摘要:在数据仓库/分析领域,有传统厂商Oracle,Teradata,开源软件Hadoop,云厂商AWS Redshift,Google Bigquery,Snowflake成功的技术原因是什么?
1.引子
云数据仓库Snowflake 9月份IPO的新闻引起了业界的关注。2012年才成立的Snowflake,一上市就来个惊雷,IPO筹资38亿美元,创近12年来最大IPO金额。
在数据仓库/分析领域,有传统厂商Oracle,Teradata,开源软件Hadoop,云厂商AWS Redshift,Google Bigquery,Snowflake成功的技术原因是什么?
先从2016年Snowflake在SIGMOD上发表的论文入手。
2.The Snowflake Elastic Data Warehouse论文
注:文中部分图,论文中没有,我个人理解和补充的。
2.1.数据仓库架构比对
Share everything VS Share nothing
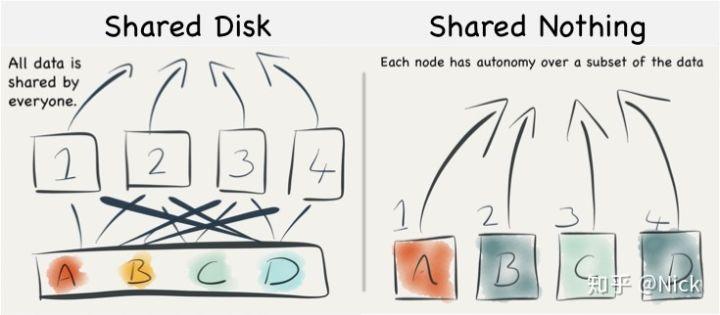
传统数仓架构
Share every everything的典型代表如Oracle 一体机

Share nothing的代表。例如Greenplum,ClickHouse,PGXC/XL
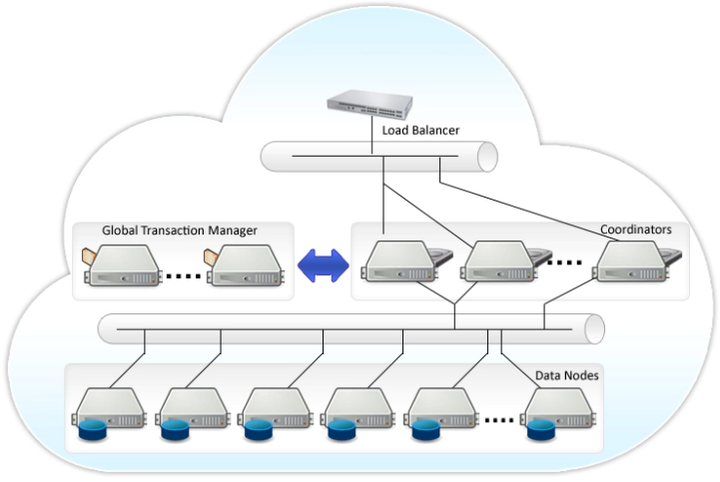
MPP架构(PGXL)
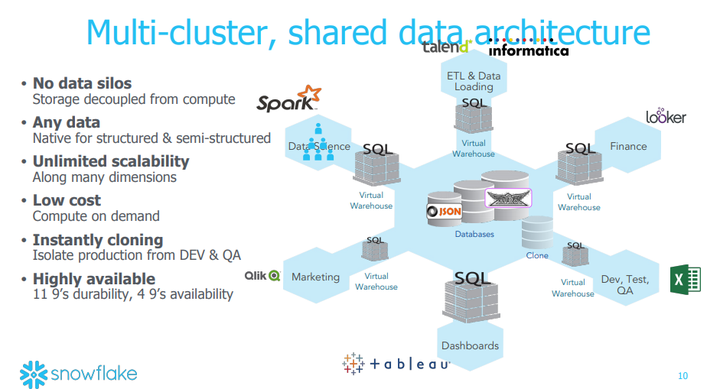
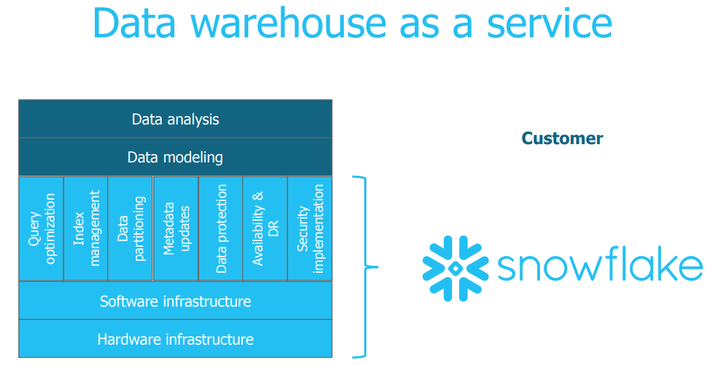
Snowflake的架构,强调多租和数据共享:
2.2.Snowflake的关键特征包括:
纯SaaS体验
支持关系型(ANSI)和事务
支持半结构化数据处理,例如JSON和Avro
弹性,存储和计算资源可独立扩展,不影响性能和并发查询
高可靠,支持节点,集群,甚至整个数据中心down掉都没有问题
持久性,支持数据clone,删除撤回和跨region备份
安全,端到端数据加密,SQL级别基于角色的访问控制
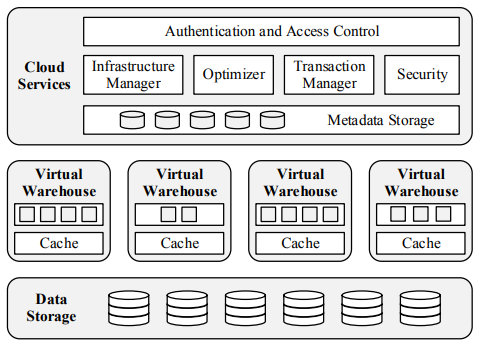
Multi-Cluster, Shared Data Architecture
Snowflake架构分为三层,存储,计算和服务
Data Storage
This layer uses Amazon S3 to store table data and query results.
注:2016年的论文发表时的存储支持情况,当前除了支持S3,还支持 Google Cloud Storage, Microsoft Azure blob storage。避免了云服务商的lock in。
这也是共有云服务客户关心的问题。
计算层
Virtual Warehouses
