————————————————————————————————————————————
单链表
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
概念://单链表基本概念图(基本中的基本)

定义:
//初始化
带头结点
1 void InitList(Node **head) 2 { 3 *head = (Node *)malloc( sizeof(Node)); 4 (*head)->next = NULL; 5 }
不带头结点
1 void InitList(Node **head) 2 { 3 *head = NULL; 4 }
//插入:
带头结点
1 void CreatList(Node **head) 2 { 3 Node *r = *head, *s; 4 int a; 5 while(scanf("%d", &a)) 6 { 7 if(a != 0) 8 { 9 s = (Node *)malloc(sizeof(Node)); 10 s->value = a; 11 r->next = s; 12 r = s; 13 } 14 else 15 { 16 r->next = NULL; 17 break; 18 } 19 } 20 }
不带头结点
1 void CreatList(Node **head) 2 { 3 Node *p, *t; /*p工作指针,t临时指针*/ 4 int a, i = 1; 5 while(scanf("%d", &a)) 6 { 7 if(a != 0) 8 { 9 t = (Node *)malloc(sizeof(Node)); 10 t->value = a; 11 if(i == 1) 12 { 13 *head = t; 14 } 15 else 16 { 17 p->next = t; 18 } 19 p = t; 20 } 21 else 22 { 23 p->next = NULL; 24 break; 25 } 26 i++; 27 } 28 }
//操作
带头结点
1 Node *temp; 2 temp = head->next; 3 while(temp != NULL) 4 { 5 //... 6 temp = temp->next; 7 }
不带头结点
1 Node *temp; 2 temp = head; 3 while(temp != NULL) 4 { 5 //... 6 temp = temp->next; 7 }
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
如何在单链表中插入节点:
//头插法
在堆中申请一个新的内存空间用来存放结点,填充信息域,把Head指针的指向擦除并指向新的结点,新的结点指向原来的第一个结点的地址;
示例:

输入:0 1 2 3 4 5 6 7 8 9
输出:

分析:
//第一次插入节点

//循环i执行第二次插入

- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
//尾插法
将数据插在链表的尾部,修改最后节点的指针指向新节点,新节点的指针指向NULL
示例:
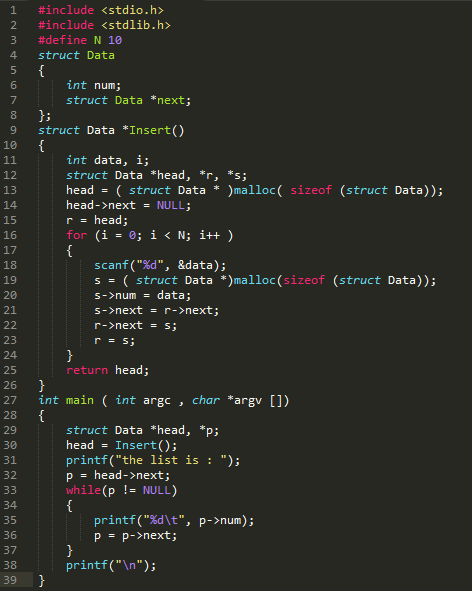
输入:0 1 2 3 4 5 6 7 8 9
输出:

分析:
//第一次插入节点

//循环i执行第二次插入

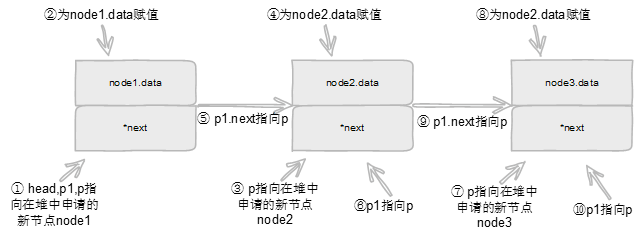
示例2:
分析://与上一例同理
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
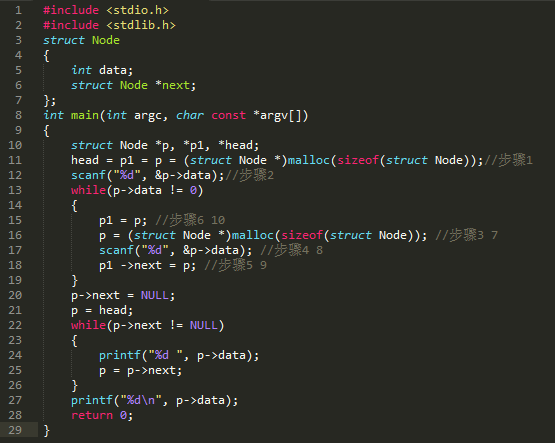
链表传参的三种方式
//实参传head的地址,形参定义双指针
在该种方式中关于为什么要在AddNode方法前加 **,分析在本文末尾

//实参传指针head,形参取地址

//返回值调用
利用函数的返回值,返回链表头。
缺点是不能返回多个函数。
示例:

- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
释放链表空间
1 void ReleaseHead(struct Test **head) //释放链表空间 2 { 3 struct Test *temp; 4 while(*head != NULL) 5 { 6 temp = *head; 7 *head = (*head) ->next; 8 free(temp); 9 } 10 }
示例:

输出:
//输出执行成功,此时head==NULL;

- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
关于为什么要使用双指针调用(新增/释放节点时)
示例:
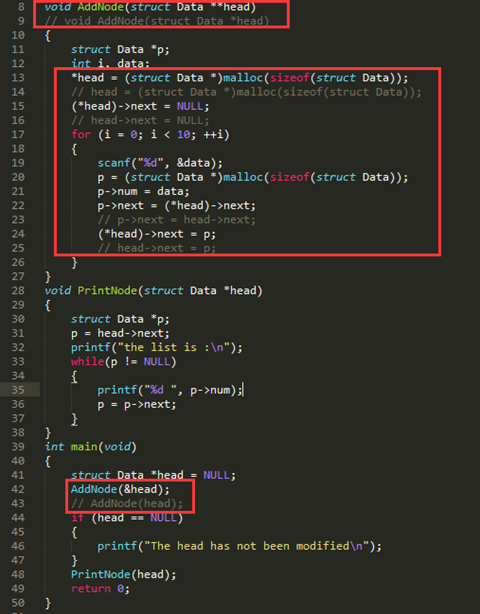
输出:
//使用双指针即正确输出
//使用注释掉的语句(单指针)则head指针的地址为NULL,此时head没有申请分配到地址

结论:
当调用AddNode传递的是&head,接收的形参是**head时,链表正常。
当传递的是head,接收的形参是*head时,指针head在AddNode中没有被修改,依然处于未分配内存空间的状态。
分析:
在这里和正常函数值传递是一样的,假设int a,作为参数传入时没有被修改,修改的是拷贝的临时变量a,所以需要a的指针。在这里同理,也是需要传入head的指针,即指向Data结构体的指针的指针。
如果主函数调用的是AddNode(head);,函数调用时取head的地址 void AddNode(struct Data *&head),结果也是有效的
一般来说, 初始化链表之类的需要双指针(例如:翻转链表因为不是在原始链表上翻转,而是返回新的链表头,所以也需要双指针)。像求链表长度、插入节点、打印输出就只要单指针。
在子函数中传递指针时,子函数的形参要用指针的地址,就是双重指针,也叫二级指针。定义二重指针目的是为了当指针作为函数参数时候,在链表调用时候能改变头指针的地址,从而能调动整个链表,用一级指针的话只能改变一个结点的值。