什么是高并发
高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。
高并发相关常用的一些指标有响应时间(Response Time),吞吐量(Throughput),每秒查询率QPS(Query Per Second),并发用户数等。
响应时间:系统对请求做出响应的时间。例如系统处理一个HTTP请求需要200ms,这个200ms就是系统的响应时间。
吞吐量:单位时间内处理的请求数量。
QPS:每秒响应请求数。在互联网领域,这个指标和吞吐量区分的没有这么明显。
并发用户数:同时承载正常使用系统功能的用户数量。例如一个即时通讯系统,同时在线量一定程度上代表了系统的并发用户数。
如何提升系统的并发能力
互联网分布式架构设计,提高系统并发能力的方式,方法论上主要有两种:垂直扩展(Scale Up)与水平扩展(Scale Out)。
垂直扩展:提升单机处理能力。垂直扩展的方式又有两种:
(1)增强单机硬件性能,例如:增加CPU核数如32核,升级更好的网卡如万兆,升级更好的硬盘如SSD,扩充硬盘容量如2T,扩充系统内存如128G;
(2)提升单机架构性能,例如:使用Cache来减少IO次数,使用异步来增加单服务吞吐量,使用无锁数据结构来减少响应时间;
水平扩展:只要增加服务器数量,就能线性扩充系统性能。
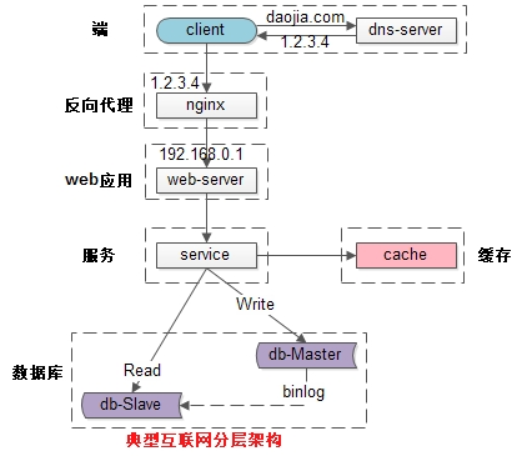
常见互联网分布式架构如上,分为:
(1)客户端层:典型调用方是浏览器browser或者手机应用APP
(2)反向代理层:系统入口,反向代理
(3)站点应用层:实现核心应用逻辑,返回html或者json
(4)服务层:如果实现了服务化,就有这一层
(5)数据-缓存层:缓存加速访问存储
(6)数据-数据库层:数据库固化数据存储
关于三种应对大并发的常见优化方案
【数据库缓存】
为什么是要使用缓存?
缓存数据是为了让客户端很少甚至不访问数据库,减少磁盘IO,提高并发量,提高应用数据的响应速度。
【CDN加速】
什么是CDN?
CDN的全称是Content Delivery Network,CDN系统能够实时地根据网络流量和各节点的连接、负载状况以及到用户的距离等综合信息将用户的请求重新导向离用户最近的服务节点上。
使用CDN的优势?
CDN的本质是内存缓存,就近访问,它提高了企业站点(尤其含有大量图片和静态页面站点)的访问速度,跨运营商的网络加速,保证不同网络的用户都得到良好的访问质量。
同时,减少远程访问的带宽,分担网络流量,减轻原站点WEB服务器负载。
二 什么是高可用
高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。
假设系统一直能够提供服务,我们说系统的可用性是100%。
如果系统每运行100个时间单位,会有1个时间单位无法提供服务,我们说系统的可用性是99%。
很多公司的高可用目标是4个9,也就是99.99%,这就意味着,系统的年停机时间为8.76个小时。
如何保障系统的高可用
我们都知道,单点是系统高可用的大敌,单点往往是系统高可用最大的风险和敌人,应该尽量在系统设计的过程中避免单点。方法论上,高可用保证的原则是“集群化”,或者叫“冗余”:只有一个单点,挂了服务会受影响;如果有冗余备份,挂了还有其他backup能够顶上。
保证系统高可用,架构设计的核心准则是:冗余。

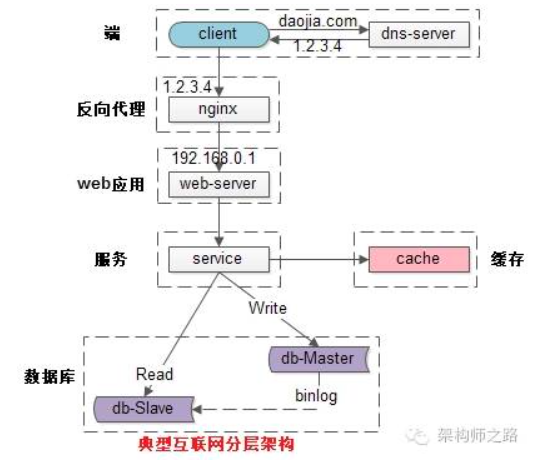
常见互联网分布式架构如上,分为:
(1)客户端层:典型调用方是浏览器browser或者手机应用APP
(2)反向代理层:系统入口,反向代理
(3)站点应用层:实现核心应用逻辑,返回html或者json
(4)服务层:如果实现了服务化,就有这一层
(5)数据-缓存层:缓存加速访问存储
(6)数据-数据库层:数据库固化数据存储
整个系统的高可用,又是通过每一层的冗余+自动故障转移来综合实现的。
高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务的时间。
方法论上,高可用是通过冗余+自动故障转移来实现的。
整个互联网分层系统架构的高可用,又是通过每一层的冗余+自动故障转移来综合实现的,具体的:
(1)【客户端层】到【反向代理层】的高可用,是通过反向代理层的冗余实现的,常见实践是keepalived + virtual IP自动故障转移
(2)【反向代理层】到【站点层】的高可用,是通过站点层的冗余实现的,常见实践是nginx与web-server之间的存活性探测与自动故障转移
(3)【站点层】到【服务层】的高可用,是通过服务层的冗余实现的,常见实践是通过service-connection-pool来保证自动故障转移
(4)【服务层】到【缓存层】的高可用,是通过缓存数据的冗余实现的,常见实践是缓存客户端双读双写,或者利用缓存集群的主从数据同步与sentinel保活与自动故障转移;更多的业务场景,对缓存没有高可用要求,可以使用缓存服务化来对调用方屏蔽底层复杂性
(5)【服务层】到【数据库“读”】的高可用,是通过读库的冗余实现的,常见实践是通过db-connection-pool来保证自动故障转移
(6)【服务层】到【数据库“写”】的高可用,是通过写库的冗余实现的,常见实践是keepalived + virtual IP自动故障转移
水平切分+锁粒度优化
上文中之所以锁冲突严重,是因为所有司机都公用一把锁,锁的粒度太粗(可以认为是一个数据库的“库级别锁”),是否可能进行水平拆分(类似于数据库里的分库),把一个库锁变成多个库锁,来提高并发,降低锁冲突呢?显然是可以的,把1个Map水平切分成多个Map即可:
总结
在【超高并发】,【写多读少】,【定长value】的【业务缓存】场景下:
1)可以通过水平拆分来降低锁冲突
2)可以通过Map转Array的方式来最小化锁冲突,一条记录一个锁
3)可以把锁去掉,最大化并发,但带来的数据完整性的破坏
4)可以通过签名的方式保证数据的完整性,实现无锁缓存