The “muscle” of the system. This layer handles query execution within elastic clusters of virtual machines, called virtual warehouses.
服务层
Cloud Services
The “brain” of the system. This layer is a collection of services that manage virtual warehouses,queries, transactions, and all the metadata that goes
around that: database schemas, access control information, encryption keys, usage statistics and so forth.
2.3存储层:
数据保存在S3上,和本地存储访问相比,时延比较高,S3支持PUT/GET/DELETE 简单的访问方式。S3还有个特点是,文件不能在文件尾追加,只能删除或覆盖。S3支持GET接口获取文件的部分数据。
这些特点对Snowflake的表文件格式设计和并发访问模式有重大影响。
表被水平分区成多个大的,不变的文件。文件等同于传统数据库系统的page或block。每个文件内,每个列被分组,并高度压缩。这种存储模式学名叫PAX或行列混合。每个表文件的文件头,包含元数据信息,包括每个列在文件中的偏移量。

Snowflake使用PAX存储格式
PAX存储格式,可以参考附件的参考论文。
2.4计算层:
计算层是通过虚拟集群来对外提供逻辑上独立的数仓,叫虚拟数仓。VW(虚拟数仓)是纯的计算资源,可以按需创建或销毁。创建或销毁不影响数据库状态。
注:MPP或Hadoop体系的存算一体比存算分离架构系统有低时延的访问优势。
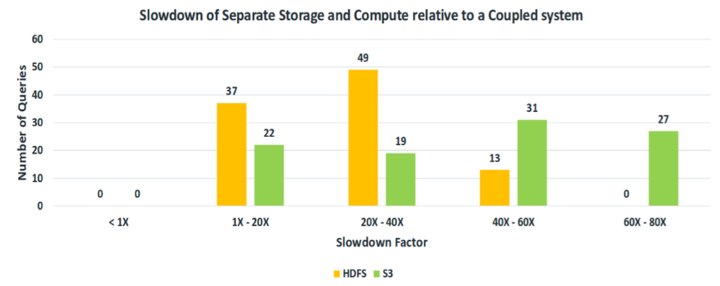
数据来源:见存算分离性能参考
没有计算存储访问本地文件系统的低时延的优点,Snowflake在计算层增加了一层cache来缓存文件和元数据,解决文件远程访问带来的时延问题。
2.4.1计算层的弹性和隔离:
VM(虚拟机)分给一个独立的用户。VM(虚拟机)组成虚拟数仓(VW)。组成虚拟数仓的一个个虚拟机叫WorkNode,WorkNode不跨VM共享。这样可以保证查询时的性能隔离(会带来资源利用率低的问题,后续版本会考虑共享)。
查询提交时,每个VW的worknode创建一个工作进程,工作进程的生命周期仅仅存活于查询时。
进程失败可以进行尝试。部分尝试后续版本会支持。
每个用户可能会有多个VW。每个VW可以访问共享的表,不需要物理的数据copy。
本地缓存和file stealing:
每个worknode在本地磁盘上维护了表数据的缓存。缓存是表文件的内容,也就是本节点过去访问S3对象。精确的讲,缓存包含文件头和每个列对应文件。缓存在worknode的生命周期,在当前和随后的work process间共享。缓存采用LRU算法进行管理。
