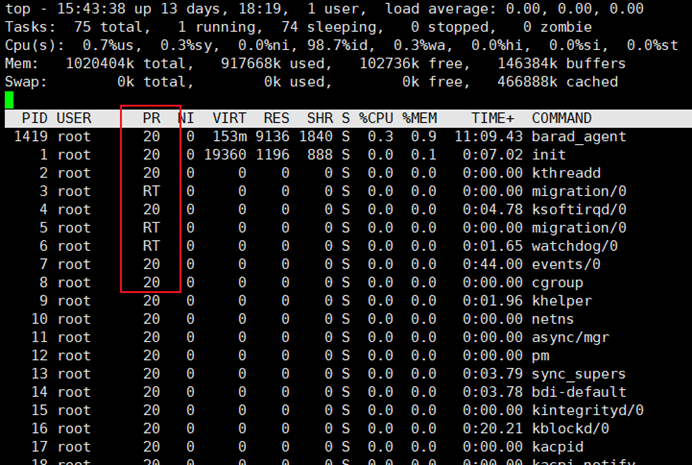
查看进程优先级:ps -e -o class,rtprio,nice,pri,nice,cmd用这个命令可以查看优先级, class:表示调度类别
rtprio:实时优先级
nice:调整静态优先级。nice值是-20到19,对应的是100到139,nice值为0对 应的为120,默认为0
pri:非实时优先级(静态优先级)
cmd:执行的命令

如上图,nice值是0,而pri为19,为什么不是20呢?原因是经过动态优先级调整(见动态优先级公式)。凡是带有中括号的都是内核线程。
[root@localhost ~]# ps -e -o class,rtprio,nice,pri,nice,cmd
CLS RTPRIO NI PRI NI CMD
TS (other) - 0 19 0 /sbin/init
TS - 0 19 0 [kthreadd] 凡是加了括号的都为内核线程
FF (fifo) 99 - 139 - [migration/0]
TS - 0 19 0 [ksoftirqd/0]
FF 99 - 139 - [migration/0]
进程调度类别:
对于实时进程来讲:
SCHED FIFO:first in first out(先进先出队列)调度fifo类别的实时进程
SCHED_RR:round robin(轮调)调度rr类别的实时进程
SCHED_Other:专门用来调度用户空间进程的,100-139之间的进程
Linux(红帽)特有的两个调度类别
SCHED_BATCH 调度批处理进程
SCHED_IDLE 调度空闲进程
动态优先级:如果110、115、120、130级进程都分别很多个,那处于末级的一直分配不到CPU资源,因此采用动态优先级策略。内核监控这些进程,如果某些进程长时间没有分配到资源,内核将临时性的调高优先级,主要对100-139的进程即SCHED_Other类进程,对用户空间进程,长时间没有获得时间片或长时间获得时间片,进行调高或者调低。
dynamic priority(动态优先级)= max (100,min ( static priority - bonus + 5,139))
动态优先级等于从100和 min ( static priority - bonus + 5,139)中取最大数
bonus(范围0到10)
比如110的优先级要对它临时性的调低,降低3级的措施后
110-(-3)+5 =118,118与139比取118,然后再与100相比,去最大数118。所以优先级被调整到118
手动调整进程优先级:
100-139进程:使用nice命令
nice N COMMAND
renice -n # PID 指定新的nice值并指定PID号
1-99进程:使用chrt命令
chrt:
-p 指定PID
-f 指定fifo类别
-r 指定 rr类别
-b 指定批处理进程
-i 空闲进程
chrt -f -p [prio] PID 调整fifo的优先级
chrt -r -p [prio] PID 调整rr的优先级
chrt -f -p [prio] COMMAND 启动进程时直接指定实时优先级
ps -e -o class,rtprio,nice,pri,nice,cmd 查看命令
chrt -p [prio] COMMAND 也能调整100-139进程的优先级
内核调度是取优先级高的进程,通常从进程队列中获取。如何公平、快速的从数百个进程队列中调取呢?
