摘要:本文从读取和写入的角度分别描述了行存和列存的IO模型,并对文件结构做了简单介绍。
本文分享自华为云社区《GaussDB(DWS)基本IO框架》,作者: Naibaoofficial。
行存IO管理框架
存储结构
- OID(Object identifiers):对象的唯一标识。
- 每个表存在对应数据库的文件夹中,用relfilenode标识。
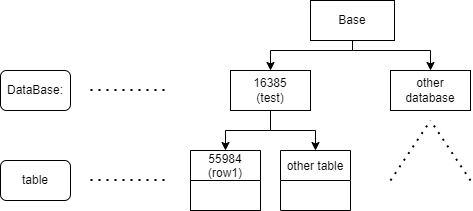
例如表row1,可以直接查询对应的文件
test=# select pg_relation_filepath('row1'); pg_relation_filepath ---------------------- base/16385/55984 (1 row)
- 每个表的读取写入以页(文件块)为基本单位,页的大小是一个BLCKSZ,默认8KB,其结构如下:
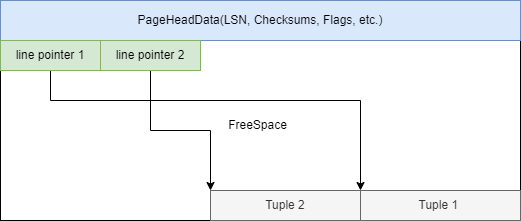
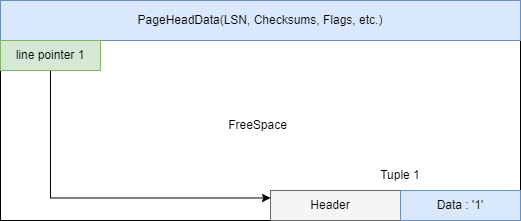
- Tuple保存了当前一行的数据,分为Header和Data两块,头部保存元组的相关信息(列数,事务信息,是否有Toast表等)。
- 每个Tuple最大为2kb,若Data过大无法压缩至2KB,则采用额外的Toast表存储,此时Tuple内的Data保存Toast表的相关信息。
GaussDB 行存框架:
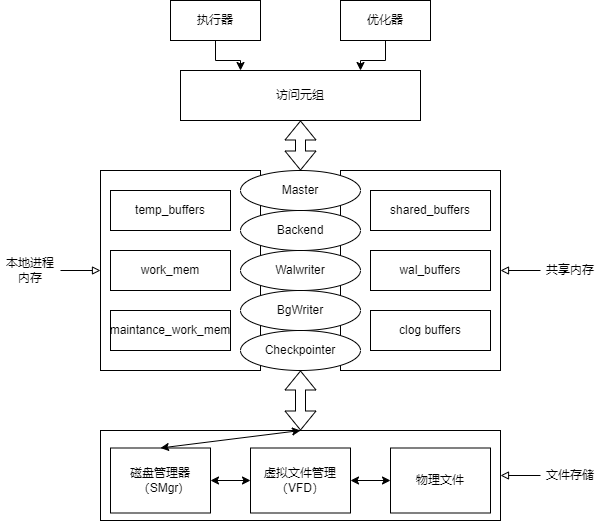
这里面涉及到几个比较大的内核机制:
- 本地缓存:
这里面的本地缓存介绍了三个比较常用的缓存结构,这里直接引用了官方的英文解释。
temp_buffers: Sets the maximum number of temporary buffers used by each database session. These are session-local buffers used only for access to temporary tables.
work_mem: Specifies the amount of memory to be used by internal sort operations and hash tables before writing to temporary disk files.
maintenance_work_mem: Specifies the maximum amount of memory to be used by maintenance operations, such as VACUUM, CREATE INDEX, and ALTER TABLE ADD FOREIGN KEY.