为了提升缓存命中率,避免VW内的work node建的表文件冗余,查询优化器根据表文件名称,采用一致性哈希的算法把输入的文件?分配到work node。随后的或并发的查询,如果访问同一个表文件,将分配到同一个worknode。
补一致性hash的图
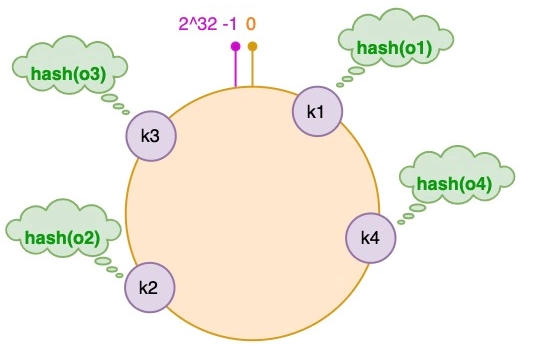
一致性hash示意
在Snowflake中,一致性哈希的实现采用懒实现的方式。当work node变化(例如节点失败或VM的规格调整),数据不会立刻被调度(shuffle)。实际上,Snowflake依赖LRU替换策略来最终替换缓存内容。
这种解决方案缓解了替换多个查询缓存内容的代价,带来了更好的可用性。share nothing应用系统是立刻替换。
这种懒实现的方式对系统实现也带来了简化,系统没有降级模式。
除了缓存,倾斜处理在云数仓中也特别重要。一些节点或许因为虚拟化或网络方面的原因导致比其他节点慢。Snowflake在扫描层进行解决切斜问题。当一个工作进程完成输入文件集的扫描,工作进程需要从其他工作进程请求额外的文件时,我们采用了一种 file stealing(Snowflake自己起的名字)的方式。
当一个工作进程发现在输入文件集中有多个剩余的文件时,收到file stealing的请求时,会转移文件的所有权到请求工作进程。请求者直接从S3上下载文件。这种设计保证file stealing不会对被请求的工作进程带来额外的负载。
2.4.2执行引擎:
列式存储。列式存储被认为比行存储在数据分析中要好。
列式存储可以更充分利用CPU缓存,SIMD指令集,更多的压缩调优的机会。
向量执行。
Snowflake采用向量化执行,与MapReduce相比,避免中间结果的物化。向量执行方式,数据按流水线方式执行,每批可以处理一个列的数千行记录。向量化执行(MonetDB/X100首先采用),可以节省IO,极大的改善缓存效率。
基于推的执行Push-based execution 是指关系算子把他们的结果推给下游的算子,而不是等这些下游算子来拉取数据(经典的火山模型采用拉取数据的方式)。基于推的执行提升缓存效率,因为节省了控制流逻辑。基于推的执行也让Snowflake可以高效地处理DAG形状的执行计划,可以对共享/流水线的中间结果进行优化。
与传统查询处理相比,Snowflake没有额外的负载要处理,例如查询时不需要进行事务管理。
对查询引擎来讲,查询时,文件集是不变的。
同样,也没有缓冲池。
2.5云服务层:
Metadata such as catalog objects, which table consists of which S3 files, statistics, locks, transaction logs, etc. is stored in a scalable, transactional key-value store, which is part of the Cloud Services layer
