摘要:选择轻量化、免运维、低成本的大数据云服务是业界趋势,如果搭建Zeppelin再同步自建一套Hadoop生态成本太高!因此我们通过结合华为云MRS服务构建数据中台。
本文分享自华为云社区《MRS大数据平台结合Apache Zeppelin让数据分析更便捷》,作者: dullman。
Apache Zeppelin:一款大数据分析和可视化工具,可以让数据分析师在一个基于Web的notebook中,采用不同语言对不同数据源中的数据进行交互式分析,并对结果进行可视化图表的展示。
云服务MRS:华为云提供的一站式大数据平台,包含Hudi、ClickHouse、Spark、Flink、Kafka、Hive、HBase等丰富的大数据组件,完全兼容开源生态。 本文介绍如何搭建Zeppelin并连接Hive、HBase进行简单的数据开发。
为什么写这篇文章?
- Zeppelin相关的文章虽然很多,但是都没有与实际大数据平台结合的实践案例指导。
- Zeppelin的搭建存在不少坑,因此记录下部署中的各个问题,为后人填坑。
- 选择轻量化、免运维、低成本的大数据云服务是业界趋势,如果搭建Zeppelin再同步自建一套Hadoop生态成本太高!因此我们通过结合华为云MRS服务构建数据中台。
环境准备
- Apache Zeppelin 0.9.0安装包
- MRS 3.1.0普通集群 (包含Hive、HBase组件)
- ECS centos7.6
安装MRS客户端
MRS客户端提供java、python开发环境,也提供开通集群中各组件的环境变量:Hadoop、Hive、HBase、flink等。
参见登录ECS安装集群外客户端
安装Zeppelin
- 使用Xftp等工具导入主机并采用以下命令安装在/opt/zeppelin目录。
tar -zxvf zeppelin-0.9.0-bin-all.tgz mv zeppelin-0.9.0-bin-all /opt/zeppelin
- 配置Zeppelin环境变量,在profile文件中加入变量
vi /etc/profile export ZEPPELIN_HOME=/opt/zeppelin export PATH=ZEPPELIN_HOME/bin:ZEPPELINHOME/bin:PATH
- 导入环境变量
source /etc/profile
- 编辑zeppelin-env.sh文件,加入JAVA_HOME,这里需要替换成自己的环境变量
cd /opt/zeppelin/conf/ cp zeppelin-env.sh.template zeppelin-env.sh source /opt/hadoopclient/bigdata_env echo “export JAVA_HOME=/opt/hadoopclient/JDK/jdk-8u201”>>zeppelin-env.sh
- 编辑zeppelin-site.xml文件,将zeppelin.server.port 8080替换成18081(可自定义,也可以不改);将zeppelin.anonymous.allowed参数的true修改为false
cd /opt/zeppelin/conf cp zeppelin-site.xml.template zeppelin-site.xml vi zeppelin-site.xml
<property>
<name>zeppelin.server.port</name>
<value>18081</value>
<description>Server port.</description>
</property>
<property>
<name>zeppelin.anonymous.allowed</name>
<value>falase</value>
<description>Anonymous user allowed by default</description>
</property>
- 编辑shiro.ini文件,新增用户developuser
cp shiro.ini.template shiro.ini
vi shiro.ini
在[users]下新增用户developuser,密码Huawei@123,权限admin
developuser=Huawei@123, admin

- 运行Zeppelin(并检查启动参数)
cd /opt/zeppelin
bin/zeppelin-daemon.sh start

ps ef | grep zeppelin
- 关闭防火墙,允许端口18081(此为测试环境,生产环境建议采取更安全措施) systtemctl stop firewalld
- 完成以上配置,并启动成功后,在浏览器中输入地址zeppelin_ip:18081(zeppelin_ip为安装zeppelin的HD客户端IP),即可看到如下界面。

- 使用developuser登录,就可以基于note进行大数据的交互式开发了!
