摘要:本期将从GaussDB(for Influx)数据模型谈起,分享GaussDB(for Influx)数据建模的最佳方法,避免一些使用过程中的常见问题。
本文分享自华为云社区《华为云GaussDB(for Influx)揭秘第七期:最佳实践之数据建模》,作者: GaussDB 数据库。
华为云GaussDB(for Influx)时序数据库面向工业物联网海量时序数据场景提供数据安全、高性能、低存储成本、免运维等能力,受到越来越多企业的关注;同时,即开即用、使用简单、类SQL查询语句、无需设计schema、适合业务快速迭代等特点,也越来越得到开发者的认可。
但是随着业务规模不断增加,也会遇到诸如时间线暴涨、查询时延高、Tag和Field同名导致查询数据时有时无等问题,其根本原因是,在使用过程中没有良好的数据模型设计。本期将从GaussDB(for Influx)数据模型谈起,分享GaussDB(for Influx)数据建模的最佳方法,避免一些使用过程中的常见问题。
01 数据模型与关键概念
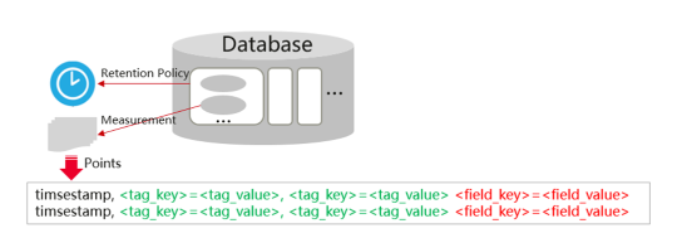
Database
与MySQL中Database概念相同。
创建命令:CREATE DATABASE “mydb”。
用户权限、数据保留策略都以Database为粒度设置。比如赋予用户对“mydb”数据库只读权限:GRANT read ON mydb TO username。
Measurement
与MySQL中Table概念类似。所不同的是,GaussDB(for Influx)属于Schemaless,Measurement不需要提前创建,也不需要设计表中的字段和类型。写入数据时自动创建Measurement,字段可以任意新增和减少,但要求相同字段的数据类型必须一致。

Retention Policy(RP)
数据保留策略,是关系型数据库中不存在的概念,专为时序场景设计,意为指定数据在数据库中的最长保存时间,过期数据会自动被清理。
Tag
数据源标识,只支持string类型
Field
采集指标,支持string,float,int,bool类型
Line Protocol(数据模型)

如图所示,写数据到GaussDB(for Influx),单条数据由measurement、Tag_key、Tag_value、Field_key、Field_value、timestamp 6部分组成。<Tag_key= Tag_value>可以1个或多个,<Field_key=Field_value>可以1个或多个,每条数据必须要携带时间戳。
Point(点)
Point通常包含measurement+Tags+Field+timestamp 4个部分。例如,如下数据包含2个Point。
<monitorInfo,area=“葡萄花”,,device=“钻机A” pressure=1.8,level=35 1650443961100400200> Point1: <monitorInfo,area=“葡萄花”,device=“钻机A”,pressure=1.8 1650443961100400200> Point2: <monitorInfo,area=“葡萄花”,device=“钻机A”,level=35 1650443961100400200>
即,一条数据包含多少Field Key,则可以简单认为存在多少Point。在GaussDB(for Influx)中,可以一条数据包含一个Point,也可以包含多个Point。
Series(时间线)
在GaussDB(for Influx)里,我们将一个指标+一组Tag组合称为一条时间线。在一条时间线下面,连续时间点的采样数据则为时序数据。比如有数据:
monitorInfo,area=”葡萄花”,device=”钻机A”,pressure=1.8,1650443961100400200 monitorInfo,area=”葡萄花”,device=”钻机B”,pressure=1.6,1650443961100400200 monitorInfo,area=”榆树林”,device=”钻机B”,pressure=1.7,1650443961100400200 monitorInfo,area=”榆树林”,device=”钻机A”,pressure=1.5,1650443961100400200
