概念
分类是OC中特有的语法,它表示一个指向分类的结构体的指针,原则上只能增加方法 不能增加成员(实例)变量。
探究
我们都知道 一个类的实例对象调用实例方法时 是通过实例对象的isa指针找到类对象 然后在其或者父类对象存储的方法中找到实现的 类对象调用类方法是在其isa指针指向的元类对象的方法列表中找到实现的。那么我们利用分类添加的方法存储在哪里呢。结论是在程序运行期间 通过RunTime动态的将分类中的方法合并到类对象和元类对象中的。
struct _category_t { const char *name;//类名 struct _class_t *cls; const struct _method_list_t *instance_methods; //实例方法 const struct _method_list_t *class_methods;// 类方法 const struct _protocol_list_t *protocols;//协议信息 const struct _prop_list_t *properties;//属性 };
上面就是编译后分类结构。就是我们编译的时候我们添加的方法都会存储在上面的结构体之中。在这个阶段类和分类里面的信息还是分开的。
也就是说所有的分类 在编译完之后所有的信息都是存放在一个叫_category_t的结构体实例里面的。然后在运行的时候RunTime会将这些方法啊 属性啊 合并到类对象和元类对象中,合并时这些方法在方法列表的前列。所以如果和分类和类中的方法同名,那么调用方法时,会调用分类中的方法。但是元类中的方法并没有覆盖掉 只是调用顺序靠后了,不能再找到它了。如果一个类有多个分类,每个分类中都有相同的方法,那么调用哪个实现,取决于编译时哪个最后被编译的,因为最后被编译的在合并时会最靠前。类扩展添加的属性和方法在编译完成后就合并在类原来的数据里面了.
总结一下
1.通过RunTime加载某个类的所有Category数据
2.把所有Category的方法 属性 协议数据 合并到一个大的数组中 后面参与编译的Category数据 会在数组的前面
3.将合并后的分类数据(方法 属性 协议) 插入到类原来数据的前面
1.Category的实现原理?
Category编译之后的底层结构体是struct _category_t 里面包含方法列表 属性列表 协议列表等等
在程序运行的时候 runtime会将Category中保存的数据合并到类信息中(类对象 元类对象)
2.Category和Class Extension的区别是什么?
类扩展在编译的时候 它的数据已经包含在类信息中
Category在运行时 才会将数据合并到类信息中 而且分类中添加的属性 需要手动添加setter和getter方法
3.Category中有load方法吗?load方法是什么时候调用的?load方法能继承吗?
有load方法,load方法会在RunTime加载类 分类的时候调用 而且只调用一次。在程序开始运行的时候会把我们项目中所有的类和分类都载进内存 这个时候会调用所有类和分类的load方法
不管是原有类还是分类的load都会调用,分类的load方法不能导致原有类的load方法不能调用,因为load方法的调用不是走的消息发送机制 而是通过类 分类 找到该方法的函数指针直接调用。(而且是通过函数指针直接调用的) load方法是可以继承的 但是我们平常不会主动调用load方法 都是让系统主动调用 而且我们主动调用load方法 走的是消息发送机制
+load方法和+initialize方法
load方法会在RunTime加载类 分类的时候调用 而且只调用一次。在程序开始运行的时候会把我们项目中所有的类和分类都载进内存 这个时候会调用所有类和分类的load方法
不管是原有类还是分类的load都会调用,分类的load方法不能导致原有类的load方法不能调用,因为load方法的调用不是走的消息发送机制 而是通过类 分类 找到该方法的函数指针直接调用。
+initialize会在该类第一次接收到消息是调用 如果该类未接收到任何信息 那么就不会被调用 而且走的是消息发送机制
调用顺序:
1.先调用类的load方法(按照编译顺序先后调用 先编译先调用 调用子类的load方法前会先调用父类的load方法)
2.再调用分类的load(按照编译先后调用 先编译先调用)
当像一个类发送消息的时候 RunTime在调用消息发送机制寻找方法实现的时候,会判断这个类是否需要初始化 如果没有初始化 先判断这个父类是否需要初始化 如果需要初始化 就先初始化这个父类 然周再调用自己的+initialize
先调用父类的+initialize方法 再调用自己的+initialize,而且都是走的消息发送机制
4.+load +initialize方法的区别是什么? 他们在Category中的调用顺序?以及出现继承时他们之间的调用过程?
+load 和 +initialize 方法最大的区别是 在系统主动调用的时候一个是通过函数指针主动调用 +initialize是通过objc_msgsend消息发送机制调用的
所以如果子类没有实现+initialize 会调用父类的+initialize 可能会导致父类的+initialize调用多次 如果分类实现了+initialize 就会调用分类的+initialize
+load 不论继承 分类 或者本类实现 在系统主动调用的情况下(在运行时加载类 和 分类的load方法)都会调用自己的 load方法
调用时刻也不同 +load是RunTime加载类和分类的时候调用 只会调用一次 +initialize是类接收到第一次消息时调用 每个类只会initialize一次,但是父类的+initialize可能会调用多次
在Category中的调用顺序
+load
1.先调用类的load(先编译 先调用) 调用子类的load 会先调用父类的load
2.再调用分类的load(先编译 先调用)
+initialize
先初始化父类 再初始化子类(初始化子类的时候可能最终调用的是父类的+initialize)
5.Category能否添加成员变量?如果可以,如何给Category添加成员变量?
分类不可以直接添加成员变量 但是可以间接实现添加成员变量 但是只能生成一个下划线成员变量 没有setter和getter方法。所以分类里的添加的成员变量如果要正常使用,我们需要自己实现getter和setter方法 通过 objc_setAssociatedObject(<#id _Nonnull object#>, <#const void * _Nonnull key#>, <#id _Nullable value#>, <#objc_AssociationPolicy policy#>) 来实现setter方法 通过objc_getAssociatedObject(<#id _Nonnull object#>, <#const void * _Nonnull key#>) 来实现getter方法 这个过程叫做关联对象
在其内部是这样设计实现的
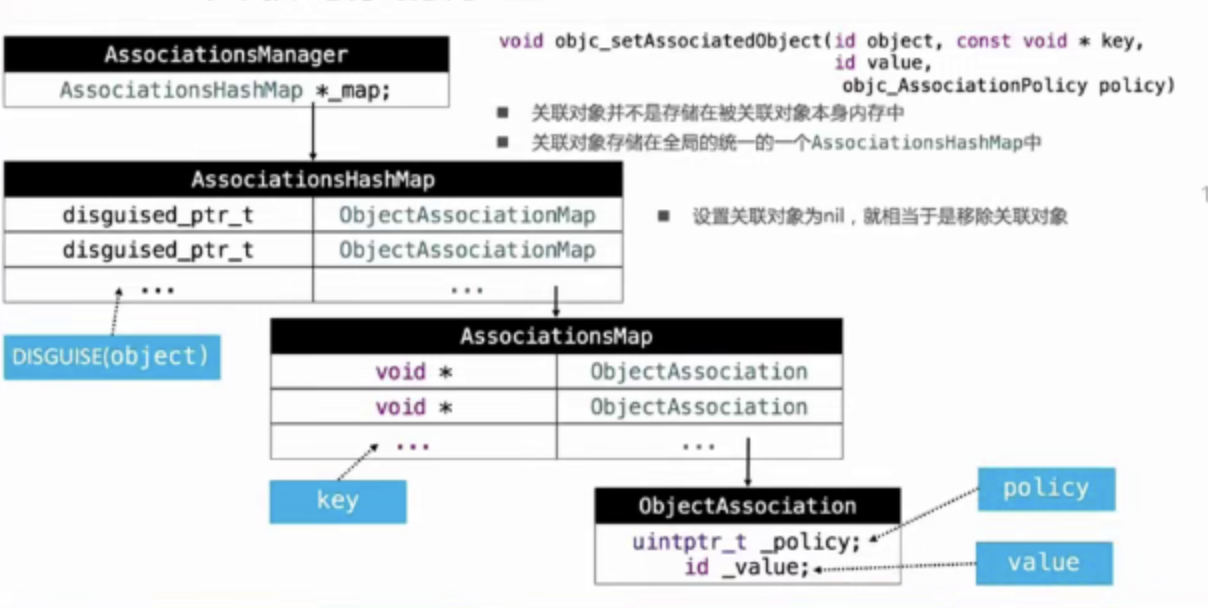
关联对象并不是存储在对象本身的内存中 而是存储在全局统一的一个AssociationsManager中. 如果设置关联对象为nil就相当于移除关联对象