云服务层是多租的。云服务层的每个服务(访问控制,查询优化,事务管理..)是长期存在并在多个用户间共享。
考虑到高可用,每个服务都有副本。单个服务的失败不会影响数据的丢失或可用。但可以会导致正在运行的查询失败。
2.5.1查询管理和优化
Snowflake的查询优化器遵循经典的 Cascades style,with top-down cost-based optimization
所有的统计信息当数据加载或更新时自动进行维护。
Snowflake不使用索引。执行计划的搜索空间比其他系统要小很多。
执行计划空间通过延迟到执行时间来进一步降低。例如join时的数据分布。
这种设计减少了执行计划不准的情况。同时增加了健壮性。
一旦优化器完成,执行计划被分布到所有的work node。
当查询执行时,云服务持续跟踪查询状态,收集性能数据,检测节点失败。所有信息和统计信息被保存,用于审计和性能分析。
2.5.2并发控制
通过SI(Snapshot Isolation)快照隔离方式来实现ACID事务。
SI在MVCC基础上进行实现。
除了SI,Snowflake也通过快照进行时间旅行,高效的克隆数据库对象。
2.5.3修剪

Snowflake使用的修剪模式
传统的数据库数据访问采用基于B+Tree的索引来进行。传统索引方式依赖随机访问,这种方式对S3和列压缩不友好。同时维护索引会增加数据存储占用,增加数据加载时间。
最后,索引管理是复杂,昂贵,有风险的操作。
Snowflake支持修剪的技巧是在元文件中维护文件头,文件最大,最小,count,avg,sum等元数据信息。
除了静态修剪,Snowflake也支持执行时动态修剪。例如再hash join时,snowflake收集build-side records的参与join的key的分布式信息,然后推送给probe side,用于过滤或跳过probe side侧的文件。
2.6重点特性
2.6.1纯的SaaS体验。
支持JDBC,ODBC, Python PEP-0249接口。支持第三方服务,例如Tableau, Informatica, Looker
无任何调优参数:
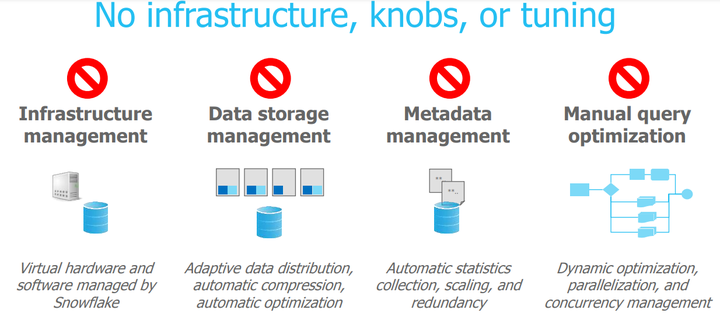
用户只有在采购时才选择一个数仓的大小T-SIZE模式。
2.6.2持续可用
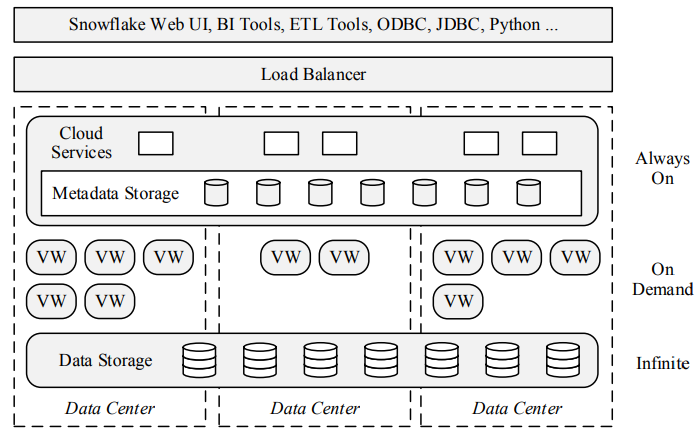
Multi-Data Center Instance of Snowflake
Snowflake tolerates individual and correlated node failures at all levels of the architecture。
2.6.3在线升级
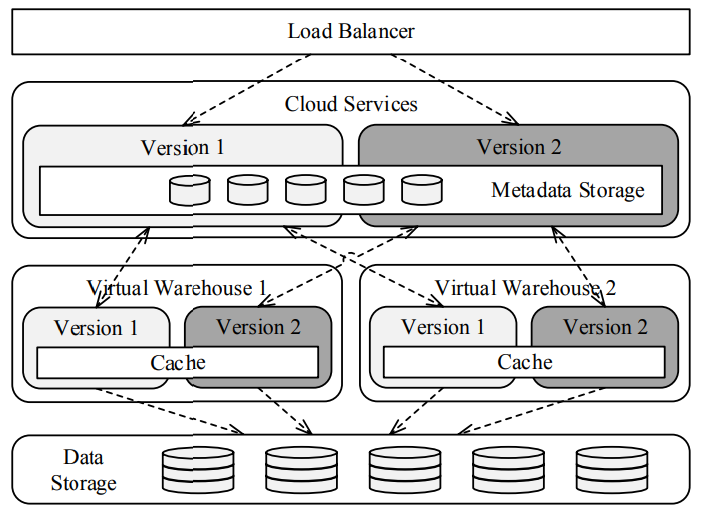
所有的服务时无状态的,都可以配置多版本。所有的有状态的数据被保存在基于key/value的存储中。状态数据通过映射层进行元数据版本和schema演进。任何时候更改元数据schema,保证后向兼容。