- 共享内存:可由整个Gaussdb共享
包括shared_buffer和wal_buffer, 分别用来存放Page和Clog,Wal Segment。
- WalWriter,BgWriter:
主要是将共享内存的内容落盘,WalWriter一般是在事务提交时就需要落盘,但是有时候可以放弃一定的事务一致性原则,从而让WalWriter异步落盘加快速度。BgWriter负责将shared_buffer中的内容落盘。
- 外存管理:
负责上层与外存之间的文件交互。
IO管理框架:读取
读取的过程相对简单,就是从物理文件先装到shared_buffer中,然后从shared_buffers返回相关的结果。
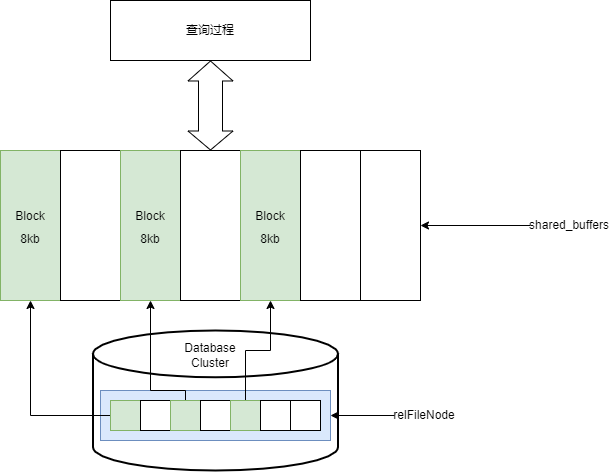
shared_buffers中就是以Page为单位进行存储的,因为每个Page的大小是固定的,所以shared_buffers能存放的page个数也就是确定的。这里面就需要考虑一个问题,因为这个资源是共享的,如果一个线程读取了大量的文件,这样势必会使得其他线程的缓存命中率下降。
GaussDB在这里引入了Ringbuffer的机制,可以限制一个线程所使用的shared_buffers的大小,从而解决掉这个问题。
IO管理框架:写入
- 写入操作是增加的新的元组,Update操作相当于先Delete,再Insert。
- INSERT
- UPDATE
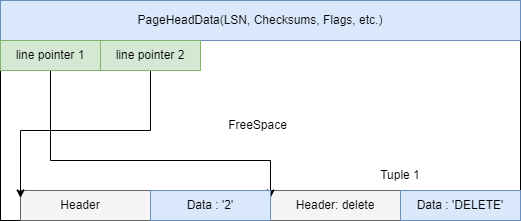
将旧元组标记为Dead,然后插入新的元组,由Vacuum负责清理。当然,这里面Data变为DELETE只是用来描述删除的是此Tuple,实际上Data当中的值是不变的。
- 写入的整体逻辑:
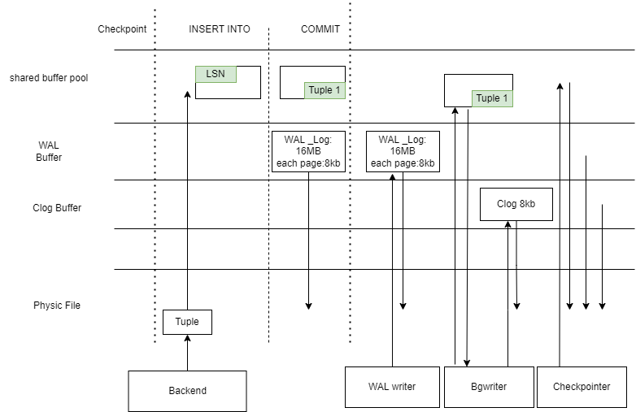
GaussDB行存在写入时,将元组信息先写入到shared_buffers,然后用bgwriter刷入磁盘,这样在事务提交时就可以避免磁盘的IO开销,提升性能,为了保证一致性和恢复,使用wal日志和checkpoints可以实现日志先落盘(也可以异步)和redo等操作。
列存的IO管理框架
列存的存储单元
- 列存的存储单元为CU(CStore Unit)
- CU的大小为8k对齐
- 适合大批量导入的场景
- 同一列的CU存在一个新文件中,大于1GB时,切换到新文件中。
- 列存用一个CUDesc的行存表描述CU的相关信息,可以理解成为一个Toast表。
- CUDesc:行存表,记录CU的相关信息, 主要属性如下:
