写在前面:
前三篇文字<<基于MQTT协议谈谈物联网开发-华佗写代码>>,<<基于MQTT协议实现Broker-华佗写代码>>,<<基于WebSocket实现Broker-华佗写代码>>主要叙述了MQTT协议的编解码以及基于MQTT协议的一些常见应用场景,并以一个简单的消息推送系统作为例子具体阐述了Mqtt Broker部分的实现,具体包括通过Mqtt,以及Mqtt Over WebSocket的方式打通各个端的数据通信,本篇文字继续以消息推送系统作为例子,阐述其状态系统的实现,具体的消息推送系统架构草图,需要参考回看第一篇文字,不再赘述.
1.缓存技术:
常见缓存技术主要有redis,memcached等,甚至也可使用mongodb或者mq,leveldb或者rocksdb等作为缓存,不同技术都有其优缺点,以redis为例,其可以通过代理和集群,实现分布式缓存系统,可以根据业务需要选择是否持久化,支持多种数据结构以及事务,但其服务器内存会是瓶颈,以及在处理一些复杂数据结构时,比如缓存用户登录状态,包括用户的Appid,设备token,是否切换为后台等等,这就可能需要不停地序列化和反序列化,比如redis的hash和sortedset结构等.再比如查找时,以sortedset为例,其底层是基于跳跃表来实现的,查找时间复杂度O(lgn),存储的数据越多,平均查询时间也会越长.所以,需要根据自身业务需求来选用合适技术,作为例子,这里基于共享内存和多重哈希来实现这样一个分布式缓存系统.
2.状态系统具体实现:
2.1状态系统架构草图:
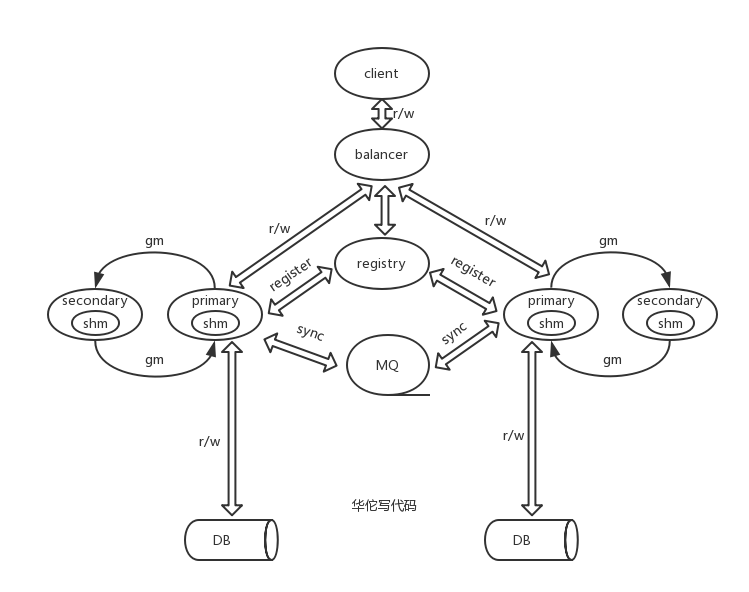
2.2状态系统实现细节说明:
(1)整体架构主要包括负载均衡器,服务发现,MQ队列,缓存集群主从节点,DB;
(2)不同集群节点跨机房或者跨IDC部署,MQ队列用于不同集群之间写数据同步;
(3)每个集群节点包括一主多从节点,图示以一主一从为例示意,主和从节点都包括gm模块形成链表结构进行数据同步,具体可参考RabbitMQ镜像队列相关原理;
(4)主从节点都包括shm模块,即共享内存模块,用于存储状态数据;
(5)基于哈希结构存储数据,以达O(1)时间复杂度,通过多重哈希和最老节点覆盖写机制,解决哈希冲突;
(6)用户登录存储状态数据,登出删除状态数据,每个用户状态都同时存储其存取时间戳,用于过期淘汰或者扩容时做相关判断;
(7)以用户的Appid,Token等为例进行数据缓存;
(8)DB根据业务需要决定是否分库分表;
(9)其他...
2.3状态系统代码实现(shm模块,跟之前几篇文字基于golang编写不同,这里基于C/C++编写):
2.3.1定义用户状态数据结构体,以及哈希结构体头部,如下:
const std::string GROCACHE_SHMFILE= "/shm/HashTableShmGroCache";
//存储的用户数量,作为例子,这里设置为100,实际应用需要根据自身应用的用户数量合理设置
const uint32_t GROCACHE_HASHNODE_CNT = 100;
//计算每个用户状态节点占用的字节数: 4+8+4+4+4+4+4+4+4+4+32
const uint32_t GROCACHE_HASHNODE_SIZE = 76;
const uint32_t GROCACHE_MAXROW_CNT = 4;
//定义用户状态数据结构体
#pragma pack (1)
struct GroCacheNode
{
uint32_t hashKey; //计算哈希值
uint64_t tinyid;
uint32_t appid;
uint32_t settoken;
uint32_t background;
uint32_t sdkappid;
uint32_t busiid;
uint32_t unreadcnt;
uint32_t accessTime; //数据存取时间
uint32_t tokenlen;
uint8_t token[0];
};
//定义哈希结构体头部
#pragma pack (1)
struct GroCacheHeader
{
uint32_t hashMemSize; // hashMemSize
uint32_t hashNodeSize; // size of each hash node
uint32_t hashNodeCnt; // num of all hash node
uint32_t rowCnt; // row`s num
uint32_t rowsNodeCnt[GROCACHE_MAXROW_CNT]; // node num of each row's
uint32_t rowsStartNode[GROCACHE_MAXROW_CNT];// each row's starting node index
uint32_t maxUsedRow; // max row index (start at 0) in use
uint32_t usedCnt;
};
2.3.2根据预估用户数量开辟共享内存大小,并计算多重哈希每一级存储的节点数量比例,第一级哈希数组会存储将近70%的数据节点:
//开辟并初始化共享内存,保存共享内存元数据
bool MultiHashTable::initGC() { bool iRet = true; do { void* pShm = NULL; string shmFileName = GROCACHE_SHMFILE;
//计算需要分配的共享内存大小,以字节为单位 uint32_t hashMemSize = sizeof(GroCacheHeader) + (GROCACHE_HASHNODE_CNT * GROCACHE_HASHNODE_SIZE); bool exist = false;
//真正申请开辟共享内存 if(false == ShareMemory::Instance()->create(&pShm, shmFileName, hashMemSize, exist)) { iRet = false; break; } _grocacheHeader = (GroCacheHeader*)pShm; ...
