摘要:MindSpore是华为公司推出的新一代深度学习框架,是源于全产业的最佳实践,最佳匹配昇腾处理器算力,支持终端、边缘、云全场景灵活部署,开创全新的AI编程范式,降低AI开发门槛。
MindSpore是华为公司推出的新一代深度学习框架,是源于全产业的最佳实践,最佳匹配昇腾处理器算力,支持终端、边缘、云全场景灵活部署,开创全新的AI编程范式,降低AI开发门槛。2018年华为全联接大会上提出了人工智能面临的十大挑战,其中提到训练时间少则数日多则数月,算力稀缺昂贵且消耗大,仍然面临没有“人工”就没有“智能”等问题。这是一项需要高级技能的、专家的工作,高技术门槛、高开发成本、长部署周期等问题阻碍了全产业AI开发者生态的发展。为了助力开发者与产业更加从容地应对这一系统级挑战,新一代AI框架MindSpore具有编程简单、端云协同、调试轻松、性能卓越、开源开放等特点,降低了AI开发门槛。
编程简单MindSpore函数式可微分编程架构可以让用户聚焦模型算法数学原生表达。资深的深度学习开发者都体会过手动求解的过程,不仅求导过程复杂,结果还很容易出错。所以现有深度学习框架,都有自动微分的特性,帮助开发者利用自动微分技术实现自动求导,解决这个复杂、关键的过程。深度学习框架的自动微分技术根据实现原理的不同,分为以Google的TensorFlow为代表的图方法,以Facebook的PyTorch为代表的运算符重载,以及以MindSpore为代表的源码转换方法(Source to Source,S2S自动微分技术),如图1.1所示。
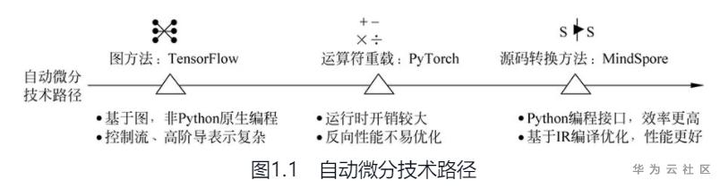
图方法实现简单,并且图的数据结构容易进行优化和并行。不过图方法的可编程性一直饱受争议,用户需要理解图的概念和接口,例如数据节点、通信节点、计算节点、数据边、依赖边、引用边等,存在一定的学习成本。并且,在图方法中控制流、高阶导的表示较为复杂。运算符重载方式比较符合用户尤其是研究人员的编程习惯,很受学术界欢迎。不过这种方式需要使用宿主语言(Host Language)的解释器,并且使用Tape模式去记录运行过程,所以开销比较大,同时这种动态方式也不利于反向性能优化。
S2S自动微分技术,兼顾了可编程性和性能。一方面能够和编程语言保持一致的编程体验;另一方面它是中间表示(Intermediate Representation,IR)粒度的可微分技术,可复用现代编译器的优化能力,性能也更好。S2S自动微分技术使用了高效易调试的可微编程架构。首先在接口层提供Python编程接口,包括控制流表达,利于用户快速入门,如代码1.1所示。第一步用Python代码定义一个计算图(函数)。第二步,利用MindSpore提供的反向接口进行自动微分,这一步的结果是一个反向的计算图(函数)。第三步给定一些输入,就能获取第一步中的计算图(函数)在给定处的导数。在这个例子中,自动微分的结果是图中所有输入的导数。MindSpore的反向接口同样提供选项计算某一个或者一部分输入的导数。
代码1.1 原生Python编程体验

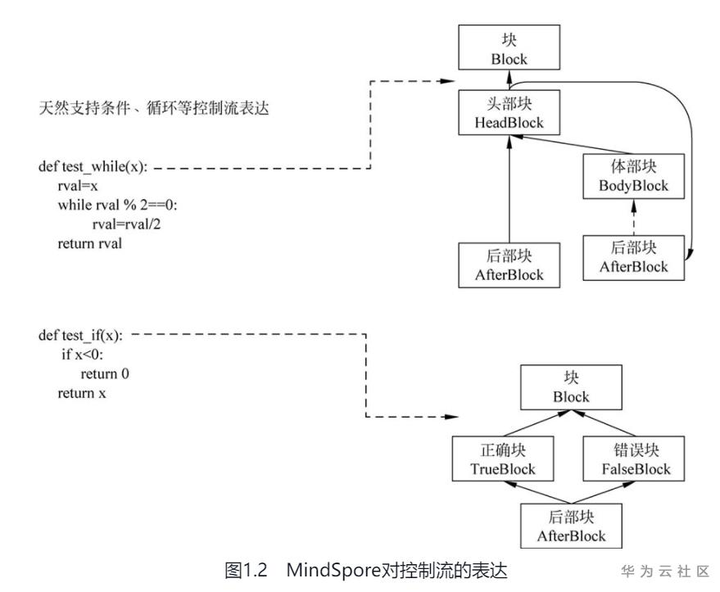
其次,IR(Intermediate Representation,中间表示)粒度的可微分技术能够把用户定义的网络源代码通过解析验证等过程转换为MindSpore定义的IR,也就是MindSpore IR,在IR的基础上应用IR更变器方法(IR Mutator Method),最终生成反向代码。在此过程中,也应用了算子融合等技术进一步提升反向性能。如图1.2所示,MindSpore对控制流的表达包括循环和条件。可以看到代码编程风格与原生Python保持一致,更重要的是,与Python对控制流的表达不同的是,MindSpore在生成控制流的反向时不会对循环进行展开,而通过在IR基础上进行反向计算,避免了表达式膨胀,从而提升性能。
相比其他框架,用MindSpore可以降低核心代码量20%,降低开发门槛,效率整体提升50%以上。同时,能天然支持编译优化,进一步提升代码运行效率,有效降低科研工程门槛。MindSpore自动微分代码如代码1.2所示。

除了图层面的自动微分以外,MindSpore同时支持算子层面的自动微分。在提供了深度学习主要网络的算子的同时,MindSpore自带的张量引擎(Tensor Engine)支持用户使用Python DSL(Domain Specific Language)自定义算子,并且提供算子级的自动微分接口。通过使用Python DSL,用户可以在Python中像写数学式一样自定义算子,如同数学中用公式定义函数一样,而张量引擎的算子自动微分接口可以直接对DSL定义的算子进行微分,正如数学中使用统一的微分符号表示求导一样,这样让代码的书写更加简洁直观,贴近用户的书写习惯,
如代码1.3所示。这里的前向算子是用户用DSL自定义的算子,也是算子级自动微分的求解目标。接下来利用张量引擎提供的反向接口去推导出反向算子。对于多输入的算子,反向算子接口可以指定一个或者多个前向算子的输入,然后对这些输入同时进行自动微分计算。另外与图层面的自动微分不同,算子级的自动微分额外接收反向图中上一层算子(对应在正向图的下一层算子)的微分结果作为输入,然后使用链式法则计算出该层反向算子的结果。数学中高阶导数是通过对函数反复使用微分算子计算得到的,同样,在MindSpore中,用户可以对算子反复使用反向接口来计算算子的高阶导数。
代码1.3 MindSpore算子级自动微分代码示例

算子级的自动微分同样使用了IR方法,因此许多IR层面的优化技术可以应用在算子级的自动微分中。其中MindSpore的张量引擎根据深度学习的算子特征特别增加了IR层面的除零优化。未经优化的反向算子中可能存在大量的零元素,极大地影响求和等计算的效率。张量引擎的自动微分通过循环轴合并、循环域调度变换消除反向算子中的零元素,不仅能提高代码的运行效率,也使得代码简化让后续部署更加方便。此外MindSpore的张量引擎引入多项式(Polyhedral)模型,解决循环变形依赖问题,实现自动的算子调度,并且自动内存优化,实现内存最优排布、算子最佳性能。如此让用户从手写调度调优的细节中解放出来,更专注于算法本身。
MindSpore的算子级自动微分接口不仅可以自动生成反向算子,更提供了进一步手动优化导数公式的可能。MindSpore的算子级自动微分功能把算子分割成若干步简单函数的复合运算后,先是利用已知基础函数的导数和求导法则分布求导,然后利用链式法则计算复合函数的导数,最后通过张量引擎内置的数学公式简化器进行化简。这可以满足绝大部分用户对自动微分的需要。
但是对部分有更高性能或者代码部署要求的用户,MindSpore提供接口让用户可以用自己优化过的导数公式代替某一步或者若干步自动生成的微分,如代码1.4所示。虽然上面的例子中MindSpore业已完成Sigmoid函数的求导,但部分用户可能希望用手动推导的Sigmoid函数的导数dy=y(1-y)进行计算,这样可以利用前向函数计算的结果。这里把手动推导的导数公式放入函数custom_sigmoid_fdiff中,并在自动微分中重载这部分的求导。那么自动微分在保持其他部分自动生成的情况下,使用custom_sigmoid_fdiff作为输出对于x的导数进行运算。这样MindSpore保持了自动微分和手动调优的反向算子在风格上的统一,方便了图层对算子的调用。
代码1.4 MindSpore手动调优自动微分代码示例