在现实生活中如何获取公平:1、保证起点公平(一生下来,针对自己是什么都没有,凭借自己的能力获得经济收入);2、二次分配(有些能力比较强高收入人交税就多交点,分配给低收入人)。因此在计算机中公平的调取进程是需要融合多种策略来进行。
Linux内核2.6的调度算法,按照级别将所有的进程分成了139*2个队列,优先级最高的是99,从优先级高到低每一次扫描队列的首部,接着就是这列的第二个,每个队列是包含2个(活动队列、过期队列),如果一个进程当它的时间片到了,进程没有执行完,就将其放入过期队列,等下次时间片。所以无论有多少个进程,队列一个只有139个,因此每次一共只要扫描139,这就是O(1)算法
一开始的调度器是复杂度为O(n)O(n)的始调度算法(实际上每次会遍历所有任务,所以复杂度为O(n)), 这个算法的缺点是当内核中有很多任务时,调度器本身就会耗费不少时间,所以,从linux2.5开始引入赫赫有名的O(1)调度器
然而,linux是集全球很多程序员的聪明才智而发展起来的超级内核,没有最好,只有更好,在O(1)调度器风光了没几天就又被另一个更优秀的调度器取代了,它就是CFS调度器Completely Fair Scheduler。这个也是在2.6内核中引入的,具体为2.6.23,即从此版本开始,内核使用CFS作为它的默认调度器,O(1)调度器被抛弃了, 其实CFS的发展也是经历了很多阶段,最早期的楼梯算法(SD), 后来逐步对SD算法进行改进出RSDL(Rotating Staircase Deadline Scheduler), 这个算法已经是”完全公平”的雏形了, 直至CFS是最终被内核采纳的调度器, 它从RSDL/SD中吸取了完全公平的思想,不再跟踪进程的睡眠时间,也不再企图区分交互式进程。它将所有的进程都统一对待,这就是公平的含义。CFS的算法和实现都相当简单,众多的测试表明其性能也非常优越。
|
字段 |
版本 |
|
O(n)的始调度算法 |
linux-0.11~2.4 |
|
O(1)调度器 |
linux-2.5 |
|
CFS调度器 |
linux-2.6~至今 |
进程空间:进程空间由text、data、bss、heap、stack组成,如下图:
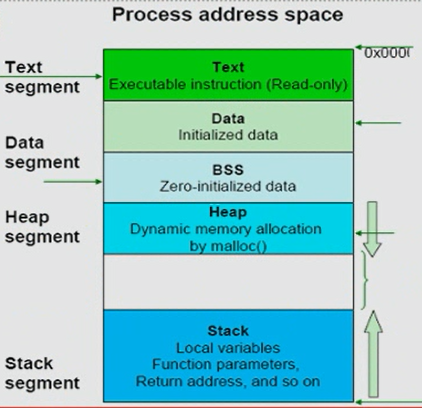
程序段(Text):程序代码在内存中的映射,存放函数体的二进制代码,只读段的指令区。
初始化过的数据(Data):在程序运行初已经对变量进行初始化的数据。
未初始化过的数据(BSS):在程序运行初未对变量进行初始化的数据(即初始化为0的变量)。
堆 (Heap):存储动态内存分配,需要程序员手工分配,手工释放.注意它与数据结构中的堆是两回事,分配方式类似于链表。比如打开文件通常都在堆上。
栈 (Stack):存储局部、临时变量,函数调用时,存储函数的返回指针,用于控制函数的调用和返回。在程序块开始时自动分配内存,结束时自动释放内存,其操作方式类似于数据结构中的栈。例如程序运行过程产生的变量、返回的值都保存在栈上。
进程的创建:Linux的每个进程都是由父进程生成,第一个进程是init(有kernel来创建的),而后其他的所有进程都是由init来生成,或者init的子进程生成。通过fork()来创建,其实就是通过系统调用。创建一个子进程最重要的是创建它的描述符(task_struct),这个是由内核完成的,创建完成之后是需要分配内存空间的,刚开始创建,内存空间是和父进程共享的,cow(copy on write)即父进程、子进程需要修改内容的时候就分配单独空间。
三、CPU负载观察及调优方法
RHEL 6.4已经实现无嘀嗒效果(tick less)即时钟中断。按100Hz:一秒嘀嗒100次,每秒100次时间中断,就算CPU在空闲时也要进行时间中断,是很消耗电源或者资源的,更重要的是大量时间CPU都在空载。因此在这种场景下,红帽6以后的内核采用了无嘀嗒的机制,CPU可以进行深度睡眠,完全靠中断驱动(interrupt-driven)。其包括软中断和硬中断。
软中断:由软件产生的中断,系统调用需要从用户模式切换到内核模式称为软中断。
硬中断:由硬件产生的中断称为硬中断
