摘要:本文简要介绍知识图谱的存储与检索相关的知识。
本文分享自华为云社区《知识图谱的存储与检索》,原文作者:JuTzungKuei 。
1、概述
背景:随着互联网的发展与普及,一个万物互联的世界正在成型。与此同时,数据呈现出爆炸式的指数级增长,我们正处于一个数字洪流汹涌澎湃的新时代。

我们每天产生多少数据?据统计每天:
- 发送5亿条推文博客;
- 发送2940亿封邮件;
- 全世界每天有50亿次在线搜索;
- 一辆联网汽车会产生4TB的数据;
- Facebook每天产生4PB的数据,其中包含3.5亿的照片以及1亿小时的视频。
知识越来越多,目前常见的知识图谱都是以三元组的数据形式构成。
- DBpedia 有近8千万条三元组;
- YAGO 有超过1.2亿三元组;
- Wikidata 有近4.1亿三元组;
- Freebase有超过30亿三元组;
- 中文百科有约1.4亿三元组。

所以,我们该如何高效地存储与检索大规模的图谱数据???
知识图谱是一个有向图结构,描述了现实世界中存在的实体、事件或者概念以及它们之间的关系。其中,有向图中的节点表示实体、事件或者概念,图中的边表示相邻节点之间的关系。
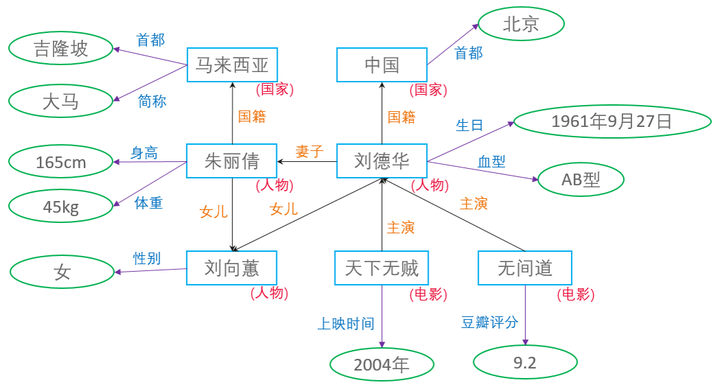
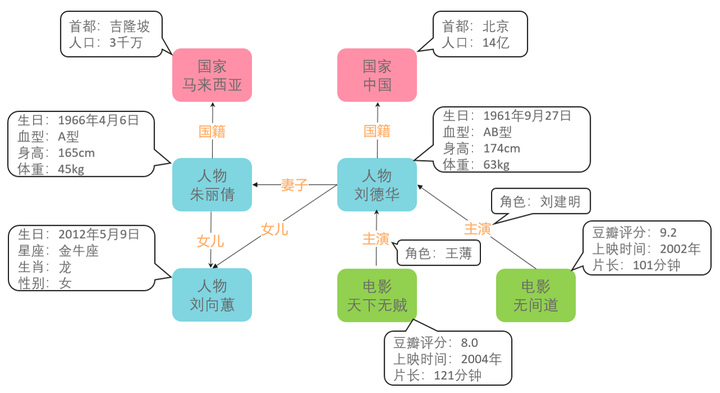
图中展示了关于刘德华的知识图谱局部示意图。图中红色字体表示概念,矩形框表示实体,蓝色字体表示属性,椭圆表示属性值,橙色字体表示关系。
- 概念:人物、国家、电影等
- 实体:刘德华、朱丽倩、中国、天下无贼等
- 属性:身高、体重、性别、首都、简称、上映时间、豆瓣评分等
- 关系:妻子、女儿、国籍、主演等
2、知识图谱的存储
知识图谱中的知识是通过RDF结构进行表示的,其基本构成单元是事实。
- 每个事实是一个三元组:<主语S, 谓语P, 宾语O>,其中:
- 主语S:可以是实体、事件、概念
- 谓语P:可以是关系、属性
- 宾语O:可以是实体、事件、概念、普通值
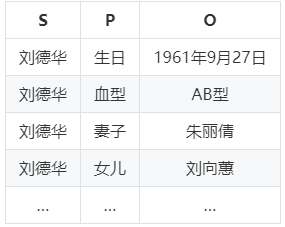
下面展示了知识图谱中知识表示的三元组列表。
<S, P, O>
<刘德华, 生日, 1961年9月27日>
<刘德华, 血型, AB型>
<刘德华, 妻子, 朱丽倩>
<刘德华, 女儿, 刘向蕙>
<刘德华, 国籍, 中国>
<中国, 首都, 北京>
。。。 。。。
为了对知识图谱数据进行高效查询和管理,需要在存储介质上合理地组织这些数据。按照存储方式的不同,标准知识存储方法可以分为基于表结构的存储和基于图结构的存储。
2.1、基于表结构的存储
基于表结构的存储利用二维的数据表对知识图谱中的数据进行存储。根据不同的设计原则,知识图谱可以具有不同的表结构,目前可以分为五类:三元组表、属性表、水平表、垂直表和全索引。
2.1.1 三元组表
知识图谱中的事实是一个个的三元组,一种简单直接地存储方式是设计一张表用于存储知识图谱中所有的事实,就是在关系数据库中建一张具有三列的表,该表的模式为:<主语,谓语,宾语>。将知识图谱中的每条三元组存储为三元组表中的一行记录。
这种存储方式简答直接,易于理解,但是将整个知识图谱都存储在一张表中,会导致单表的规模太大,在复杂查询,或者增删改查时会有非常大的开销。
方案代表:RDF数据库系统 3store、Virtuoso
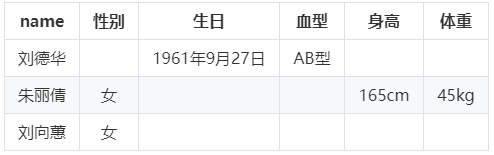
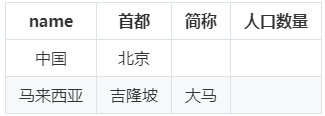
2.1.2 属性表
属性表,又称类型表,即为每种类型构建一张表,同一类型的实例放在相同的表中。表的每一列表示该类实体的一个属性,每一行存储该类实体的一个实例。
这种存储方式虽然客服了三元组表的不足,但是也造成了新的问题,大量数据字段重复,部分数据的属性值存在空值,均会造成冗余存储。
方案代表:RDF三元组库 Jena
人物
国家
电影