总而言之,MindSpore在支持算子级自动微分的同时,对反向算子进行IR层面的优化,满足算子开发者自动生成反向算子的需求。同时MindSpore兼顾了用户对手动调优反向的需求,将自动和手动有机结合,简化了开发流程,提升了代码的可读性,增加了代码的运行效率。
端云协同MindSpore依托华为“端—边—云”的业务场景,在隐私保护日渐重要的情况下,致力于支持全场景部署,并打通云到端全流程。MindSpore针对全场景提供一致的开发和部署能力,以及按需协同能力,让开发者能够实现AI应用在云、边缘和手机上快速部署,全场景互联互通,实现更好的资源利用和隐私保护,创造更加丰富的AI应用。
学术界和工业界没有对端云协同做系统的概念定义,一般认为涉及云和端交互的学习形态,即是端云协同系统。模型压缩、端侧推理、端侧训练、迁移学习、联邦学习等技术在端侧的应用都可以划分到端云协同的范畴。这些涉及在云侧构建、预训练或托管模型,在端侧执行或训练模型,以及云和端之间模型或权重的传输。在端侧推理场景中,对云侧模型进行模型压缩并转换为端侧推理模型,使用端侧推理框架加载模型并对本地数据进行推理。但云侧预训练模型使用的数据集和端侧真实的数据存在差异,为了利用端侧真实数据训练模型,带来精准的个性化体验,端侧训练成为必然。
由于端侧设备在算力、电量和数据量方面的限制,从头训练一个模型不切实际,因此迁移学习技术被用在了端侧学习中,可以大幅度降低端侧训练的难度。为了充分利用端侧数据和端侧训练能力,一些端云联合学习方法和框架被提出来,旨在联合多个端侧设备共同训练一个全局模型,并实现端侧隐私保护。Google率先于2016年提出了联邦学习方法和框架。杨强等又提出了横向联邦学习、纵向联邦学习、联邦迁移学习以及联邦强化学习等方法及对应的框架。端侧推理、迁移学习和联邦学习属于端云协同的不同阶段,如图1.3所示的MindSpore端云协同框架融合了这三种形态并打通了云到端全流程。
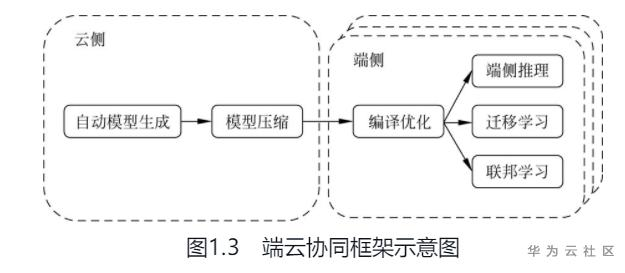
MindSpore端云协同框架整合了MindSpore云侧框架、MindSpore端侧框架,并打通了模型生成、模型压缩、编译优化和端侧学习的全流程。MindSpore提供神经架构搜索(Neural Architecture Search,NAS)能力用于自动化生成模型,构建模型库。MindSpore模型压缩模块用于对模型库中的模型进行剪枝和量化。MindSpore提供了编译优化能力用于转换和优化模型,并通过神经处理单元(Neural-network Processing Unit,NPU)、图形处理单元(GraphicsProcessing Unit,GPU)或ARM NEON(1)等加速算子执行。MindSpore端云协同框架具有如下多种特性(2)。
(1)快速多处部署。实际场景中,模型需要快速适配不同机型硬件。通过神经架构搜索技术构建多元化的模型库,适配多种机型。针对特定应用场景,从模型库中搜索满足性能约束的模型,拿来即用,无须重复训练。(2)全栈性能优化。结合神经架构搜索、模型压缩(剪枝、蒸馏、量化)、编译优化(算子融合、常量折叠、硬件加速)等手段优化模型精度、大小、时延,追求极致性能。(3)灵活易用。支持多种策略,如模型生成、模型压缩和编译优化组合使用。打通云到端全流程,集中管理全流程策略和配置,方便使用。(4)多种学习形态。MindSpore端云框架逐步支持多种学习形态,比如支持当前业界常用的端侧推理形态,并逐步支持迁移学习、联邦学习等需要端侧训练能力的高级学习形态,满足开发者各种各样的场景需求。
调试轻松MindSpore实现看得见的AI开发、更轻松的调试体验、动静结合的开发调试模式。开发者可以只开发一套代码,通过变更一行代码,从容切换动态图/静态图调试方式。需要高频调试时,选择动态图模式,通过单算子/子图执行,方便灵活地进行开发调试。需要高效运行时,可以切换为静态图模式,对整张图进行编译执行,通过高效的图编译优化,获得高性能。MindSpore切换调试模式代码如代码1.5所示。
代码1.5 MindSpore切换调试模式代码

性能卓越MindSpore通过AI Native执行新模式,最大化发挥了“端—边—云”全场景异构算力。它还协同华为昇腾芯片On Device执行、高效AI数据格式处理、深度图优化等多维度达到极致性能,帮助开发者缩短训练时间,提升推理性能。此外,数据集、模型越来越大,单机的内存和算力无法满足需求,需要模型并行;模型手动切分门槛高,开发效率低,调试困难。MindSpore可以通过灵活的策略定义和代价模型,自动完成模型切分与调优,获取最佳效率与最优性能。MindSpore自动并行代码如代码1.6所示。
代码1.6 MindSpore自动并行代码示例

开源开放MindSpore致力于AI开发生态的繁荣,开源开放可扩展架构,助力开发者灵活扩展第三方框架、第三方芯片支持能力,让开发者实现各种定制化需求。MindSpore将在门户网站、开源社区提供更多学习资源、支持与服务。

(1) 参考链接:https://developer.arm.com/architectures/instruction-sets/simd-isas/neon。
(2) MindSpore端云协同框架处于开发迭代中,其支持特性以官网公布的为准。