云服务的两个版本共享同样的元数据存储信息。
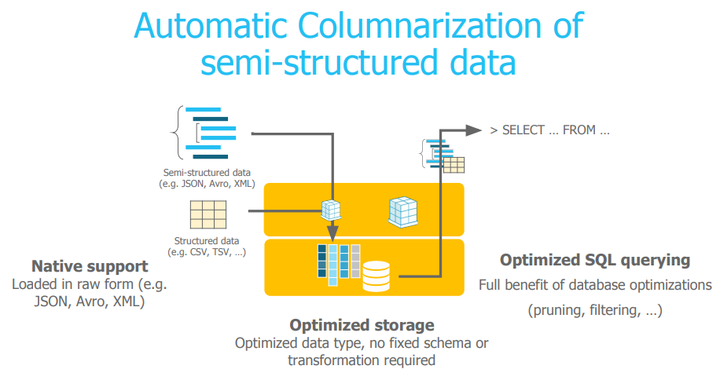
2.6.4半结构化和Schema-Less数据
Snowflake 通过三个数据类型来扩展SQL类型:VARIANT, ARRAY, and OBJECT。
VARIANT 可以保存任何原生SQL类型,也可以保存变长ARRAYs值,JavaScript类似的对象,string到VARIANT的映射信息
ARRAY 和OBJECT是限制版的VARIANT,内部实现是一样的:
a self-describing, compact binary serialization which supports fast key-value lookup, as well as efficient type tests, comparison, and hashing
列式存和处理
Cloudera Impala (using Parquet) and Google Dremel have demonstrated that columnar storage of semi-structured data is possible and beneficial. 、However,Impala and Dremel (and its externalization BigQuery)require users to provide complete table schemas for columnar storage.
To achieve both the flexibility of a schema-less serialized representation and the performance of a columnar
relational database, Snowflake introduces a novel automated approach to type inference and columnar storage
Snowflake 采用新颖的自动进行类型推断和列式数据存储的方式。
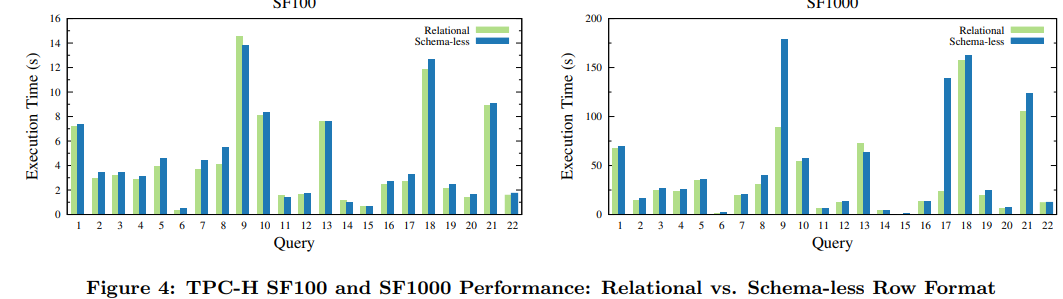
2.6.5 TCP-H性能
2.7安全
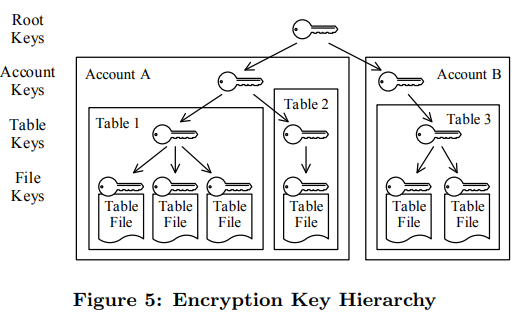
采用AES 256强加密方式分层加密,上层加密下层的key。Rootkey 保存在AWS CloudHSM(硬件)中。
每个用户独立的account key。
Key支持生命周期管理:
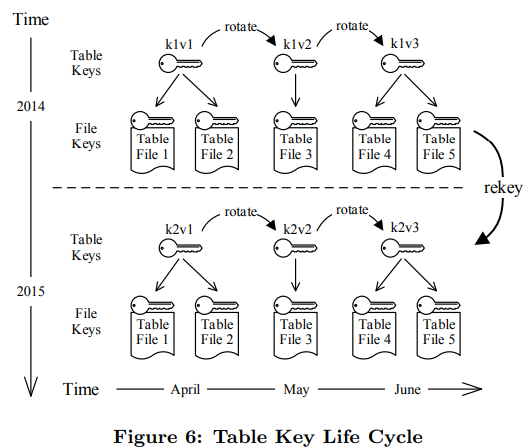
3.实际性能
从SIGMOD2016的论文上只提到了一些模糊的数据
The system runs several million queries per day over multiple petabytes of data.