if(false == exist) { printf("share memory first create, hashtable need initial "); memset(_grocacheHeader, 0, sizeof(*_grocacheHeader)); _grocacheHeader->hashMemSize = hashMemSize; _grocacheHeader->hashNodeSize = GROCACHE_HASHNODE_SIZE; _grocacheHeader->rowCnt = GROCACHE_MAXROW_CNT;
//通过CalcNodeCntForEachRow函数计算每一级哈希存储的节点数量,以及每一级哈希的起始索引位置 _grocacheHeader->hashNodeCnt = CalcNodeCntForEachRow(GROCACHE_MAXROW_CNT, GROCACHE_HASHNODE_CNT, _grocacheHeader->rowsNodeCnt, _grocacheHeader->rowsStartNode); _grocacheHeader->maxUsedRow = 0; _grocacheHeader->usedCnt = 0; } //header+ht _grocacheHt = _grocacheHeader + 1; printf("_grocacheHeader hashMemSize:%u,hashNodeSize:%u,hashNodeCnt:%u,maxUsedRow:%u ", _grocacheHeader->hashMemSize,_grocacheHeader->hashNodeSize,_grocacheHeader->hashNodeCnt,_grocacheHeader->maxUsedRow); }while(false); return iRet; }
2.3.3开辟共享内存,不同系统共享内存大小有限制,根据需要决定是否修改相关系统配置:
bool ShareMemory::create(void** pShm, const std::string& shmFileName, const uint32_t& shmSize, bool& exist, bool reset)
{
exist = false;
printf("create shmFileName:%s, shmSize:%u
", shmFileName.c_str(), shmSize);
bool iRet = false;
do
{
uint32_t shmKey = 0;
if(false == getShmKey(shmFileName, shmKey))
{
printf("create getShmKey failed,shmFileName:%s
", shmFileName.c_str());
break;
}
int shmFlag = 0666 | IPC_CREAT;
int shmId = shmget(shmKey, 0, 0);
if(-1 == shmId)
{
//no existed shm, need to create a new one
printf("create a new share memory shmSize:%d
",shmSize);
shmId = shmget(shmKey, shmSize, shmFlag);
if(-1 == shmId)
{
printf("create shmget failed errno=%d , errmsg=%s
", errno, strerror(errno));
break;
}
}
...
if(reset)
{
memset(*pShm, 0, shmSize);
exist = false;
}
iRet = true;
}while(false);
return iRet;
}
3.测试例子:
#include <stdio.h>
#include "MultiHashTable.h"
using namespace std;
int main() {
//初始化用户状态节点
GroCacheNode gcSetNode;
gcSetNode.appid = 666;
gcSetNode.settoken = 1;
gcSetNode.background = 1;
gcSetNode.sdkappid = 999;
gcSetNode.busiid = 9999;
gcSetNode.unreadcnt = 0;
string token = "user_device_token";
//模拟用户登录,存储用户状态数据
uint64_t uin = 888888888;
uint32_t hashKey = 99;
MultiHashTable::instance()->SetGroCache(hashKey, uin, gcSetNode, token);
//修改用户推送消息未读计数
bool iRet = false;
uint32_t unreadcnt = 99;
iRet = MultiHashTable::instance()->SetGroCacheUnReadCnt(hashKey, uin, unreadcnt);
printf("[main]SetGroCacheUnReadCnt iRet:%d
", iRet);
//读取用户推送消息未读计数
uint32_t getunreadcnt = 0;
iRet = MultiHashTable::instance()->GetGroCacheUnReadCnt(hashKey, uin, getunreadcnt);
printf("[main]GetGroCacheUnReadCnt iRet:%d, getunreadcnt:%d
", iRet, getunreadcnt);
return 0;
}
4.运行测试结果,如下图所示,表明创建了共享内存文件,并计算了每一级哈希的节点数量,最后插入一条用户状态数据,并存取相关未读计数值:
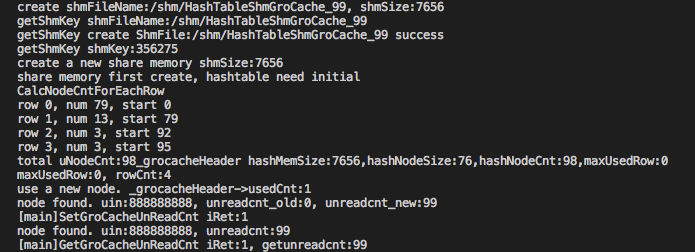
出于篇幅考虑,上述使用到的具体一些函数,如MaxPrime,CalcNodeCntForEachRow等,其具体实现就不一一列举出来了,也有一些成员变量,用到了也不一一具体注释了,主要通过架构图和具体代码关键路径叙述实现的一些细节,阐明主要设计思路以及解决问题的主要矛盾,如有错误,恳请指出,转载也请注明出处!!!
未完待续...
参考文字: RabbitMQ