Zeppelin连接Hive
1、将Zeppelin中jdbc依赖的jar包替换成MRS客户端中Hive/Beeline/lib中的jar包,保证hive Interpreter依赖的Jar包存在
cp -f /opt/Bigdata/client/Hive/Beeline/lib/*.jar /opt/zeppelin/interpreter/jdbc/
2、修改Zeppelin配置,添加Client Hive Url
查询CLIENT_HIVE_URL
source /opt/hadoopclient/bigdata_env
echo $CLIENT_HIVE_URI
编辑interpreter.json,位置/usr/zeppelin/conf/interpreter.json,修改JDBC default.url,default.driver.
"jdbc": { "id": "jdbc", "name": "jdbc", "group": "jdbc", "properties": { "default.url": { "name": "default.url", "value": "jdbc:hive2://192.168.1.188:24002,192.168.1.234:24002,192.168.1.241:24002/;serviceDiscoveryMode\u003dzooKeeper;zooKeeperNamespace\u003dhiveserver2", "type": "string", "description": "The URL for JDBC." }, "default.user": { "name": "default.user", "value": "gpadmin", "type": "string", "description": "The JDBC user name" }, "default.password": { "name": "default.password", "value": "", "type": "password", "description": "The JDBC user password" }, "default.driver": { "name": "default.driver", "value": "org.apache.hive.jdbc.HiveDriver", "type": "string", "description": "JDBC Driver Name" }
3、重启zeppelin
bin/zeppelin-daemon.sh restart
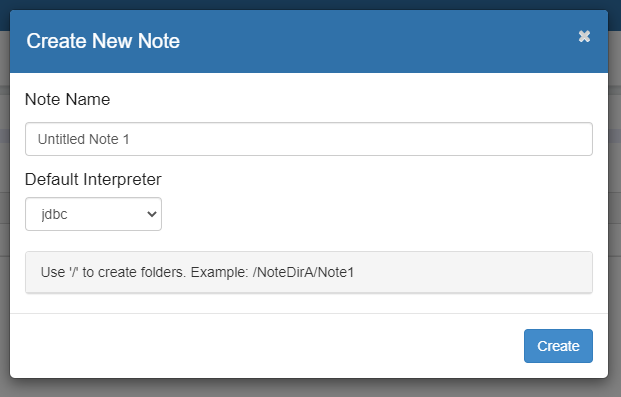
4、创建Notebook,选择default interpreter 为jdbc
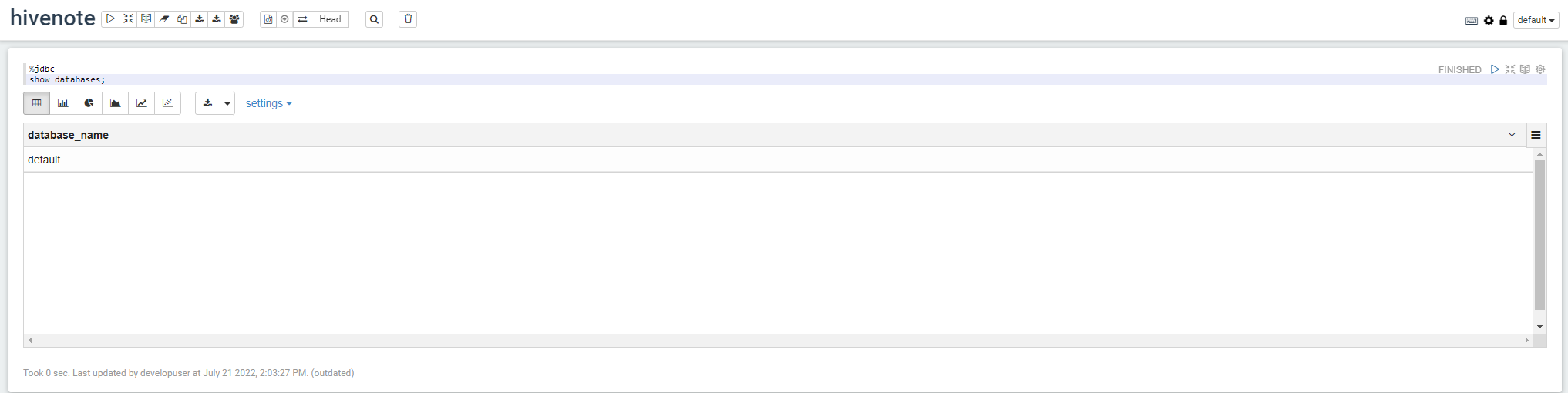
5、在notebook上使用Hive SQL进行查询
查询数据库 %jdbc show databases;
创建Hive表 %jdbc create external table stu (s_id string,s_name string) row format delimited fields terminated by ‘\t’;

Zeppelin连接HBase
1、将Zeppelin中hbase依赖的jar包替换成MRS客户端中HBase中的jar包,保持jar的一致
- 先将/opt/zeppelin/interpreter/hbase/目录下原本的Jar包移走
cd /opt/zeppelin/interpreter/hbase mkdir hbase_old_jar mv hbase*.jar hbase_old_jar mv hadoop*.jar hbase_old_jar mv zookeeper-3.4.6.jar hbase_old_jar
- 再将/opt/hadoopclient/HBase/hbase/lib/下的jar包拷贝至/opt/zeppelin/interpreter/hbase/。
cp -f /opt/hadoopclient/HBase/hbase/lib/*.jar /usr/zeppelin/interpreter/hbase/
