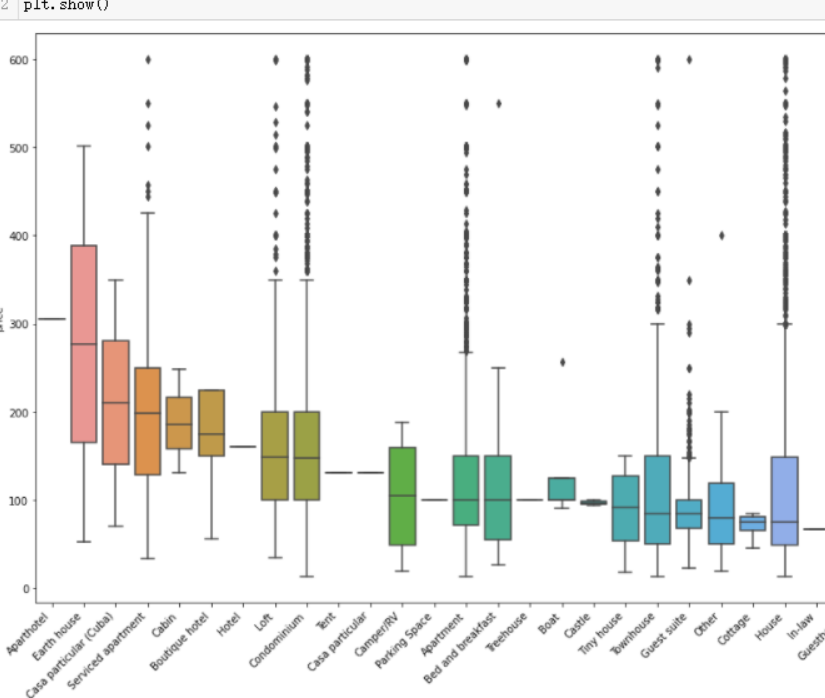
通过对review_scores_rating评分字段进行分布图绘制,可以查看价格的分布区间范围
#设置画布大小尺寸 plt.figure(figsize=(12,6)) #绘制分布图 sns.distplot(listings.review_scores_rating.dropna(), rug=True) #取消右侧和上侧坐标轴 sns.despine()
输出结果如下:(此处的评分标准为0-100分制,通过上述表格可以看出总体来看爱彼迎的房屋好评率非常高)
3.6 房源价格情况
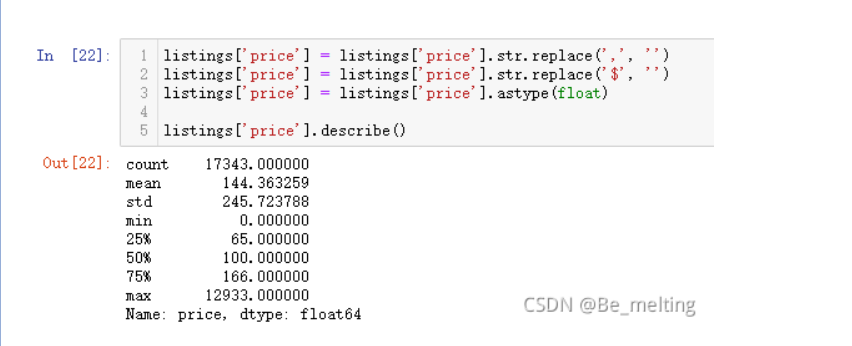
前面探究了房源价格和星期之间的关联,但是房价字段自身的信息并没有探究,可以使用describe查看价格的情况
listings['price'] = listings['price'].str.replace(',', '')
listings['price'] = listings['price'].str.replace('$', '')
listings['price'] = listings['price'].astype(float)
listings['price'].describe()
输出结果如下:(多伦多最昂贵的Airbnb房源价格为$ 12933 /晚(当时的价钱,现在的价钱是$ 64818 /晚),以下是房屋的链接:https://www.airbnb.ca/rooms/16039481?locale=en。通过链接可以发现之所以比平均价贵出约100倍,主要是因为这处房屋是多伦多最时尚的社区中的艺术收藏家阁楼。这些艺术收藏的价值大幅的拉高了这处房源的价格,使其和平均值有100倍的差距)
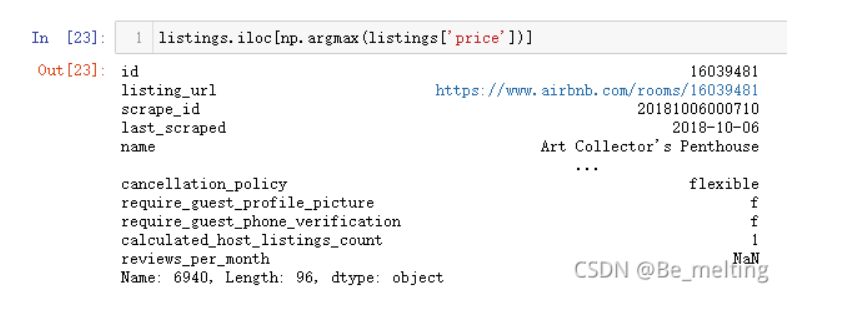
如果需要查看一下最大值或者最小值对应的记录,可以使用argmax或者argmin如下代码
listings.iloc[np.argmax(listings['price'])]
输出结果如下:(通过name信息可以核实,这份房源就是属于Art Collector艺术收藏品 )
由于在数据分析中,我们需要服从正态分布的原则,对于这样极端情况的存在,我们需要进行清理,所以把异常的价格的数据进行过滤,最终选择的价钱是保留0-600之间的数据。具体要选取某一数值,需要看一下当前数值以上对应的房源信息数量占全体的比重,这里选取大于600以上的房源仅有200+套,占总比1w+的比例很小,而且房源免费的只有7套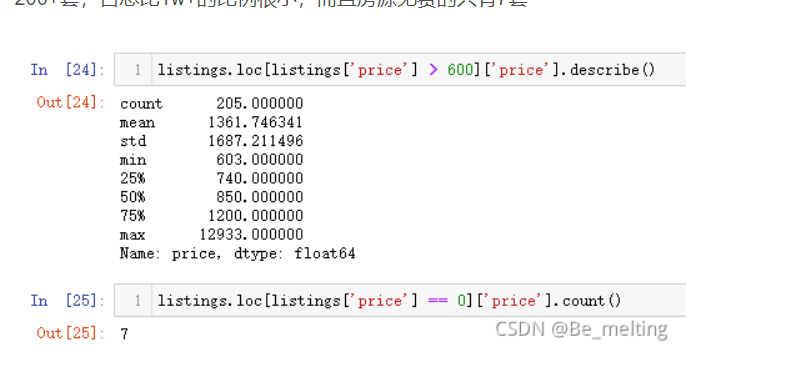
plt.figure(figsize=(18,10))
sort_price = listings.loc[(listings.price <= 600) & (listings.price > 0)]\
.groupby('neighbourhood_cleansed')['price']\
.median()\
.sort_values(ascending=False)\
.index
sns.boxplot(y='price', x='neighbourhood_cleansed', data=listings.loc[(listings.price <= 600) & (listings.price > 0)],
order=sort_price)
ax = plt.gca()
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha='right')
plt.show()
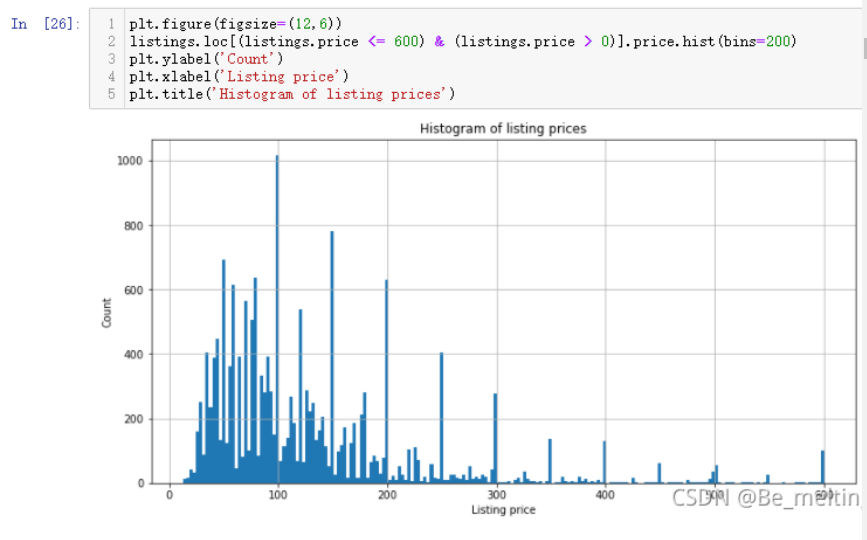
掉极端值后我们继续观察现在的价格分布状态,绘制直方图
plt.figure(figsize=(12,6))
listings.loc[(listings.price <= 600) & (listings.price > 0)].price.hist(bins=200)
plt.ylabel('Count')
plt.xlabel('Listing price')
plt.title('Histogram of listing prices')
输出结果如下:(分箱数量bins可以自由指定,可以看出价格主要是在30-200之间)
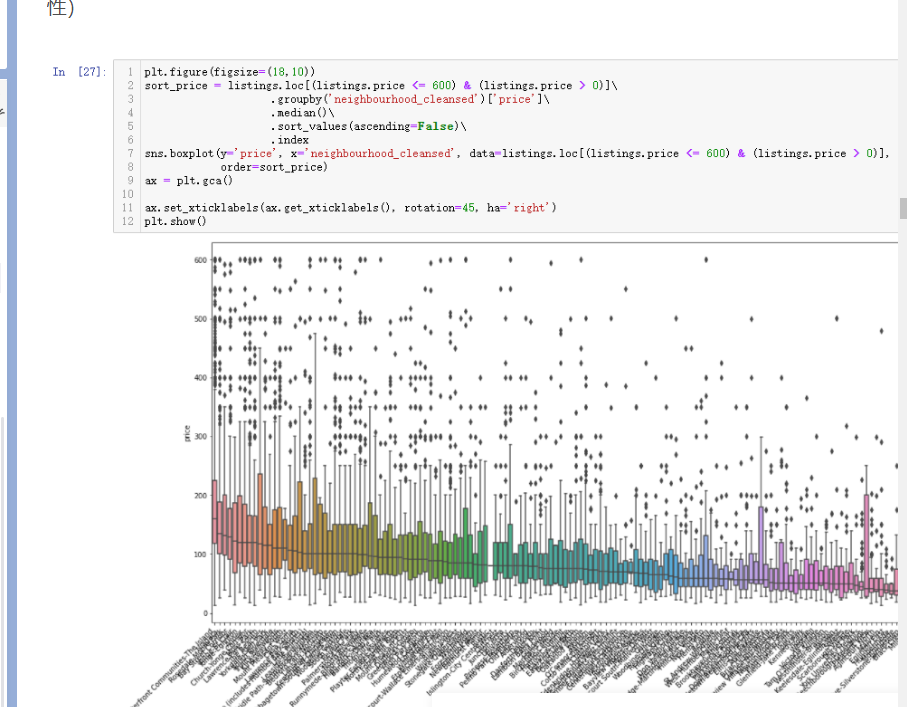
3.7 不同社区与房源价格的关系
前面探究了不同社区和房源数量之间的关系,这里可以进一步探究不同社区和房源价钱之间的关系
输出结果如下:(最好的社区不仅房源的最高价高,而且平均价格也是所有社区中最高的,很有代表性)