现在CPU都是多核的,而在服务器领域使用多颗CPU是正常的。在SMP(对称多处理器:一块主板上有多个CPU插槽)多CPU架构中,每个插槽称为一个socket,当多个CPU访问同一个内存,传统上多CPU对于内存的访问是总线方式。是总线就会存在资源争用和临界区问题,而且如果不断的增加CPU数量,总线的争用会愈演愈烈,这就体现在4核CPU的跑分性能达不到2核CPU的2倍,甚至1.5倍都没有。理论上来说这种方式实现12core以上的CPU已经没有太大的意义。
为了防止多颗CPU访问内存出现资源争用,可以采取多核CPU共享三级缓存的策略,因为三级缓存是在CPU内部,速度比访问内存快就算由资源争用也会影响比较小,即为每个CPU分布一个专用内存并且配有专用控制器。这种情况下,由于内存已经属于系统级别,内核加载时有可能把数据加载到不同CPU的专用内存上,则CPU调度队列就不在是一个队列,每个CPU都有自己的进程队列,但是这些队列会不断被内核进行平衡(rebalancing),资源平均利用,这样就有可能会导致1号CPU需要到2号CPU的专用内存上读写数据,这种现象称为非一致性内存访问(NUMA)。如下图,CPU 0-3访问自己的内存需要1、2、3步骤(3个时钟周期),而访问CPU 4-7的内存需要1、1a、2、3步骤,其中1a就需要消耗3个时钟周期。
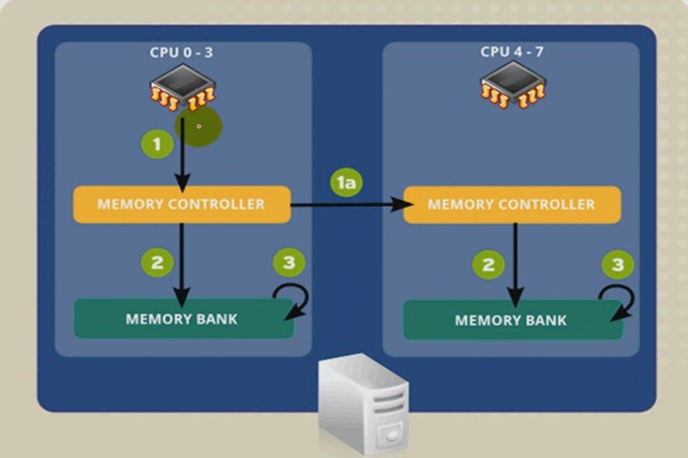
在企业中,NUMA结构是很常见的,为了避免内存间交叉访问,性能下降,禁止内核进行平衡,对于比较繁忙的、经常性批处理的服务进程可以采取CPU绑定(CPU affinity)策略即CPU姻亲关系。将左边灰色也就CPU 0-3那一排称为一个节点(node),另一排称为另一个节点
Intel的NUMA解决方案,放弃总线的访问方式,将CPU划分到多个Node中,每个node有自己独立的内存空间。各个node之间通过高速互联通讯,通讯通道被成为QuickPath Interconnect即QPI。
NUMA一共有4个命令:
numactl控制命令,实现策略控制
-cpunodebind=nodes 将cpu跟某个node绑定,不让cpu访问其他node
-physcpubind=cpus 将进程和cpu完成绑定
--show显示当前使用的策略
numastat 显示几个node的命令
-p:查看某个特定进程的内存分配,如果某个内存分配跨越好几个node则需
要进行CPU绑定
-s node0:查看node0和全部的,主要用于排序
[root@localhost ~]# numastat 显示有几个node
node0
numa_hit 283715 #表示cpu到这个内存node(节点)找数据,找到即命中多少个
numa_miss 0 #没命中个数,命中过高需要绑定进程到特定cpu
numa_foreign 0 #被非本地cpu访问次数
interleave_hit 14317
local_node 283715
other_node 0
当numa_miss值过高时就需要进行CPU绑定进程
numad:用户空间级别的守护进程,能够提供策略,通过观察cpu每个进程的状
况,自动把某个进程绑定到特定的cpu上,实现自我监控,自我优化,自我管理。
numad是在硬件级别将某个进程跟cpu和node绑定。如果真想建立CPU的姻亲关系即将CPU和进程进行绑定,有专门的工具,就算是非NUMA架构也可以实现,专门将某个进程跟CPU绑定,也有专门的命令taskset
taskset:绑定进程至某cpu上。是以mask掩码的方式表现的:例如0x0000 0001(16进制)0001:表示第0号CPU
0x0000 0003
0003换成二进制0011: 表示第0号和1号CPU
0x0000 0005
0005换成二进制0101:表示第0号和2号CPU
0x0000 0007
0007换成二进制0111:表示第0、1、2号CPU
列如把pid为101的进程绑定在3号cpu上
Taskset的用法:将pid101绑定在1号CPU
#taskset -p 掩码 pid
例如:1号CPU为0010换算成十进制为0002