每天数百万查询,支持数PB数据。
2018年:每天数百Million的查询,数百PB数据量
2020年:每天500 Million的查询
从snowflake分享的宣传材料上,提到的3个行业的性能比对
420/26 =16倍
480/1.5 = 320倍


和传统数仓比最高快200倍。
Gigaom 公司2019年提供的性能比对数据(sponsored by Microsoft)
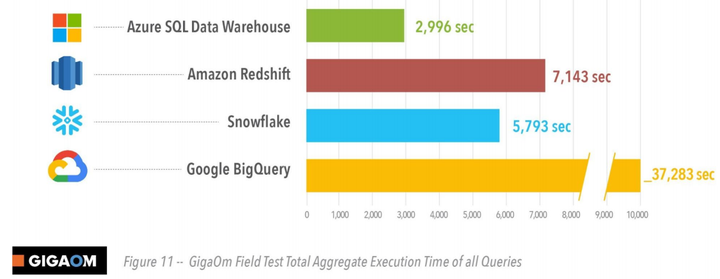
30TB的TPC-DS标准所有测试数据总共耗时
从测试结果来看,微软的Azure 的数据仓库性能排第一,Snowflake排第二。
2020年Fivetran公司提供的性能测试数据
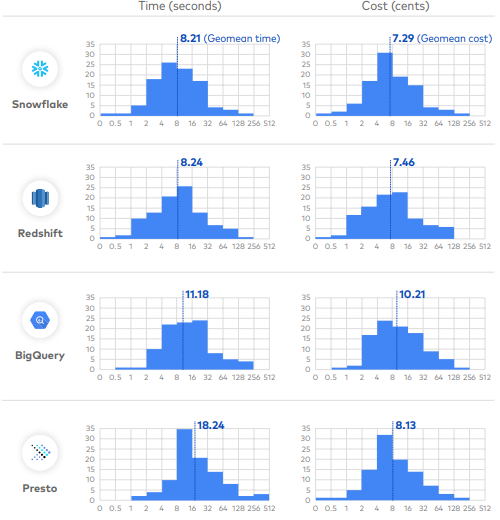
1TB TPC-DS性能测试数据
此测试数据没有微软的Azure数仓的比对。
In April 2019, Gigaom ran a version of the TPC-DS queries on BigQuery, Redshift, Snowflake and Azure SQL Data Warehouse. This benchmark was sponsored by Microsoft. They used 30x more data (30 TB vs 1 TB scale). They configured different-sized clusters for different systems, and observed much slower runtimes than we did:
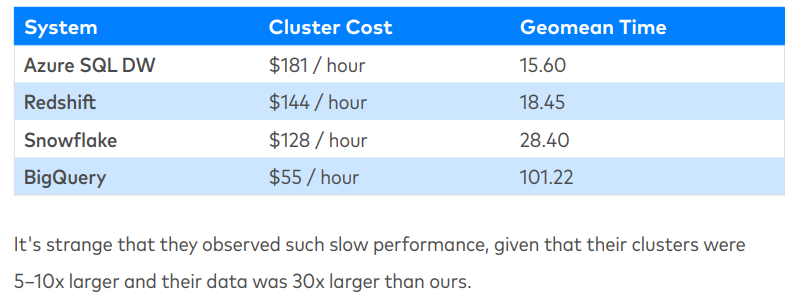
对于Gigaom2019的测试结果,Fivetran也感觉比较奇怪。
注:Fivetran 是Snowflake的合作伙伴,做数据集成的。
4.性价比
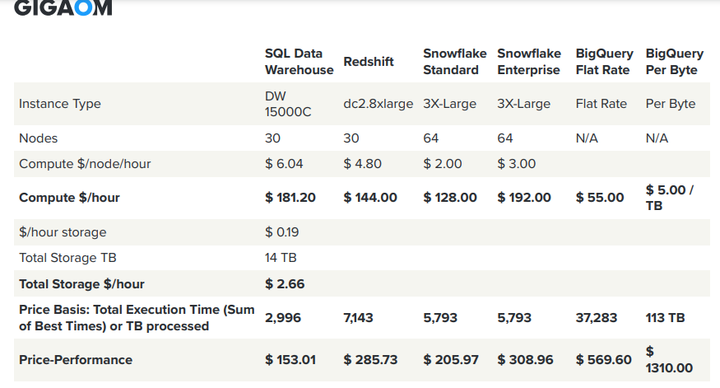
从Gigaom报告看,微软云数仓性价比第一,Snowflake排第二
从Gigaom和Fivetran 的报告来看,Snowflake的性能都排在Google的BigQuery和Redshift之前。
5.客户
2018年是1000多个用户
2020.1超过3000个用户,56个价值用户

注:客户信息来自IPO说明书
6.Snowflake设计的经验

半结构化处理带来的效果超出预期。

弹性比性能更重要。
7.挑战

当支持上万用户的并发访问时带来巨大挑战,例如元数据层变的巨大。
SQL性能调优,倾斜数据处理要持续优化。
8.后续规划(2018年的plan)

多云:(2020年支持微软 AWS Google)
从Snowflake的后续版本规划来看,也可以看出业界数仓产品的部分演进方向,例如 自动调优,物化视图,数据湖,流数据处理,时序数据处理(毕竟IOT大数据的分析也是一个重点方向)。
9.总结
从技术角度,Snowflake值得我们学习的技术点包括计算存储分离,PAX列式存储,向量化执行,元数据管理和缓存机制。
从管理的角度,一个好的产品成功。离不开牛人。

20多年的数据库设计经验
微软和oracle的大神
向量化查询的发明者。
10.附参考信息
SIGMOD 2016年的论文:
https://dl.acm.org/doi/pdf/10.1145/2882903.2903741
https://0xzx.com/202009202141832030.html
snowflake相关