sns.boxplot(y='price', x='host_is_superhost', data=listings.loc[(listings.price <= 600) & (listings.price > 0)]) plt.show()
3.8 品质房和普通房
在预定酒店时,浏览页面中常常会推出品质房源和普通房源,在这份数据集中也是存在字段记录这方面的信息,可以对比研究一下两者的价钱情况
sns.boxplot(y='price', x='host_is_superhost', data=listings.loc[(listings.price <= 600) & (listings.price > 0)]) plt.show()
3.8 配套设施和房价的关系
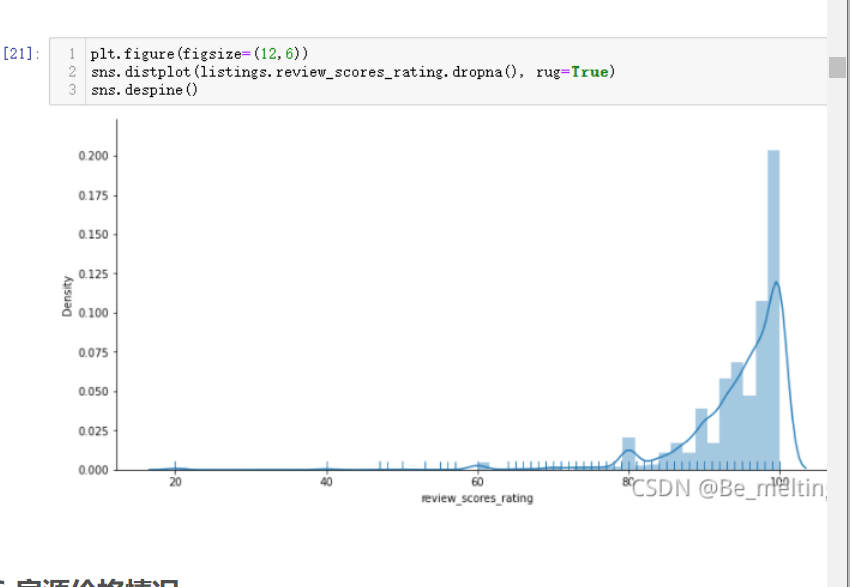
酒店中的软装特性和多少也是和房源的价钱有着密切的关系,可以依循探究不同社区的房源价格的方式进行分析,代码基本上进行字段的修改就可以
plt.figure(figsize=(18,10))
sort_price = listings.loc[(listings.price <= 600) & (listings.price > 0)]\
.groupby('property_type')['price']\
.median()\
.sort_values(ascending=False)\
.index
sns.boxplot(y='price', x='property_type', data=listings.loc[(listings.price <= 600) & (listings.price > 0)], order=sort_price)
ax = plt.gca()
ax.set_xticklabels(ax.get_xticklabels(), rotation=45, ha='right')
plt.show()
输出结果如下:(在今后绘制此类图形时候,代码可以直接复制后修改对应的字段和限制的范围即可。从这个图中可以看到在数据处理时,如果对于极端值不进行处理,则会显示出这样怪异的情况,例如Aparthotel 公寓式酒店 这个关键词的价格最高,但是通过boxplot我们又可以看出,其实只有一套这样的房产,所以数据并不完整。tend(帐篷)和parking space (停车位)这样的关键词也是数量很少的,导致了数据结果显示不准确)