[root@localhost ~]# taskset -p 0x0000 0002
或者加参数-c,直接指定第几号CPU
[root@localhost ~]# taskset -p -c 1 101
绑定在0号和1号cpu上
[root@localhost ~]# taskset -p -c 0,1 101
绑定在0-2号和7号cpu上
[root@localhost ~]# taskset -p -c 0-2,7 101
如果一个CPU有16核,0和1核用来运行其他进程和系统中断,2-15用来运行某个进程并且隔离系统中断。
[root@localhost ~]# cat /proc/irq/0/smp_affinity
ffffffff,ffffffff,ffffffff,ffffffff #表示0号中断可以运行到任何cpu上,全部f表示任何CPU
应该将中断绑定至那些非隔离的CPU上,从而避免那些隔离的cpu处理中断程序
# echo "00000000,00000000,00000000,0000001" > /proc/irq/0/smp_affinity
将0号中断绑定到 0号cpu上
echo CPU_MASK >/proc/irq/<irq number>/smp_affinity
NUMA模式可以通过当numa_miss值过高时就需要进行CPU绑定进程,那非NUMA模式如何确定什么时候需要绑定中断?什么时候需要绑定到CPU上。通过以下命令进行查看运行状态(sar -q、top、w、uptime、vmstat 1 5)。
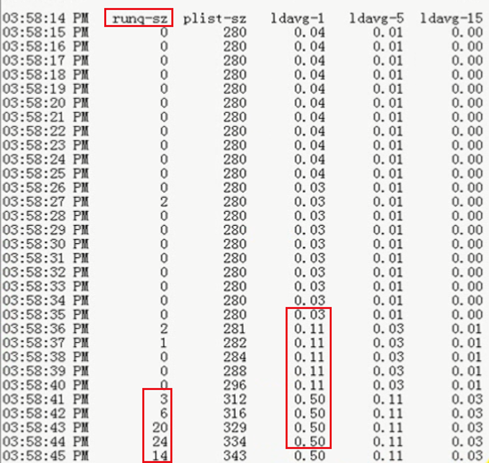
[root@localhost ~]# sar -q 1 #每隔1秒实时监控队列长度负载平均值
09:32:17 AM runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15
运行队列长度
09:32:18 AM 0 96 0.00 0.00 0.00
09:32:19 AM 0 96 0.00 0.00 0.00
通常还可以对web服务器进行ab压力测试,以上数值会进行急剧增长。ab是apachebench命令的缩写。
-n在测试会话中所执行的请求个数。默认时,仅执行一个请求。
-c一次产生的请求个数。默认是一次一个。
#10000个并发数为300的请求数
[root@localhost ~]# ab -n 10000 -c 300 http://127.0.0.1/index.php
Runq-sz为运行队列长度,3、6、20代表有多少个进程在等待运行调度,如果只有一颗CPU的时候,队列长期超出3,说明要升级了。
查看CPU状态命令(mpstat命令)
mpstat 1 2 显示每一颗cpu的平均使用率,-P指定查看哪颗CPU
[root@localhost ~]# mpstat -P 0 1 #只显示0号cpu,每秒钟显示一次
%usr用户空间的, %sys内核空间的,%iowait IO等待的,%irq硬处理中断的,%soft软中断的,%steal被虚拟机偷走的,%guest虚拟机使用的,%idle空闲的
09:35:33 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle
09:35:34 AM 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
09:35:35 AM 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
09:35:36 AM 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
[root@localhost ~]# mpstat -I CPU 1 #显示cpu对中断处理的
sar命令
[root@localhost ~]# sar -P 0 1 #显示0号CPU使用情况(每秒显示一次)
[root@localhost ~]# sar -w 1 #每秒钟上下文切换的次数以及进程创建的个数
