摘要:现如今, 跨源计算的场景越来越多, 数据计算不再单纯局限于单方,而可能来自不同的数据合作方进行联合计算。
本文分享自华为云社区《如何高可靠、高性能地优化join计算过程?4个优化让你掌握其中的精髓》,作者: breakDraw 。
现如今, 跨源计算的场景越来越多, 数据计算不再单纯局限于单方,而可能来自不同的数据合作方进行联合计算。
联合计算时,最关键的就是标识对齐,即需要将两方的角色将同一个标识(例如身份证、注册号等)用join操作关联起来, 提取出两边的交集部分, 后面再进行计算,得到需要的结果。
而这种join过程看似简单,其实有非常多的门道,这里让我从最简单的join方法开始, 一步步演示join的优化过程。
首先假设以下场景:
- 有tb1, tb2两张表的数据,存放在不同位置
- 各有相同的id列。
- tb1有1亿行数据,而tb2表只有10w行数据。
1.简单全集2次循环碰撞
拿到2张表的全量数据, 直接2个for循环进行遍历
如果id匹配,则合并2个行记录作为join结果
for (row r1 : tb1) { for(row r2 : tb2) { if(idMatch(r1, r2) { // 获取r1和r2拼接后的r3 r3 = join(r1,r2) result.add(r3) } } }
图示如下:
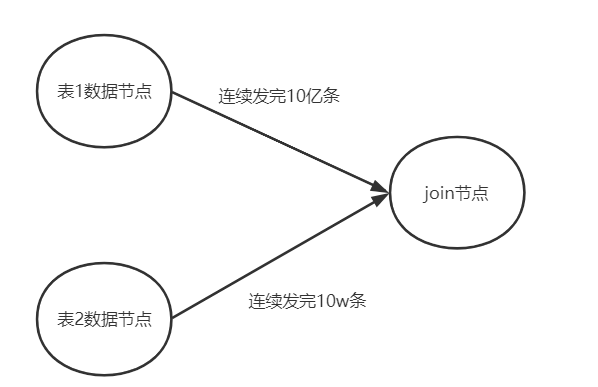
上面这种join有2个问题:
- 性能很差,两次for循环相当于O(mn)的复杂度
- 为了收集全量数据, 可能导致内存溢出,例如大表有10亿行数据,无法一次性存放。
2. 使用哈希表优化性能
首先解决刚才提到的第一个问题
实际上join过程就很像一种命中过程, 因此可以联想到哈希表。
- 我们使用一个 hashMap存储较小的tb2表(只有10w行)。
使用id列当作哈希表的key。 - 只对大表做for循环,如果id列在哈希表中能匹配中,则取出对用数据做拼接
for (row r1 : tb1) { if(idMap.containKey(r1.getId())) { row r2 = idMap.get(r1.getId()); r3 = join(r1,r2) result.add(r3) } }
这样复杂度就优化到了O(m)了
3. 大表数据分批传输
还有一个问题没解决: ”为了收集全量数据, 可能导致内存溢出“。
那我们可以将大表按照特定数量进行拆分,分成多批数据
例如每次以1000条的数量,和小表进行上面的哈希表碰撞过程。这样空间复杂度就是O (K + n)。
当每碰撞完一次,才接着接收下一批数据。如下面所示
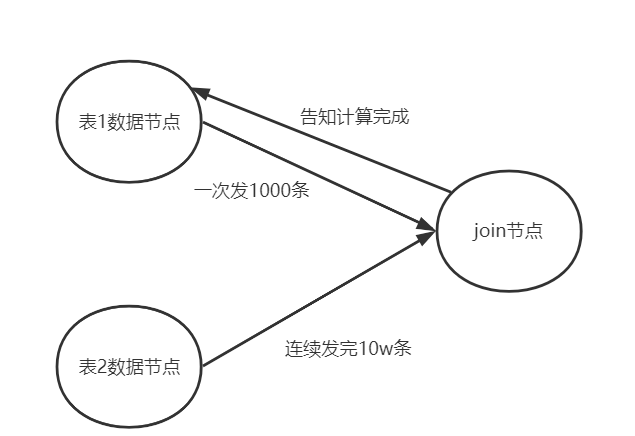
注意, ”告知计算完成这种响应机制“也可以优化成阻塞的缓冲队列。
但是还有个问题, 如果小表本身也很大, 例如1亿条, 计算节点连小表的哈希表都存不下,怎么办?
另外单节点计算的CPU有限,如何能在短时间内快速提升性能?
4. 分布式计算
当计算节点存不下小表构成的哈希表时, 这时候可以扩容2个join计算节点, 引入分布式计算来分担内存压力。
例如我们可以对id列进行shuffle分片
- id%3==0 分到计算节点A
- id%3==1 分到计算节点B
- id%3 ==2 分到计算阶段C
如果id是均匀的, 则小表的数据就被拆成了3份,也许就能正好存下了。
大表数据按同样的方式分片, 分到相同的节点, 对计算结果是没有影响的, 只要你的分片算法确保id匹配的行一定在同一个节点即可。
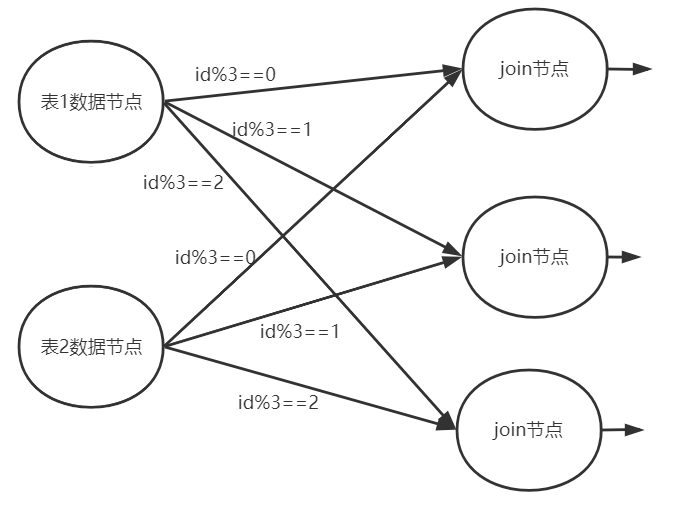
另外性能上, 分布式计算理论上按照节点数量也能够提升N倍的join速度。
这种分布式计算的方式已经能解决大部分join作业了,但是还有个问题:
- 假设网络带宽压力比较大(比如买的带宽比较便宜,发送数据的成本比较大)
- 部分涉及安全的计算场景中可能需要对数据做加密
这2种情况都会造成数据在输出时会耗费很多时间,甚至超过join的过程。那么该如何优化?
5. 本地join计算
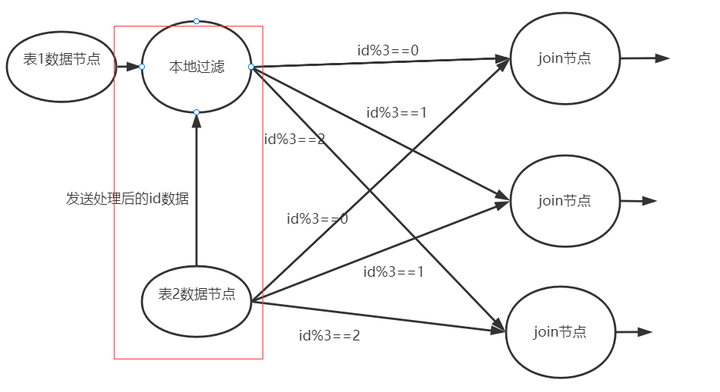
本地计算,指的就是在通过网络输出数据前,先提前做一些预处理。这种操作在各种计算引擎中都有体现
- 在spark中有一个叫boardCast广播数据的机制
- presto中有一种叫runtimeFilter的方式。
对于join过程, 我们可以:
- 将小表的id进行一定的压缩处理(例如哈希之后取前x位)
这样可以减少传输的数据量。 - 然后将这块数据传输给大表所在的节点, 进行提前的简单join筛选, 这样就可以提前过滤掉很多的没必要通过网络输出的数据。
以上仅仅只是最基础的join优化过程, 而在海量数据、高性能、高安全、跨网络的复杂场景中, 关于join计算还会有更多的挑战。
因此可以关注华为可信智能计算TICS服务,专注高性能高安全的联邦计算和联邦学习,推动跨机构数据的可信融合和协同,安全释放数据价值。