表示4条时间线,分别是:
葡萄花油田的钻机A上的压力传感器(pressure)
葡萄花油田的钻机B上的压力传感器(pressure)
榆树林油田的钻机B上的压力传感器(pressure)
榆树林油田的钻机A上的压力传感器(pressure)
02 数据建模之最佳实践
通常,数据建模是为了让查询更简单、更高效。对于大多数使用情形,我们建议使用以下设计准则:
1、合理设计Tag 和Field
- Tag只支持字符串类型,数值和布尔类型数据应该被设计为Field;
- 将常用查询条件和分组条件设计为Tag;
因为Tag会创建索引,而Field则没有索引。比如在业务中,经常会查询某一台机器的平均CPU利用率:
SELECT mean(cpu) FROM monitor WHERE host=“192.168.1.1” AND time > now() – 1h
或者查询风电场每台风力发电机每小时的平均发电量:
SELECT mean(elect) FROM monitor WHERE farm_id=“737f738a-bd63” AND time > now() – 24h GROUP BY time(1h),device_id
则应该将上述查询语句中的 host、farm_id、device_id 设置为Tag,前提是字符串类型才能被设为Tag。
- time属于内置关键字,不能作为Tag_key和Field_key;
- 使用InfluxQL函数(Max、Min、Count等)的字段,作为Field存储。
2、 遵守Tag_Key 和Field_Key的命名约定
- 不使用保留关键字作为Tag和Field的key(名称);
- Tag和Field不使用相同名称,否则会出现不可预料的问题;
- Tag和Field名称尽量简短清晰,可以节约Index内存空间,同时会让查询更加高效;
- 避免一个Tag中包含多层意思,比如machine = “192.168.2.1-Ubuntu”,包含ip地址和操作系统名称,建议拆分为两个Tag:host和os;
- 建议将变化小的数据设置为Tag,比如进程名称可以设为Tag,而进程号则建议设置为Field。
3、避免超过节点规格所能承受的时间线数量
GaussDB(for Influx)规格与时间线数量对应关系如下:
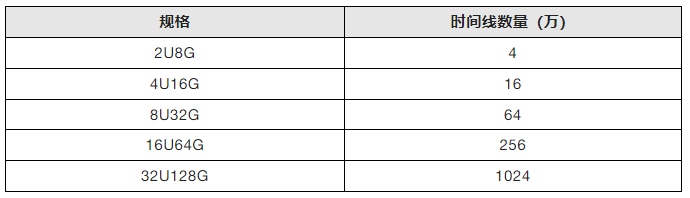
时间线过度超过限制,会引起性能急剧下降,可能会影响业务运行,需要考虑对节点扩容。
4、避免一张表中存在过多Tag或者 Field
建议一张表存放同一类业务数据,比如物流车辆监测数据。过多业务数据放置到同一张表,会造成Tag和Field数量激增,直接影响查询效率。Field太多时,每个Field的计算都会单独计算,当执行模糊查询时可能会导致查询超时。
5、避免同一个Retention policy存储多用户数据
不同业务数据的过期时间不尽相同,应根据业务具体需求分别存储在不同的RP中,否则过期数据不能及时删除,依然占据存储空间,增加了数据存储成本,影响了查询效率。
6、避免同一个Database存储多用户数据
由于当前GaussDB(for Influx)的权限控制粒度是DB级别,同一个Database保存多用户数据,容易导致数据被其他用户访问和修改。建议不同用户使用单独Database,并且只对单一用户授予访问权限。
03 总结
在制造、能源、农业、电力等工业物联网行业中,大部分数字化信息系统是构建在MySQL等关系型数据库基础上。但随着企业业务和规模的进一步扩大,数据量迅速增长,MySQL等关系型数据库面临并发数、存储成本、查询性能、扩展性、维护等诸多问题,正逐渐被时序数据库所替代。
GaussDB(for Influx)摒弃关系型数据库范式化繁复的设计规则,支持Schemaless设计,业务能按照简单、高效的方式建模。面对业务变化快、接入设备多样化严重的工业物联网场景,GaussDB(for Influx)数据建模表现更加灵活,无需更改业务即可兼容不同设备,更适用于工业物联网场景。
04 结束
本文作者:华为云数据库创新Lab & 华为云时空数据库团队。欢迎加入我们!
云数据库创新Lab(成都、北京)简历投递邮箱:xiangyu9@huawei.com
华为云时空数据库团队(西安、深圳)简历投递邮箱:yujiandong@huawei.com