vmstat命令也可以查看上下文切换的次数,如下图中cs列:

iostat命令
[root@localhost ~]# iostat -c 1 2 #一共采样2次,每隔一秒采样一次
/proc/stat文件
[root@localhost ~]# cat /proc/stat
dstat命令
dstat --top-cpu 查找谁最消耗cpu
--top-cputime查找谁消耗cpu时间最长的
--top-io谁消耗IO最多
--top-latency哪个进程是最大延迟
--top-mem 谁用了最多的内存
CPU调度域(Scheduler domains)
CPU的调度结构类似于文件系统,把CPU组织成倒置的树状结构,所有CPU都属于根域。例如有4颗CPU,分别是0、1、2、3、4CPU,将根域划分为2个子域(子域A和子域B),CPU0和2绑定在子域A,CPU1和3绑定在子域B。如果将进程绑定在根域上,将运行在所有CPU上;如果将进程绑定在子域A上,进程将运行在CPU0和2上。在划分CPU调度域时,不光要将CPU划分其中,内存也要将划分在域内,如果是NUMA结构的,将node划分其中即可;如果是非NUMA结构,每个CPU都要带上自己那段内存。
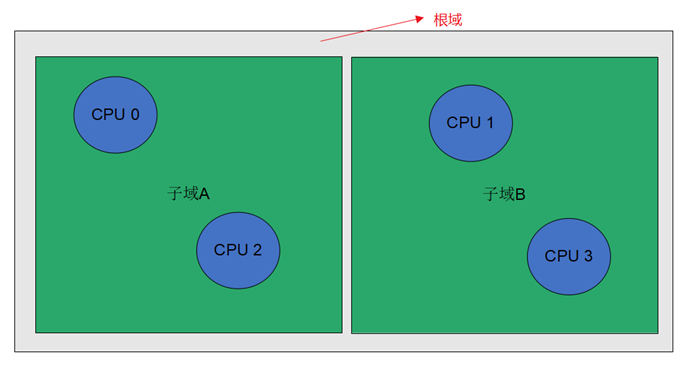
CPU调度域的划分
1、创建一个子目录cpusets
2、编辑/etc/fstab,将文件系统设备cpuset挂载到/cpusets目录下,文件系统类型也叫cpuset
3、挂载完之后自动生成/cpusets/cpus、/cpusets/mems、/cpusets/tasks这几个目录
[root@localhost ~]# mkdir /cpusets
[root@localhost ~]# vim /etc/fstab
cpuset /cpusets cpuset defaults 0 0
[root@localhost ~]# mount -a #挂载命令执行一下
[root@localhost ~]# mount #查看一下是否有挂载
[root@localhost ~]# ls -l /cpusets/
total 0
--w--w--w-. 1 root root 0 Jun 5 10:39 cgroup .event_control
-rw-r--r--. 1 root root 0 Jun 5 10:39 cgroup.procs
-rw-r--r--. 1 root root 0 Jun 5 10:39 cpu_exclusive
-rw-r--r--. 1 root root 0 Jun 5 10:39 cpus
-rw-r--r--. 1 root root 0 Jun 5 10:39 mem_exclusive
-rw-r--r--. 1 root root 0 Jun 5 10:39 mem_hardwall
-rw-r--r--. 1 root root 0 Jun 5 10:39 memory_migrate
-r--r--r--. 1 root root 0 Jun 5 10:39 memory_pressure
-rw-r--r--. 1 root root 0 Jun 5 10:39 memory_pressure_enabled
-rw-r--r--. 1 root root 0 Jun 5 10:39 memory_spread_page
-rw-r--r--. 1 root root 0 Jun 5 10:39 memory_spread_slab
-rw-r--r--. 1 root root 0 Jun 5 10:39 mems
-rw-r--r--. 1 root root 0 Jun 5 10:39 notify_on_release
-rw-r--r--. 1 root root 0 Jun 5 10:39 release_agent
-rw-r--r--. 1 root root 0 Jun 5 10:39 sched_load_balance
