摘要:本文分享下MindSpore中算子的使用和遇到问题时的解决方法。
本文分享自华为云社区《【MindSpore易点通】算子使用问题与解决方法》,作者:chengxiaoli。
简介
算子的调用是构建模型的基础,准确的找到能满足需求的算子并能正确的使用,可以有事半功倍的效果。本次就分享下MindSpore中算子的使用和遇到问题时的解决方法给大家。
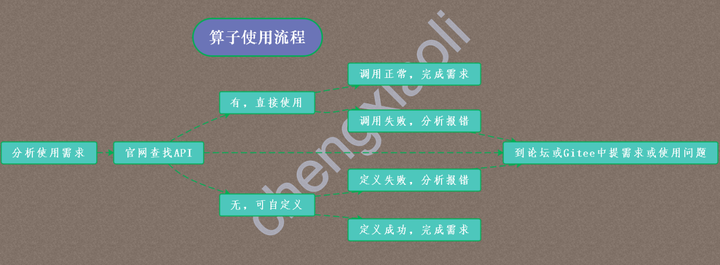
图中是简单的归纳了算子使用的这几个步骤,本文的内容主要是根据图中的步骤再进行解析说明。
分析使用需求
首先了解下什么是算子,通俗的说对一个函数进行某一项操作都可以认为是一个算子,最基础的就是加减乘除这些操作。所以算子并不难理解,只是很多算子它包含的计算会更加的复杂。
一般情况下在自定义网络模型时会用到各种类型的算子,MindSpore中分为Primitive算子和nn算子,Primitive算子是开放给用户的最低阶算子接口,一个Primitive算子对应一个原语,它封装了底层的Ascend、GPU、AICPU、CPU等多种算子的具体实现,为用户提供基础算子能力。
还可以继续分为计算算子和框架算子。计算算子主要负责具体的计算,而框架算子主要用于构图,自动微分等功能,都可以从mindspore.ops模块导入使用。同时mindspore.nn模块是对mindspore.ops模块的封装。所以在构建网络模型时建议使用mindspore.nn模块,优点是使用方便,当然如果想要探索更多算子的信息,建议使用mindspore.ops模块。
需求大致可以分成两种,自定义网络模型时的算子需求和从第三方框架迁移模型时对标算子的需求。
这里给大家提供一个对比第三方框架算子使用的样例给大家参考。
样例:nn.Embedding 层与pytorch相比缺少了Padding操作,有其余的算子可以实现吗?
分析:在PyTorch中padding_idx的作用是将embedding矩阵中padding_idx位置的词向量置为0,并且反向传播时不会更新padding_idx位置的词向量。
方法:在mindspore中,可以手动将embedding的padding_idx位置对应的权重初始化为0;并且在训练时通过mask的操作,过滤掉padding_idx位置对应的Loss。MindSpore中与Mask相关的算子有:nn.Dropout、RandomChoicWithMask、NMSWithMask。
类似样例中的情况,就需要我们对计算过程分析清楚,当没有完全匹配的算子时也需要考虑将需求拆分为多步进行。当然我们不可能对所有算子的特性都了解,所以当遇到疑惑是请访问这里:宇宙尽头
官网查找接口
在清楚需求之后,就需要找到能够实现需求的算子了,查找这一步相对简单,官网中有算子的目录和详细的使用介绍页面,能迅速定位到相同类型算子的位置,查看算子详情页查看是否有合适的算子,在将算子加入到复杂的脚本前,建议先只单独运行算子样例试一试。
自检:当然即使找到了符合需求的算子,并且单独运行时也没有问题,也不能够避免在加入到自己的项目代码中完全不报错。在算子使用中通常的报错原因是使用的MindSpore版本和参考的教程不一致、算子不支持目前的硬件环境以及传入的参数不符合算子要求,所以为了避免不必要的报错,下面给大家提供几个查看接口的正确姿势:
- 根据自己安装的MindSpore版本查找对应版本的接口;
- 第三方模型迁移时建议先通过API映射查找;
- 查看算子是否支持自己的硬件平台以及内存大小;
- 重点:到算子详情页查看参数和参数的类型。
BUG:报错不要慌,论坛来帮忙:如果以上几点方法还是不能够避免报错,并且报错的信息也不能够帮助定位并解决问题,那么请到论坛发求助帖子,或许您是遇到BUG啦。
这里找出两个算子的特性和用法给大家参考:
样例1:如何让算子输出之一为tuple类型或list类型?
方法:框架的算子输出只支持Tensor类型,不支持tuple或list。
样例2:mindspore中可以直接打印卷积核的参数吗?
方法1:是可以直接打印的
net = nn.Conv2d(***)
print(net.weight)
print(net.weight.asnumpy)
方法2:也可以使用for循环遍历
for *** net.get_parameters()
算子的自定义
MindSpore也在一直更新和完善中,也会有暂不支持的算子,遇到这种情况欢迎大家提需求到论坛或者Gitee中,官网也有完整的自定义算子教程,欢迎大家进行算子的开发,感谢大家的贡献。
自定义算子教程:
自定义算子(CPU):https://mindspore.cn/tutorials/experts/zh-CN/master/operation/op_cpu.html#
自定义算子(GPU):https://mindspore.cn/tutorials/experts/zh-CN/master/operation/op_gpu.html#
自定义算子(Ascend):https://mindspore.cn/tutorials/experts/zh-CN/master/operation/op_ascend.html
样例:怎样自定义让一个Tensor包含的值作为另一个Tensor的下标?
方法:既然是自定义算子,第一个tensor可以改为int类型或者listint类型啊。下面的sizes是listInt,exclude_outside是int
attr.list=sizes,exclude_outside attr_sizes.type=listInt attr_sizes.value=all attr_sizes.paramType=required attr_exclude_outside.type=int attr_exclude_outside.value=all attr_exclude_outside.paramType=optional attr_exclude_outside.defaultValue=0
干货分享:除了以上的教程和样例,也有优秀的论坛成员分享的自定义算子的详细过程和体会:
- 自定义算子(CPU)windows版本:
https://bbs.huaweicloud.com/forum/thread-175270-1-1.html
- 深夜:在?我用本地环境pytest带你玩自定义算子:
https://bbs.huaweicloud.com/forum/thread-177908-1-1.html
通过上图指导,在遇到使用报错或者自定义算子报错时,也可以到论坛或者Gitee中展示遇到的问题。
总结
以上就是分析使用需求、选择算子、解决报错的过程,欢迎大家多尝试,因为有论坛在给您保驾护航,重要发现:宇宙的尽头是论坛。