机器学习中往往会遇到样本特征非常多的情况,往往成千过万,这对于机器学习是非常不利的,被称为维数灾难:
1、高维空间样本具有稀疏性,模型较难找到数据特征;
2、维度过高,导致计算量太大。
维度过高,那么就需要降维,另外一个途径则是特征选择。这两种方法目标都是减少特征维数,但在原理上不同,降维主要是将原始高维空间的点投影到一个低维空间,特征本身发生了变化。而特征选择则是从N个特征中选择一些对判决结果影响较小的特征进行丢弃,剩下的特征没有发生变化。简单理解,降维是对原特征空间的压缩,而特征选择则是使用原有特征的一个子集。
降维的主要方法有多维缩放(MDS)、主成分分析(PCA)、线性判别分析(LDA)。
-- 多维缩放(MDS)
多维缩放中最关键的是要求低维空间中的样本距离尽可能与原始空间中样本距离保持一致。
假设给定N个样本,表示原始空间中的距离矩阵,其中第i行第j列的元素dij表示第i个实例和第j个实例之间的距离,目标是获得d’维空间中样本表示,且任意两个样本在d’维空间中的距离等于在原始空间中的距离,即
-- 主成分分析(PCA)
PCA的主要思想是希望将高维的数据降到低维,且要求变换后的数据能表示原始数据的主要信息,在降维的前提下,损失尽可能少。
我们以最简单的2维降到1维为例,希望能找到一个维度方向,能尽可能表示二维的数据信息,如下图所示,有两个维度方向,u1和u2,那哪个维度方向更好呢?从图上看,显然是u1比u2更优,从两个方面来看,一、样本点到u1的距离比u2更近;二、样本点在u1的投影比在u2的投影更分散。这就引出了PCA的两个核心原则:
最近重构性(最小投影距离):样本点到这个超平面的距离都足够近
最大可分性*(最大投影方差):样本点在这个超平面上的投影尽可能的分开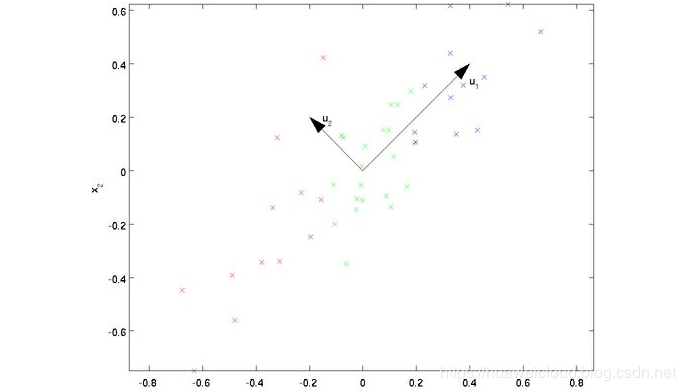
基于以上两个准则,PCA有两种等价推导:基于最小投影距离和基于最大投影方差
具体的数学推导可参考:
https://www.cnblogs.com/pinard/p/6239403.html
-- 线性判别分析(LDA)
LDA是一种基于分类模型进行特征属性合并的方法,是一种有监督的降维方式,其本身也可以作为一种分类算法。而PCA是不考虑样本类比输出的无监督降维方法。LDA的原理是将带有标签的数据通过投影的方法,投影到维度更低的空间中,使得投影后的点可按类区分,相同类别的点,在投影后的空间中更接近。用一句话话就是:“投影后类内方差最小,类间方差最大”。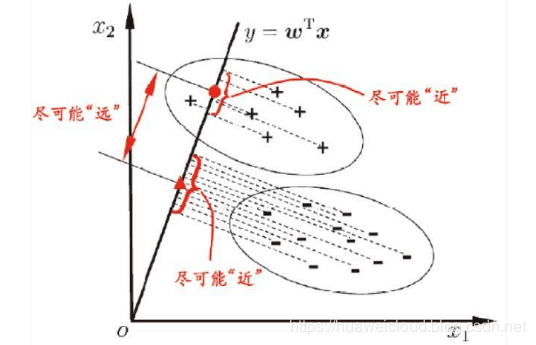
假设有两类数据,分别为红色和蓝色,这些数据特征是二维的,希望降低到一维,让每一类数据的投影点尽可能接近,而红色和蓝色数据中心之间的距离尽可能大。
下图是两种投影方式,按照LDA的准则来看,右图显然比左图更好,因为右图中两类数据类间间隔更大,类内更聚合。

算法详细推导可参考:
https://www.cnblogs.com/pinard/p/6244265.html
代码示例
PCA和LDA在sklearn中已经有现成的接口,可以直接使用,我们还是拿sklearn中自带的癌症数据进行验证,数据集一共有30个特征属性,我们分别用PCA和LDA的方法进行降维,看看效果怎么样。
-Python 代码
1 __author__ = 'z00421185' 2 3 from sklearn import datasets 4 from sklearn.decomposition import PCA 5 from sklearn.discriminant_analysis import LinearDiscriminantAnalysis 6 from sklearn.model_selection import train_test_split 7 from sklearn.metrics import accuracy_score 8 from sklearn.linear_model import LogisticRegression 9 10 breast_data = datasets.load_breast_cancer() 11 data_np = breast_data['data'] 12 target_np = breast_data['target'] 13 14 # 查看原始数据各成分的方差百分比(越大表示该成分含信息越多,越应该保留) 15 pca_init = PCA(n_components=30) 16 new_data = pca_init.fit_transform(data_np) 17 print(pca_init.explained_variance_ratio_) 