摘要:随着数据仓库业务的发展,GDS使用场景日益增多,这就要求GDS仍要不断迭代,充分深入挖掘用户需求,提高产品化程度。
1. GDS定位
GDS是GaussDB(DWS)提供的一个数据导入导出工具,可在支持多种场景下的数据迁移业务,如异型数据库之间、两个集群之间等。GDS性能较高,单核处理能力上限约400MB/s,相比COPY、COPY工具性能更优、运行更稳定、容错性更强。
2. GDS根基
GDS基于FDW,全称是Foreign Data Wrapper(外部数据包装器)。这个功能是PostgreSQL 9.1首次引入的,实现了部分SQL/MED的特性。
2.1 什么是FDW
顾名思义,这个功能与数据库外部的数据有关系,对于外数据的具体描述是通过外部表来定义的。以GDS外部表创建语句为例说明外部表的结构:
CREATE FOREIGN TABLE [ IF NOT EXISTS ] table_name ( [ { column_name type_name POSITION(offset,length) | LIKE source_table } [, ...] ] ) SERVER gsmpp_server OPTIONS ( { option_name ' value ' } [, ...] ) [ { WRITE ONLY | READ ONLY }] [ WITH error_table_name | LOG INTO error_table_name] [REMOTE LOG 'name'] [PER NODE REJECT LIMIT 'value'] [ TO { GROUP groupname | NODE ( nodename [, ... ] ) } ];
可以看出,外部表可以分为三部分:字段定义、server定义、options定义。其中:
(1)字段属性定义与本地表定义方式类似,甚至可以使用like L_TBL等语法进行定义;
(2)server定义,需要使用CREATE SERVER xxx_server创建;
(3)options选项,由与该外表相关的FDW实现决定。
在GDS使用过程中,安装自定义FDW、创建server等配置都是在initdb阶段执行,无须用户额外设置。Postgres现在有很多FDW扩展,其中postgres_fdw、file_fdw是由官方全球开发组维护,postgres_fdw可用于访问远程PostgreSQL服务器。
下图展示了FDW的执行过程[1]。
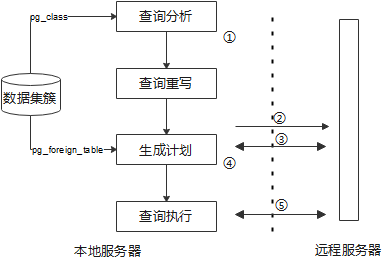
① 查询分析模块为输入的SQL创建一棵查询树;
② 计划器(或执行器)连接到远程服务器;
③ 执行EXPLAIN命令以估算计划路径的代价;
④ 计划器按照计划树创建出纯文本SQL语句;
⑤ 执行器将纯文本SQL语句发送到远程服务器并接收结果。
2.2 GDS自定义FDW
根据导入导出场景,GaussDB(DWS)实现了自定义的FDW扩展——dist_fdw。dist_fdw运行于GaussDB内核之中,在initdb时进行安装,所以一般情况下对用户是透明的。
3. 多角度缔造高性能
3.1 多线程工作模式
GDS使用多线程模式,由主线程负责接收请求,然后分配给工作线程进行具体的业务处理,可以并发处理导入导出业务。主线程与工作线程通过UnixSocket进行通信,通信内容包括:分派新任务、停止工作线程、工作线程状态上报等。
每个线程可承载多个导入导出业务,通过与事件消息驱动机制相结合,实现高速网络通信,确保业务执行高性能、高并发。
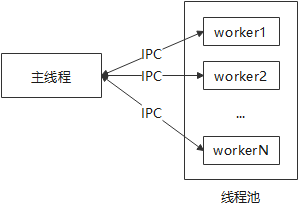
3.2 事件消息驱动机制
GDS采用事件驱动模型,选择当前系统可支持的最高效的多路复用机制(epoll、poll、select等)。
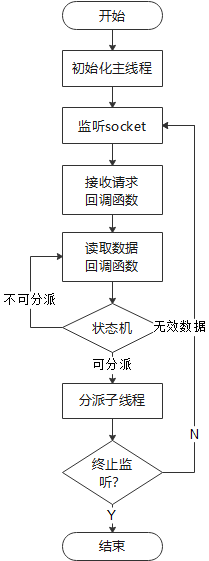
3.3 大文件导入优化
对于超大文件的导入,如果仍然与普通文件一样,继续采用串行方式导入,必然会成为业务瓶颈,导致数据迁移、备份等过程的无限延长,无法充分发挥多核机器、GDS多线程架构的优势。针对该场景,GDS引入分片导入机制,实现并行导入,充分发挥软硬件性能,减少业务阻塞,减少数据迁移耗时。
该功能针对本地文件的导入场景,需通过外表file_sequence参数进行相应设置。
该参数格式为file_sequence '文件被拆分的总数-当前分片' 。例如:
file_sequence '3-1' 表示导入的文件在逻辑上被拆分成3份,当前外表导入的数据为第一个分片上的数据。
file_sequence '3-2' 表示导入的文件在逻辑上被拆分成3份,当前外表导入的数据为第二个分片上的数据。
file_sequence '3-3' 表示导入的文件在逻辑上被拆分成3份,当前外表导入的数据为第三个分片上的数据。
这里给出一个使用示例:
-- step1. 创建目标表