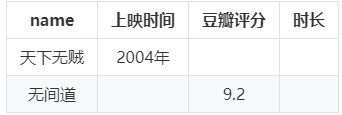
2.1.3 水平表
水平表每行记录存储一个知识图谱中一个主语的所有谓语和宾语。实际上,水平表相当于知识图谱的邻接表。水平表的列数是知识图谱中不同谓语的数量,行数是知识图谱中不同主语的数量。
真实知识图谱中,不同谓语数量可能成千上万个,会超出数据库上限;存在大量空值。
方案代表:早期的RDF数据库系统 DLDB
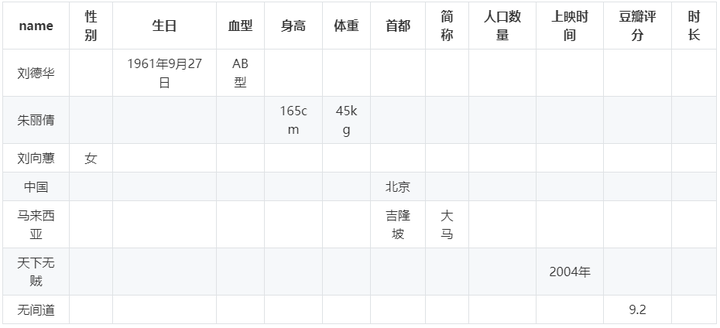
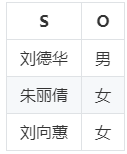
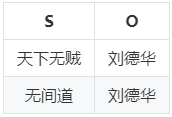
2.1.4 垂直表
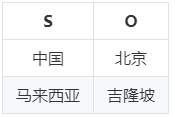
垂直表是一种以三元组的谓语作为划分维度的方法,将RDF知识图谱按照谓语划分为若干张只包含主语和宾语两列的表,表的总数量即知识图谱中不同谓语的数量,也就是说,为每种谓语建立一张表,表中存放知识图谱中由该谓语连接的主语和宾语值。
这种方法用不同表之间的连接代替自连接,避免了自连接操作。但是它无法很好地支持谓语是变量的查询操作。
方案代表:SW-Store
性别
主演
首都
2.1.5 全索引
全索引,又称六重索引,是针对知识图谱数据和运算的特点提出的一种优化技术,利用知识图谱三元组的特点来构建索引。将三元组中主语、谓语、宾语的各种排列情况都枚举出来,然后为它们一一构建索引。主语、谓语和宾语的排列情况共计六种。这些索引内容正好对应知识图谱运算中带变量的三元组模式的各种可能,是一种典型的“空间换时间”策略。
这种方法不仅缓解了三元组表的单表自连接问题,而且加速了图谱的查询效率。但是也增加了更新和维护成本。
方案代表:RDF-3X、Hexastore
六张表:SPO、SOP、PSO、POS、OSP、OPS
2.2、基于图结构的存储
基于图结构的存储是利用图的方式对知识图谱中的数据进行存储。将实体看作节点,关系看作带有标签的边,那么知识图谱的数据很自然地满足图模型的结构。基于图结构的存储方式能够直接准确地反映知识图谱的内部结构,目前主要有两种图存储模式:邻接表和邻接矩阵。对应的数据库是图数据库,数据模型是属性图。
2.2.1、邻接表
所谓的邻接表,就是知识图谱中的每个节点(实体)对应一个列表,列表中存储与该实体相关的信息。在利用图结构管理知识图谱数据的时候,一个关键问题是如何在基于图结构的指数候选空间中对查询操作有效剪枝。

2.2.2、邻接矩阵
所谓的邻接矩阵,就是在计算机中维护多个n x n维的矩阵,其中n为知识图谱中节点的数量。每个矩阵对应一个谓语,其中每一行或每一列都对应知识图谱中的一个节点。若谓语p所对应的矩阵中第i行第j列为1,则表示知识图谱中第i个节点到第j个节点有一条谓语为p的边。
三维矩阵M:|S| x |P| x |O|,分别表示主谓宾的数量,如果 <s, p, o>存在于知识图谱中,则M[i][j][k]=1,否则设置为0。
2.2.3、图数据库
图数据库的理论基础是图论,通过节点、边和属性对数据进行表示和存储。具体来说,图数据库基于有向图,其中节点、边、属性是图数据库的核心概念。
- 节点:表示实体、事件等对象。
- 边:指图中连接节点的有向线条,用于表示不同节点之间的关系。
- 属性:描述节点或边的特性。
- 常见图数据库:Neo4J、JanusGraph、OrientDB等;
3、知识图谱的检索
知识图谱的知识实际上是通过数据库系统进行存储的,大部分数据库系统通过形式化的查询语言为用户提供访问数据的接口。
3.1 SQL
Structured Query Language 结构化查询语言,用于管理关系型数据库。
四种操作
- 增:insert into 表名(列1, 列2, ...) values(值1, 值2, ...)
- 删:delete from 表名 where 条件
- 改:update 表名 set 列1=值1 where 条件
- 查:select 列1, 列2, ... from 表名 where 条件
3.2 SPARQL
SPARQL是由W3C为RDF数据开发的一种查询语言和数据获取协议,是被图数据库广泛支持的查询语言。
三种操作:
- 增:insert data 三元组数据
- 删:delete data 三元组数据
- 改:无,增删结合
- 查:select 变量1, 变量2, ... where 图模式
select ?x, ?y where { 天下无贼 主演 ?x . 无间道 主演 ?x . ?x 生日 ?y . }
3.3 Gremlim
Gremlin是Apache Tinkerpop框架中使用的图遍历语言,使用Gremlin可以很方便的对图数据进行查询,进行图的修改、局部遍历和属性过滤等。
三种操作
- 增:g.addV('人物').property(id,'007').property('生日','1962年6月22日')、g.addE('丈夫').property('xxx', 'yyy').from(g.V('001')).to(g.V('002'))
- 删:g.V('007').drop()
- 查:g.V().hasLabel('人物')、g.E().label()、g.V().valueMap()
3.4 Cypher
Cypher是一个描述性的图形查询语言,允许不必编写图形结构的遍历代码对图形存储有表现力和效率的查询。是一种被广泛使用的声明式图数据库查询语言。
四种操作
- 增:create(n:人物 {name: '周星驰', 生日: '1962年6月22日'}) return n;
- 删:match(s:Student{id: 1}) detach delete s;
- 改:match(n) where id(n)=7 set n.name = 'neo' return n;
- 查:match(n{name:"刘德华"}) return n、match(a:人物 {name:"刘德华"})-[b:Relation {{name:"国籍"}]->(c) return c;
参考
- 赵军:《知识图谱》
- 肖仰华:《知识图谱 概念与技术》
- 王昊奋:《知识图谱 方法、实践与应用》
- [知识图谱 综述,构建,存储与应用] (https://segmentfault.com/a/1190000023366451)
- [知识图谱学习笔记(九)——知识图谱的存储与检索] (https://www.jianshu.com/p/4484981a01df)
- [知识图谱04:知识图谱的存储与检索] (https://blog.csdn.net/u013230189/article/details/108959770)
- [知识图谱的存储于检索] (https://zhuanlan.zhihu.com/p/54916712)
- [Gremlin查询] (https://support.huaweicloud.com/usermanual-ges/ges_01_0024.html)
- [深入学习图语言Gremlin | 图数据库入门] (https://zhuanlan.zhihu.com/p/115098569)
- [Neo4j Cypher查询语言详解] (http://www.ttlsa.com/nosql/how-to-neo4j-cypher-query-language/)
- [Neo4j系列- Cypher入门(四)] (https://www.jianshu.com/p/53e2a67e9f40)
- [neo4j数据库之节点与关系的增删改查] (https://blog.csdn.net/weixin_38927376/article/details/104806662)
- [知识图谱(四):Neo4j查询语法] (https://blog.csdn.net/ai_1046067944/article/details/85342567)