- col_id,cu_id: 第col_id列,第cu_id个CU
- min, max, row_count, size
- cu_mode: information mask(RLE,LZ4,Delta表等)
- cu_pointer:指向每一个CU,记录delete bitmap
- magic:和CU头部的magic相同,校验使用
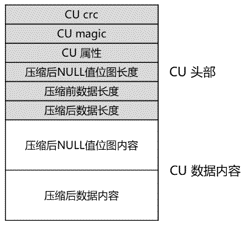
CU结构
列存索引
这里介绍两个索引,C-Btree和Psort,这里不做过多介绍。
主要涉及的是IO相关的内容。
C-Btree
- 索引结构和行存无差别,同样以行存形式存储
- C-Btree可以提升点查效率
- 存储key->ctid(cu_id, offset)
- 过程:
- 根据B-tree索引找到ctid集合
- 对集合进行批量排序(减少IO开销)
- 在CUDesc找到对应的cu_id,根据offset找到数据
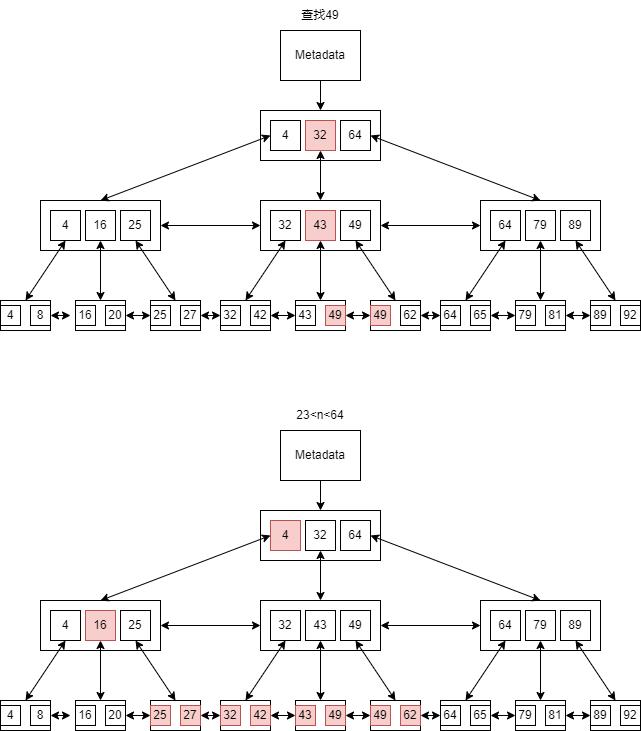
- 举例,等值查询 n=49, 范围查询 23<n<64。
PSort
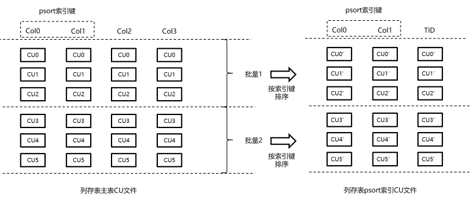
PSort是一个聚簇索引,对索引进行排序,然后将排序后的索引和行号存入一个新的表,用单独的列存表存储。
简单示意如下,图片来源:https://www.modb.pro/db/108155
IO管理框架:读取
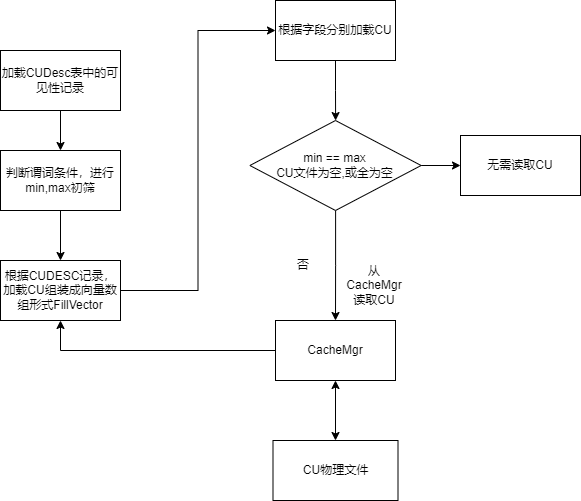
- 读取过程:
- 根据where条件,做MIN/MAX过滤的谓词条件
- 加载CUDesc
- MIN/MAX过滤
- 读取CU到CU Cache中
- 解析并填充
- CacheMgr: 用来缓存CU到内存中,可以提高重复查询的性能。
- CU的物理文件:
1. CStore_1.0: 当前基本不怎么实用
2. CStore_2.0: 重整了CU的文件结构,避免列数过多导致文件结构复杂。
IO管理框架:写入
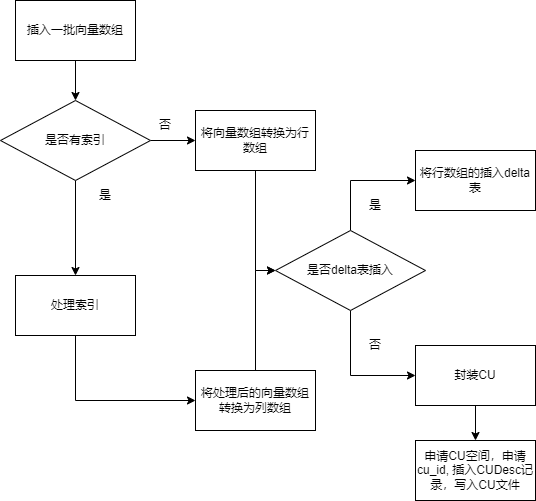
列存的插入要分两种情况,少量的插入和大量的插入,列存主要是对大批量数据设计的,因此为了弥补小量插入的打包CU性能开销,设计了一个delta行存表,用来记录插入结果,可以减少膨胀和提升性能,最后定期的整理。
- 写入框架如下
列存的删除比较简单,如果是delta表,先从delta表中删除满足谓词条件的记录,然后在CUDesc表中更新待删除CU的delete_bitmap。