2、修改Zeppelin配置
编辑zeppelin-env.sh,加入hbase环境变量
export HBASE_HOME=/opt/hadoopclient/HBase/hbase
编辑interpreter.json,位置/opt/zeppelin/conf/interpreter.json,修改hbase.home
"hbase.home": { "name": "hbase.home", "value": "/opt/hadoopclient/HBase/hbase", "type": "string" }
3、重启zeppelin
bin/zeppelin-daemon.sh restart

4、配置Interpreter
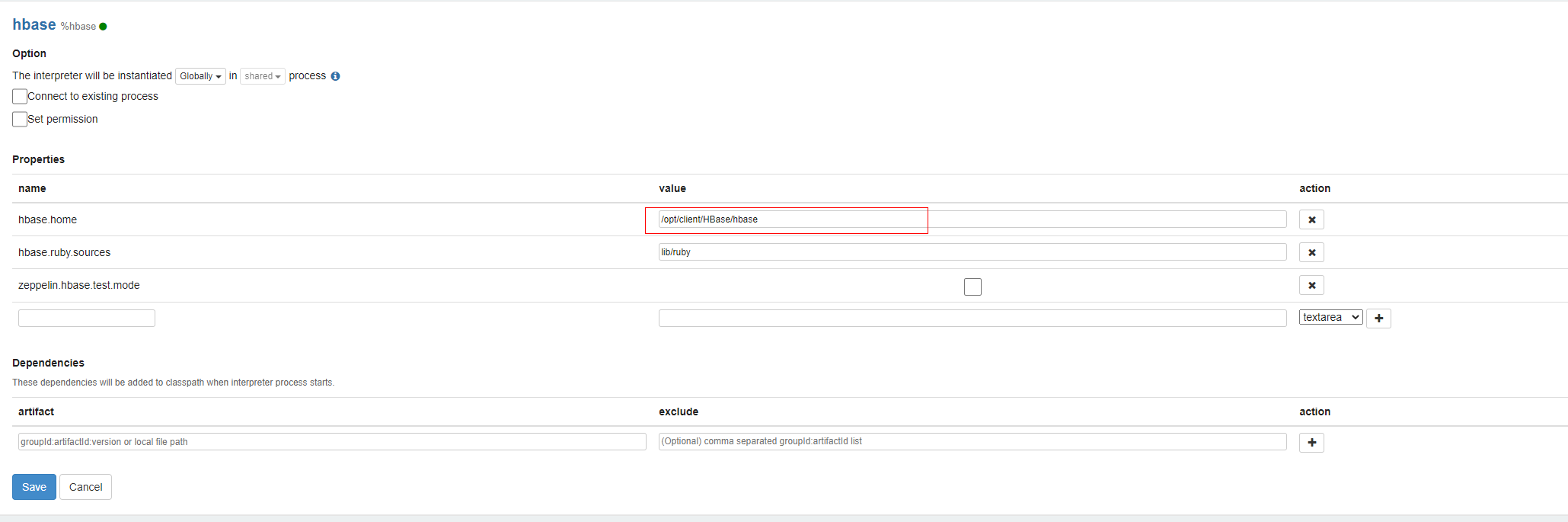
从web界面右上角菜单中Interpreter中进入,配置Interpreter
选择Hbase,修改如下配置,并保存配置。
hbase.home : /opt/client/HBase/hbase
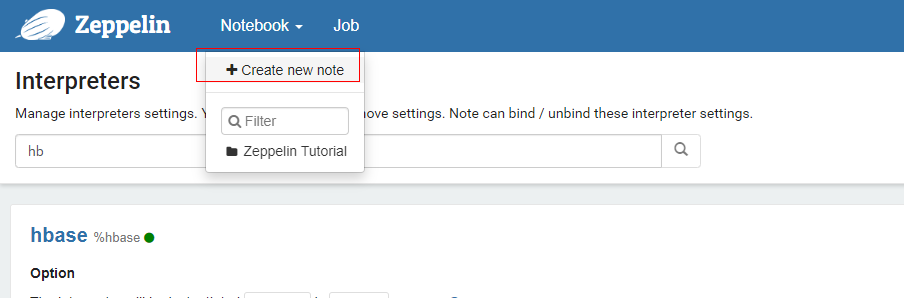
5、创建note进行数据开发
页面选择Notebook →create new note
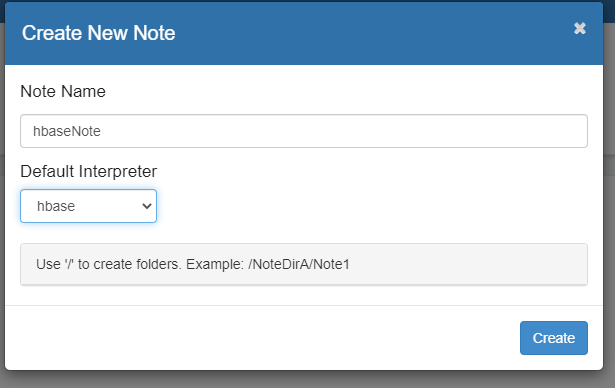
自定义Note名称,例如hbaseNote,并指定Interpreter为HBase。
编辑Note,点击右侧“执行”按钮(三角标志)
%hbase
create ‘test6’, ‘cf’
put ‘test6’, ‘row1’, ‘cf:a’, ‘value1’
若在创建Interpreter未指定default Interpreter,需要在note最前面加上%hbase进行指定。
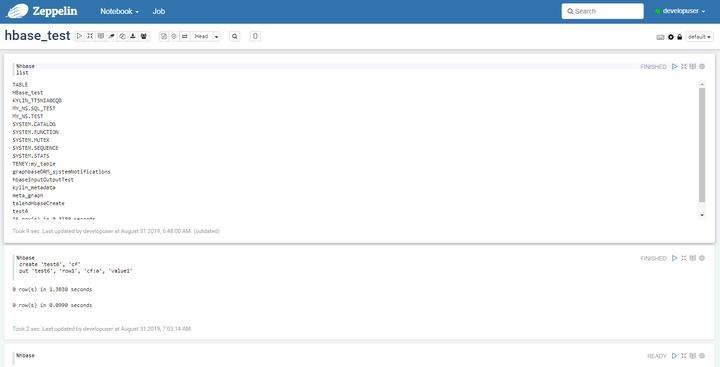
6、在FusionInsight客户端下查看刚刚通过Zeppelin创建的hbase表test6和数据

其他Hadoop生态组件在云服务MRS上的实践参考
基于云服务MRS构建DolphinScheduler2调度系统