18 19 # PCA从30维降维到10,并得到降维后的新数据 20 pca = PCA(n_components=10) 21 data_pca = pca.fit_transform(data_np) 22 23 # LDA从30维降维到1,LDA要求必须小于类别数-1,这里是二分类,只能是1,降维并得到降维后的新数据 24 lda = LinearDiscriminantAnalysis(n_components=1) 25 lda.fit(data_np, target_np) 26 data_lda = lda.transform(data_np) 27 28 # 对比降维前后的效果,除训练数据外,模型及模型参数都一致 29 train_X, test_X, train_y, test_y = train_test_split(data_np, target_np, test_size = 0.2, random_state = 0) 30 train_X_pca, test_X_pca, train_y_pca, test_y_pca = train_test_split(data_pca, target_np, test_size = 0.2, random_state = 0) 31 train_X_lda, test_X_lda, train_y_lda, test_y_lda = train_test_split(data_lda, target_np, test_size = 0.2, random_state = 0) 32 33 model = LogisticRegression(C=1.0, tol=1e-6) 34 model_pca = LogisticRegression(C=1.0, tol=1e-6) 35 model_lda = LogisticRegression(C=1.0, tol=1e-6) 36 model.fit(train_X, train_y) 37 model_pca.fit(train_X_pca, train_y_pca) 38 model_lda.fit(train_X_lda, train_y_lda) 39 40 y_pred = model.predict(test_X) 41 y_pred_pca = model_pca.predict(test_X_pca) 42 y_pred_lda = model_lda.predict(test_X_lda) 43 44 # 训练数据量及准确率对比 45 print("原始数据量:%s PCA后数据量:%s LDA后数据量:%s" % (data_np.size, data_pca.size, data_lda.size)) 46 print("初始模型准确率:%s PCA后模型准确率:%s LDA后模型准确率:%s" 47 % (accuracy_score(test_y, y_pred), accuracy_score(test_y_pca, y_pred_pca),accuracy_score(test_y_lda, y_pred_lda))) 48 ===================================================== 49 原始数据量:17070 50 PCA后数据量:5690 51 LDA后数据量:569 52 初始模型准确率:0.956140350877193 53 PCA后模型准确率:0.9473684210526315 54 LDA后模型准确率:0.9736842105263158
从上面的验证可以看出,在带标签数据中,PCA虽然能有效降低数据维度,降低运算复杂度,但会丢失一些类别信息,最后的分类准确度会受到影响;而LDA不仅大幅降低了数据维度,而且降维后准确度还有提升。
PCA和LDA在不同场景下的选择:
- 在带标签数据的降维中,优先选择LDA,如果没标签,则优先选择PCA;
- LDA降维最多到类别数据k-1,而PCA则没有这个限制;
- LDA除了降维,也可以用于分类;
- LDA在样本分类信息依赖方差而不是均值时,降维效果不如PCA
HDC.Cloud 华为开发者大会2020 即将于2020年2月11日-12日在深圳举办,是一线开发者学习实践鲲鹏通用计算、昇腾AI计算、数据库、区块链、云原生、5G等ICT开放能力的最佳舞台。
欢迎报名参会(https://www.huaweicloud.com/HDC.Cloud.html?utm_source=&utm_medium=&utm_campaign=&utm_content=techcommunity)