https://www.slideshare.net/snowflakedb/data-sharing-with-snowflake
https://www.slideshare.net/Visual_BI/snowflake-the-most-costeffective-agile-and-scalable-data-warehouse-ever
https://www.slideshare.net/databricks/databricks-snowflake-catalyzing-data-and-ai-initiatives
https://www.slideshare.net/snowflakedb/the-struggle-for-data
https://www.slideshare.net/snowflakedb/introducing-the-snowflake-computing-cloud-data-warehouse
https://www.youtube.com/watch?v=xojAXXRo_S0
https://docs.snowflake.com/en/user-guide/intro-cloud-platforms.html
PAX相关
Weaving Relations for Cache Performance
https://research.cs.wisc.edu/multifacet/papers/vldb01_pax.pdf
Data Page Layouts for Relational Databases on Deep Memory Hierarchies
https://research.cs.wisc.edu/multifacet/papers/vldbj02_pax.pdf
Spanner: Becoming a SQL System
https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/46103.pdf
https://zhuanlan.zhihu.com/p/75330265
Data Blocks: Hybrid OLTP and OLAP on Compressed Storage using both Vectorization and Compilation
Snowflake参与编写
https://db.in.tum.de/downloads/publications/datablocks.pdf
存算分离性能参考
http://www.odbms.org/2018/01/how-the-separation-of-compute-and-storage-impacts-your-big-data-analytics-way-of-life/
IPO上市说明书
https://www.sec.gov/Archives/edgar/data/1640147/000162828020013010/snowflakes-1.htm
https://mp.weixin.qq.com/s/BeVHkj4rBRvFrtrseFDCvw
https://mp.weixin.qq.com/s/tdOLALrAtFBXh7szxco00w
https://zhuanlan.zhihu.com/p/54439354
https://segmentfault.com/a/1190000006655623
图解一致性hash算法:
https://segmentfault.com/a/1190000021199728