-rw-r--r--. 1 root root 0 Jun 5 10:39 sched_relax_domain_level
-rw-r--r--. 1 root root 0 Jun 5 10:39 tasks
[root@localhost cpusets]# cat cpus #cpu查看的根域里包含的cpu有哪些
0
[root@localhost cpusets]# cat mems #查看内存根域有多少段
0
[root@localhost cpusets]# cat tasks #查看运行在根域的进程有哪些
创建cpu的子域
进入/cpusets/目录中
[root@localhost cpusets]# mkdir domain1
[root@localhost cpusets]# cd domain1/
自动创建了以下文件
[root@localhost domain1]# ls -l
total 0
--w--w--w-. 1 root root 0 Jun 5 10:46 cgroup.event_control
-rw-r--r--. 1 root root 0 Jun 5 10:46 cgroup.procs
-rw-r--r--. 1 root root 0 Jun 5 10:46 cpu_exclusive
-rw-r--r--. 1 root root 0 Jun 5 10:46 cpus
-rw-r--r--. 1 root root 0 Jun 5 10:46 mem_exclusive
-rw-r--r--. 1 root root 0 Jun 5 10:46 mem_hardwall
-rw-r--r--. 1 root root 0 Jun 5 10:46 memory_migrate
-r--r--r--. 1 root root 0 Jun 5 10:46 memory_pressure
-rw-r--r--. 1 root root 0 Jun 5 10:46 memory_spread_page
-rw-r--r--. 1 root root 0 Jun 5 10:46 memory_spread_slab
-rw-r--r--. 1 root root 0 Jun 5 10:46 mems
-rw-r--r--. 1 root root 0 Jun 5 10:46 notify_on_release
-rw-r--r--. 1 root root 0 Jun 5 10:46 sched_load_balance
-rw-r--r--. 1 root root 0 Jun 5 10:46 sched_relax_domain_level
-rw-r--r--. 1 root root 0 Jun 5 10:46 tasks
开始绑定第0颗cpu到子域上
[root@localhost domain1]# echo 0 > cpus
[root@localhost domain1]# cat cpus
0
绑定第0段内存到子域上
[root@localhost domain1]# echo 0 > mems
[root@localhost domain1]# cat mems
0
将某个进程绑定到子域上,这个进程就只能在子域的cpu和内存段运行
[root@localhost domain1]# ps axo pid,cmd
[root@localhost domain1]# echo 16380 > tasks #例如将pid为16380的httpd进程绑定到子域上
[root@localhost domain1]# ps -e -o psr,pid,cmd | grep httpd #显示进程在哪一个cpu上运行。查看有没有绑定成功可以cat tasks看看有没有这个pid
如果进程显示cpu未改变,可以进行压力测试重新调度
[root@localhost ~]# ab -n 10000 -c 300 http://127.0.0.1/index.php
用watch监测一个命令的运行结果发现16380已经绑定在子域上了。
