Spark Streaming允许DStream的数据被输出到外部系统,如数据库或文件系统。由于输出操作实际上使transformation操作后的数据可以通过外部系统被使用,同时输出操作触发所有DStream的transformation操作的实际执行(类似于RDD操作)。以下表列出了目前主要的输出操作:
|
转换
|
描述
|
|
print()
|
在Driver中打印出DStream中数据的前10个元素。
|
|
saveAsTextFiles(prefix, [suffix])
|
将DStream中的内容以文本的形式保存为文本文件,其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。
|
|
saveAsObjectFiles(prefix, [suffix])
|
将DStream中的内容按对象序列化并且以SequenceFile的格式保存。其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。
|
|
saveAsHadoopFiles(prefix, [suffix])
|
将DStream中的内容以文本的形式保存为Hadoop文件,其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。
|
|
foreachRDD(func)
|
最基本的输出操作,将func函数应用于DStream中的RDD上,这个操作会输出数据到外部系统,比如保存RDD到文件或者网络数据库等。需要注意的是func函数是在运行该streaming应用的Driver进程里执行的。
|
|
|
| |
|
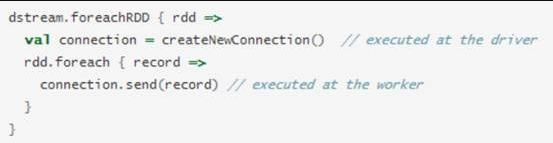
dstream.foreachRDD是一个非常强大的输出操作,它允将许数据输出到外部系统。但是 ,如何正确高效地使用这个操作是很重要的,下面展示了如何去避免一些常见的错误。
通常将数据写入到外部系统需要创建一个连接对象(如 TCP连接到远程服务器),并用它来发送数据到远程系统。出于这个目的,开发者可能在不经意间在Spark driver端创建了连接对象,并尝试使用它保存RDD中的记录到Spark worker上,如下面代码: