Map和List
map的values方法
map集合是一个关联数组,它包含两组值:一组是key组成的集合,因为map集合的key不允许重复,且map不会保存key加入的顺序,因此这些key可以组成一个Set集合;另一组是value组成的集合,因为value完全可以重复,且map可以根据key来获取对应的value,所以这些value可以组成一个List集合。
HashMap的values方法的源码:
public Collection<V> values() { //获取values实例变量 Collection<V> vs = values; //如果vs == null,将返回new values()对象 return (vs != null ? vs : (values = new Values())); }
private final class Values extends AbstractCollection<V> { public Iterator<V> iterator() { return newValueIterator(); } public int size() { return size; } public boolean contains(Object o) { return containsValue(o); } public void clear() { HashMap.this.clear(); } }
Iterator<V> newValueIterator() { return new ValueIterator(); }
private final class ValueIterator extends HashIterator<V> { public V next() { return nextEntry().value; } }综上HashMap的values()方法表面上返回了一个Values对象,但这个对象不能添加元素。它的主要功能是用于遍历HashMap里的所有value。而遍历主要依赖于HashIterator的nextEntry()方法实现。每个Entry都持有一个引用变量指向下一个Entry.
TreeMap的 values方法的源码:
public Collection<V> values() { Collection<V> vs = values; return (vs != null) ? vs : (values = new Values()); }
class Values extends AbstractCollection<V> { public Iterator<V> iterator() { //以TreeMap中最小节点创建一个ValueIterator return new ValueIterator(getFirstEntry()); } public int size() { //调用外部类的size()实例方法的返回值作为返回值 return TreeMap.this.size(); } public boolean contains(Object o) { //调用外部类的containsValue(o)实例方法的返回值作为返回值 return TreeMap.this.containsValue(o); } public boolean remove(Object o) { //从TreeMap中最小的节点开始搜索,不断搜索下一个节点 for (Entry<K,V> e = getFirstEntry(); e != null; e = successor(e)) { if (valEquals(e.getValue(), o)) {//如果找到指定节点 deleteEntry(e);//执行删除 return true; } } return false; } public void clear() { //调用外部类的clear()实例方法来清空该集合 TreeMap.this.clear(); } }
getFirstEntry:获取TreeMap底层“红黑树”最左边的“叶子节点”,也就是“红黑树”中最小的节点,即TreeMap中第一个节点。
final Entry<K,V> getFirstEntry() { Entry<K,V> p = root; if (p != null) //不断搜索左子节点,直到p成为最左子树的叶子节点 while (p.left != null) p = p.left; return p; }
successor:获取TreeMap中指定Entry(t)的下一个节点,也就是红黑树中大于t节点的最小节点。
static <K,V> TreeMap.Entry<K,V> successor(Entry<K,V> t) { if (t == null) return null; //如果其右子树存在,搜索右子树中最小的节点(也就是右子树最左的叶子节点) else if (t.right != null) { //先获取其右子节点 Entry<K,V> p = t.right; //不断搜索左子节点,直到找到最左的叶子节点 while (p.left != null) p = p.left; return p; //如果右子树不存在 } else { Entry<K,V> p = t.parent; Entry<K,V> ch = t; //只要父节点存在,且ch是父节点的右节点 //表明ch大于其父节点,循环一直继续 //直到父节点为null,或者ch变成父节点的子节点——此时父节点大于被搜索的节点 while (p != null && ch == p.right) { ch = p; p = p.parent; } return p; } }归纳:不管是HashMap还是TreeMap,他们的values()方法都可以返回其所有value组成的Collection集合——通常理解,这个Collection集合应该是一个List集合,因为map的多个value允许重复。但这两个map对象values()方法返回的是一个不存储元素的Collection集合。当程序遍历Collection集合时,实际上就是遍历Map对象的value
Map和List的关系
从底层上看,Set和Map很相似;从用法上看,Map和List也有很大的相似。
1)Map接口提供了get(K key)方法允许Map对象根据key来获得value
2)List接口提供了get(int index)方法允许List对象根据元素索引来取得value
可以说List相当于所有key都是int类型的Map。Map和List只是用法上有些许相似之处,在底层实现上并没有太大的相似之处。、
ArrayList和LinkedList
List的实现主要有三个类:ArrayList,Vector,LinkedList

其中Vector有一个子类Stack,这个Stack子类仅在Vector父类的基础上增加了5个方法,这5个方法将Vector扩展成一个Stack,本质上,Stack依然是一个Vector。
Stack源码:
public class Stack<E> extends Vector<E> { /** * 无参构造器 */ public Stack() { } /** * 实现向栈定添加元素的方法 */ public E push(E item) { addElement(item);//调用父类的方法来添加元素 return item; } /** * 实现出栈的方法(位于栈顶的方法将被弹出栈) */ public synchronized E pop() { E obj; int len = size(); obj = peek(); removeElementAt(len - 1); return obj; } /** * 取出最后一个元素,但不会弹出栈 */ public synchronized E peek() { int len = size(); //如果不包含任何元素,直接抛出异常 if (len == 0) throw new EmptyStackException(); return elementAt(len - 1); } //集合不包含任何元素就是空栈 public boolean empty() { return size() == 0; } public synchronized int search(Object o) { //获取o在集合中的位置 int i = lastIndexOf(o); if (i >= 0) { //用集合长度减去o在集合中的位置,就得到该元素到栈顶的距离。 return size() - i; } return -1; } private static final long serialVersionUID = 1224463164541339165L; }
从源码可以看出Stack新增的5个方法中有3个使用了synchronized修饰——那些需要操作集合元素的方法都被添加了synchronized修饰,也就是说Stack是一个线程安全的类,这也是为了让Stack和Vector保持一致——Vector也是一个线程线圈类。
如今不在推荐使用Stack类,而是使用Deque实现类。在无需保证线程安全的情况下,完全可以使用ArrayDeque代替Stack。
Deque接口代表双端队列这种数据结构,即具有队列先进先出的性质,也具有栈的性质。即是队列也是栈。
ArrayList和ArrayDeque底层都是基于Java数组实现的,只是提供的方法不同而已。
Vector和ArrayList
Vector和ArrayList都实现了List接口,底层都是基于Java数组存储集合元素。
ArrayList源码:
//采用elementData数组保存集合元素 private transient Object[] elementData;
Vector源码:
//采用elementData元素保存集合 protected Object[] elementData;
ArrayList使用了transient修饰,保证了系统序列化ArrayList对象不会直接序列化elementData数组,而是通过writeObject和readObject实现定制序列化。从序列化的角度看,ArrayList的实现比Vector安全。
除此之外,Vector其实就是ArrayList的线程安全版,ArrayList和Vector大部分实现方法都相同,只是Vector方法增加了synchronized修饰。
下面看看两者的一些源码:
ArrayList的add方法:
public void add(int index, E element) { rangeCheckForAdd(index); //保证ArrayList底层数组可以保存所有集合元素 ensureCapacityInternal(size + 1); // Increments modCount!! //将elementData数组中index位置之后的所有元素向后移动一位 //也就是将elementData数组中的index位置空出来 System.arraycopy(elementData, index, elementData, index + 1, size - index); //将新元素放进elementData数组的index位置 elementData[index] = element; size++; }
//如果添加位置大于集合长度或小于0,抛出异常 private void rangeCheckForAdd(int index) { if (index > size || index < 0) throw new IndexOutOfBoundsException(outOfBoundsMsg(index)); }
Vector的add方法:
public void add(int index, E element) { insertElementAt(element, index); }
public synchronized void insertElementAt(E obj, int index) { modCount++;//增加集合的修改次数 //如果添加位置大于集合长度抛出异常 if (index > elementCount) { throw new ArrayIndexOutOfBoundsException(index + " > " + elementCount); } //保证ArrayList底层数组可以保存所有集合 ensureCapacityHelper(elementCount + 1);
//将elementData数组中index位置之后的所有元素向后移动一位
//也就是将elementData数组中的index位置空出来
System.arraycopy(elementData, index, elementData, index + 1, elementCount - index); elementData[index] = obj;//将新元素放入elementData数组的index位置 elementCount++;}发现只是Vector的方法多了synchronized方法修饰。
ArrayList序列化实现比Vector序列化实现更加安全,因此Vector基本被ArrayList代替。Vector的唯一好处就是他是线程安全的。但是ArrayList也可以被包装成线程安全的。

ArrayList和LinkedList实现差异
List代表一种线性表的数据结构,
ArrayList则是一种顺序存储的线性表,底层采用数组保存每个集合元素,
LinkedList则是一种链式存储的线性表,本质是一个双向链表,但是它不仅实现了List接口还实现了Deque接口,也就是说LinkedList既可以当成双向链表来使用,也可以当成队列来使用,还可以当成栈来使用。(Deque代表双端队列,同时具有队列和栈的特性)。
从上可知:ArrayList底层采用数组保存集合元素,则ArrayList插入时需要完成以下两件事:
1)底层数组长度大于集合元素个数
2)插入位置之后的元素“整体搬家”向后一格
当删除ArrayList集合中指定位置元素时,程序也要进行“整体搬家”,而且还要将被删除的数组元素赋为null。
public E remove(int index) { //如果index大于或等于size,抛出异常 rangeCheck(index); modCount++; //保证index索引处的元素 E oldValue = elementData(index); //计算需要“整体搬家”的元素个数 int numMoved = size - index - 1; //当numMoved大于0时,开始搬家 if (numMoved > 0) System.arraycopy(elementData, index+1, elementData, index, numMoved); elementData[--size] = null; // 释放被删除的元素,以免GC回收该元素 return oldValue; }
对于ArrayList而言,添加、删除都需要”整体搬家“,因此性能十分差
public E get(int index) { rangeCheck(index); checkForComodification(); return ArrayList.this.elementData(offset + index); }
E elementData(int index) { return (E) elementData[index]; }当时获取元素的性能和数组几乎相同,非常快。
LinkedList本质上是一个双向链表:
添加节点的方式:
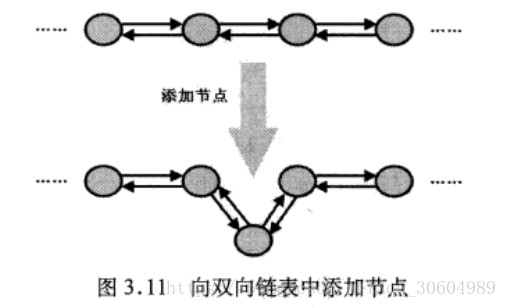
使用如下内部类来保存每个集合元素:
private static class Node<E> { E item;//集合元素 Node<E> next;//保存指向下一个链表节点的引用 Node<E> prev;//保存指向上一个链表节点的引用 //普通构造器 Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }
在指定位置插入新节点:
public void add(int index, E element) { checkPositionIndex(index); //如果index == size直接在header之前插入新节点 if (index == size) linkLast(element); else//否则在index索引处的节点之前插入新节点 linkBefore(element, node(index)); }
void linkLast(E e) { final Node<E> l = last; final Node<E> newNode = new Node<>(l, e, null); last = newNode; if (l == null) first = newNode; else l.next = newNode; size++; modCount++; }
在指定节点(succ)前添加一个新的节点 void linkBefore(E e, Node<E> succ) { // assert succ != null; //创建一个新节点,新节点的下一个节点指向succ,上一个节点指向succ的上一个节点 final Node<E> pred = succ.prev; final Node<E> newNode = new Node<>(pred, e, succ); //让succ的上一个节点向后指向新节点 succ.prev = newNode; if (pred == null) first = newNode; else pred.next = newNode; size++; modCount++; }
获取指定索引处的节点 Node<E> node(int index) { // assert isElementIndex(index); //如果index<size/2 if (index < (size >> 1)) { Node<E> x = first;//从链表的头部开始搜索 for (int i = 0; i < index; i++) x = x.next; return x; } else {//如果index>size/2 Node<E> x = last;//从链表的尾部开始搜索 for (int i = size - 1; i > index; i--) x = x.prev; return x; } }
LinkedList的get方法只是对上面的node方法进行封装:
public E get(int index) { checkElementIndex(index); return node(index).item; }
无论如何LinkedList为了获取指定索引处的元素都是比较麻烦的,系统开销也会比较大。
但是简单的插入操作就比较简单,只要修改了几个节点里的prev,next引用的值就可以了。
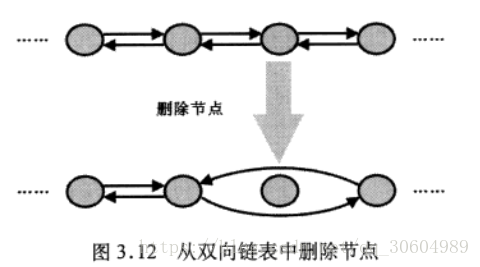
删除节点也必须先通过node方法找到索引处的节点,然后修改前一个节点的next引用和后一个节点的prev引用:
public E remove(int index) { checkElementIndex(index); return unlink(node(index)); }
E unlink(Node<E> x) { // assert x != null; final E element = x.item;//先保存x节点的元素 final Node<E> next = x.next; final Node<E> prev = x.prev; //将被删除的元素的两个引用、元素都赋值为null,以便垃圾回收 if (prev == null) { first = next; } else { prev.next = next; x.prev = null; } if (next == null) { last = prev; } else { next.prev = prev; x.next = null; } x.item = null; size--; modCount++; return element; }
ArrayList和LinkedList性能分析
ArrayList性能总体上优于LinkedList。
当程序需要通过get(int index)方法获取List集合指定索引处的元素时,ArrayList性能大大优于LinkedList,因为ArrayList底层是数组来保存集合元素,所以调用get方法获取指定索引处的元素时,底层实际上调用elementData[index]来返回该元素,因此性能非常好。
当程序调用add(int index,Object obj)向List集合中添加元素时,ArrayList必须对底层数组进行“整体搬家”。如果数组不够长,还要重新创建一个长度为原来1.5倍的数组,再由垃圾回收机制回收原来的数组,因此系统开销比较大;对于LinkedList而言,它的主要系统开销集中在node(int index )方法上,必须一个一个的搜索过去,直到找到index元素,再在此元素之前插入新元素。即便如此,执行该方法时LinkedList性能依然优于ArrayList
Iterator迭代器
Iterator迭代器是一个接口,专门用于迭代各种Collection集合,包括Set和List
List和Set在实现Iterator的差异——>导致删除集合元素的不同表现