[root@localhost domain1]# watch -n 0.5 `ps -e -o psr,pid,cmd |grep httpd`
注:以上数据是通过echo过来的,重启之后都会失效的
另一种手动方式将16380绑定到CPU上
[root@localhost domain1]# taskset -p -c 0 16380 #-p一定要在-c前头
pid 16380's current affinity list: 0 显示16380号进程之前可以运行在0号cpu上
pid 16380's new affinity list: 0 现在可以运行在0号cpu上
四、Linux内存子系统及常用调优参数
内存子系统及常用调优参数:https://blog.csdn.net/Celeste7777/article/details/49560401
内存域
程序能够运行的地址范围大小由CPU的位数决定,这个地址范围称为虚拟地址空间,该空间中的某一个地址称之为虚拟地址。CPU是32位还是64位主要是依据CPU的字组大小(每次能够处理的数据量)而来。例如32位CPU可以支持的地址范围是0~0xFFFFFFFF (2^32=4G),而64位CPU可以支持的地址范围为0~0xFFFFFFFFFFFFFFFF (2^32个4G)。
一般而言在32位系统中,较低地址空间的1GB(虚地址0xC0000000到0xFFFFFFFF)供内核使用,称为内核空间。而较高地址空间的3GB(虚地址0x00000000到0xBFFFFFFF)供各个进程使用,称为用户空间;因为每个进程可以通过系统调用进入内核,因此,内核空间由系统内的所有进程共享;从单个进程的角度来看,每个进程都可以拥有4GB的虚拟地址空间(也叫做虚拟内存)。再深入内核空间看,其低地址位置有16MB给DMA(ZONE_DMA),从16M到896M才是内核可以直接访问的地址空间(ZONE_NORMAL),从896M到1G这段空间是预留的物理地址空间(Reserved)。内核不能直接访问用户空间,要想访问必须把其中的一段内容映射到Reserved来,在Reserved中保存即将要访问那段内存的地址编码,内核才能去访问,所以在32位系统上内核不能直接访问大于1G的内存地址。
在Linux64位系统中,低地址空间的1G内存都给了DMA,这个时候DMA的寻址能力就大大加强了;1G以上的地址空间给划分了ZONE_NORMAL,这段空间都可以被内核直接访问。所以在64位上,内核可以直接访问大于1G的内存地址,不再需要额外的步骤,效率和性能上也大大增加。

Linux的虚拟内存子系统包含了以下几个功能模块:
1、slab allocator
2、buddy system
3、kswapd
4、pdflush
5、mmu
buddy system是工作在MMU之上的,而slab allocator又是工作在buddy system之上的。
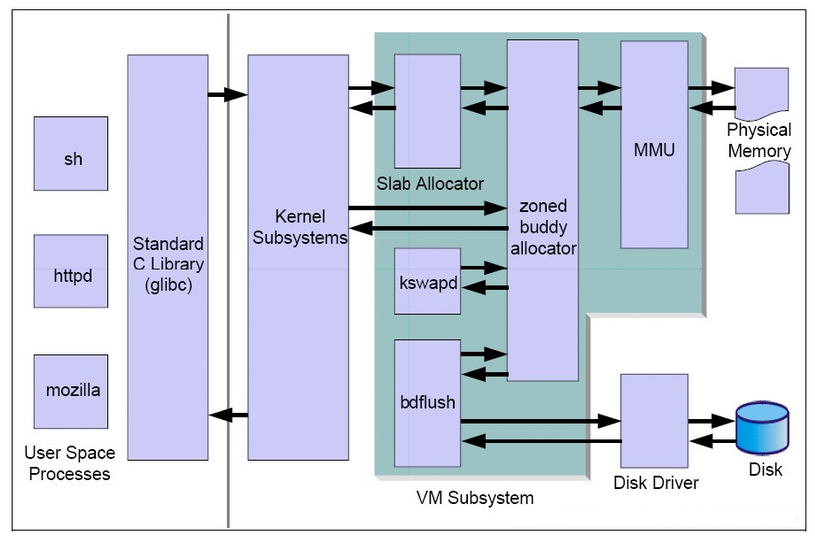
MMU(Memory Management Unit):内存管理元
物理地址(Physical Address):指的是CPU外部地址总线上寻址物理内存的地址信号,是地址变换的最终结果。
虚拟地址(Virtual Address):也称为逻辑地址,由段选择符和段内偏移地址两个部分组成。
线性地址(Linear Address):是VA到PA变换的中间层。程序代码会产生LA(段中的偏移地址),加上相应段的基地址就生成了一个线性地址。如果启用了分页机制,那么线性地址可以再经变换以产生一个PA。若没有启用分页机制,那么线性地址直接就是PA。
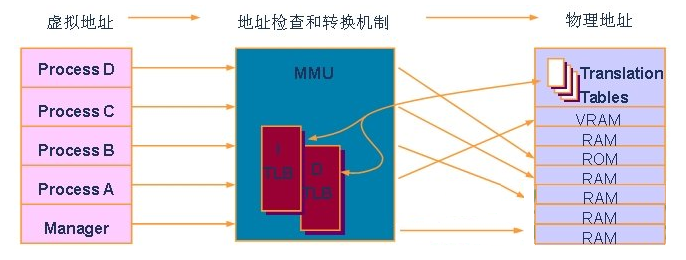
内存管理单元是CPU中用来管理虚拟存储器、物理存储器的控制线路的组件,同时也负责将虚拟地址映射为物理地址,以及提供硬件机制的内存访问授权。ARM出品的CPU,MMU作为一个协处理器存在。ARM MMU提供的分页机制有1K/4K/64K 3种模式;INTEL出品的80386CPU或者更新的CPU中都集成有MMU,X86 MMU提供的寻址模式有4K/2M/4M的page模式(根据不同的CPU,提供不同的能力)。