CREATE TABLE gds_widetb_1 (city integer, tel_num varchar(16), card_code varchar(15), phone_code vcreate table pipegds_widetb_3 (city integer, tel_num varchar(16), card_code varchar(15), phone_code varchar(16), region_code varchar(6), station_id varchar(10), tmsi varchar(20), rec_date integer(6), rec_time integer(6), rec_type numeric(2), switch_id varchar(15), attach_city varchar(6), opc varchar(20), dpc varchar(20));
--step2. 创建带有file_sequence字段的外表。
CREATE FOREIGN TABLE gds_csv_r_1( like gds_widetb_1) SERVER gsmpp_server OPTIONS (LOCATION 'gsfs://127.0.0.1:8781/wide_tb.txt', FORMAT 'text', DELIMITER E'|+|', NULL '', file_sequence '3-1'); CREATE FOREIGN TABLE gds_csv_r_2( like gds_widetb_1) SERVER gsmpp_server OPTIONS (LOCATION 'gsfs://127.0.0.1:8781/wide_tb.txt', FORMAT 'text', DELIMITER E'|+|', NULL '', file_sequence '3-2'); CREATE FOREIGN TABLE gds_csv_r_3( like gds_widetb_1) SERVER gsmpp_server OPTIONS (LOCATION 'gsfs://127.0.0.1:8781/wide_tb.txt', FORMAT 'text', DELIMITER E'|+|', NULL '', file_sequence '3-3');
--step3. 将wide_tb.txt并发导入到gds_widetb_1。
parallel on INSERT INTO gds_widetb_1 SELECT * FROM gds_csv_r_1; INSERT INTO gds_widetb_1 SELECT * FROM gds_csv_r_2; INSERT INTO gds_widetb_1 SELECT * FROM gds_csv_r_3; parallel off
3.4 SMP特性支持导入场景
SMP特性通过算子并行来提升性能,本质上是一种利用富余资源来换取时间的方案,计划并行之后会占用更多的系统资源,包括CPU、内存、网络、I/O等等。在合适的场景以及资源充足的情况下,能够起到较好的性能提升效果。SMP支持自适应特性,该特性会根据当前资源和查询特征,动态选取最优的并行度。SMP特性支持支持GDS导入的外表扫描并行,当集群资源充足时,可以发挥各节点性能,加速导入执行效率。
4. 全方位丰富功能
4.1 容错机制
提供了强大的容错机制,包括错误默认处理、错误表、错误日志等多种方式,减少数据导入导出异常中止的情况,方便用户事后查询分析。
4.2 编码解析
支持多种类型的字符编码,包括UTF-8、GBK、ASCII、LATIN1等。
4.3 多字符字段/换行分割符
对于外表属性,分隔符delimiter、行分隔符eol,既兼容原有的逗号、 等默认方式,还支持用户自定义多字符分隔符,最多可支持10个字节。在场景复杂、噪声较多、数据量很大的场景下,单字符分隔符很容易与数据本身冲突,而使用多字符分隔符,可以减少这种冲突,且可以轻容兼容异构数据库,方便用户进行数据处理。
4.4 数据不落地
此前GDS只支持本地文件的导入导出,因此无论是数据加工清洗或者是远端数据的导入导出都需要在GDS本地生成一份中间数据,这对用户来说不仅消耗磁盘空间并且很不方便。据此,开发人员对不落地导入导出特性进行了规划和实现,提供了另外一种导入导出方式,不仅节省了用户的磁盘空间而且让GDS的使用变得更加灵活多变。具体使用方式参见用户手册。
5. 展望
随着数据仓库业务的发展,GDS使用场景日益增多,这就要求GDS仍要不断迭代,充分深入挖掘用户需求,提高产品化程度。继往开来,GDS一批新特性已展开规划,如自动化工具、过程监控工具、云化等等。未来可期,作为GaussDB(DWS)的强有力数据迁移工具,GDS会继续强化,丰富产品生态。
【参考文献】
[1] [日]铃木启修.PostgreSQL指南——内幕探索[M].电子工业出版社:北京,2019:85-86.
本文分享自华为云社区《GaussDB(DWS)数据利器GDS探析》,原文作者:常常要奋斗。