JDK1.8源码分析之LinkedList
前言
LinkedList和ArrayList一样实现了List接口,只是ArrayList是List接口大小可变数组的实现,LinkedList是基于链表的实现,因为如此,使得LinkedList在插入和删除的时候更优于ArrayList,而随机访问则比ArrayList逊色。
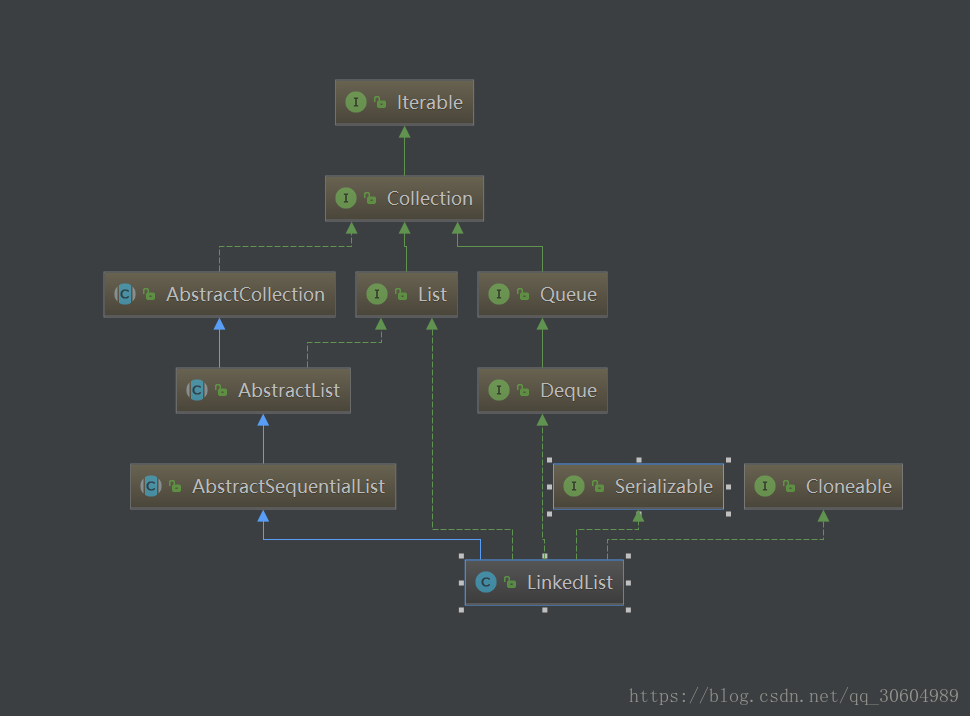
构造图如下:
蓝色线条:继承
绿色线条:接口实现
正文
因为LinkedList是基于链表的List接口的实现,因此先来说说关于链表。
1、链表的概念
链表是由一系列非连续的节点组成的存储结构,简单分为单向链表和双向链表,而单/双链表又可以分为循环链表和非循环链表下面进行简单的说明。
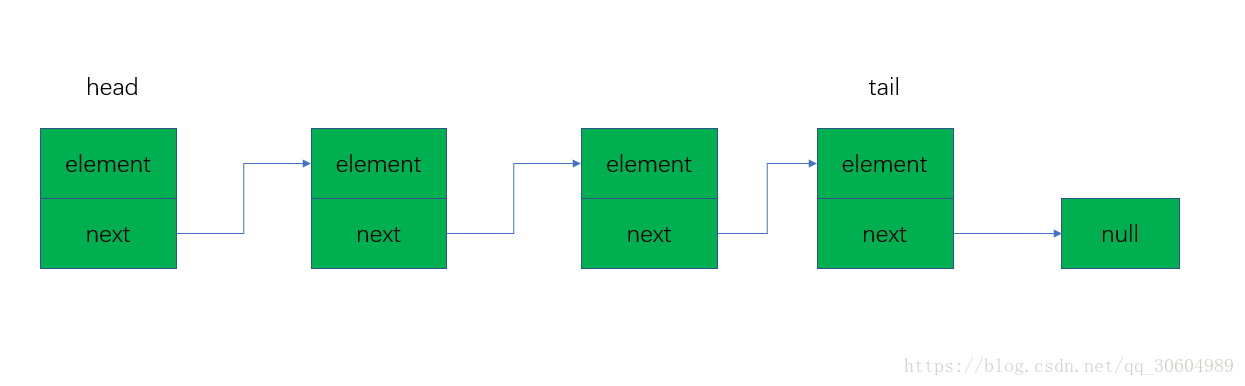
1.1 单向链表
单向链表就是通过每个节点的指针指向下一个节点从而链接起来的结构,最后一个节点的next指向null。
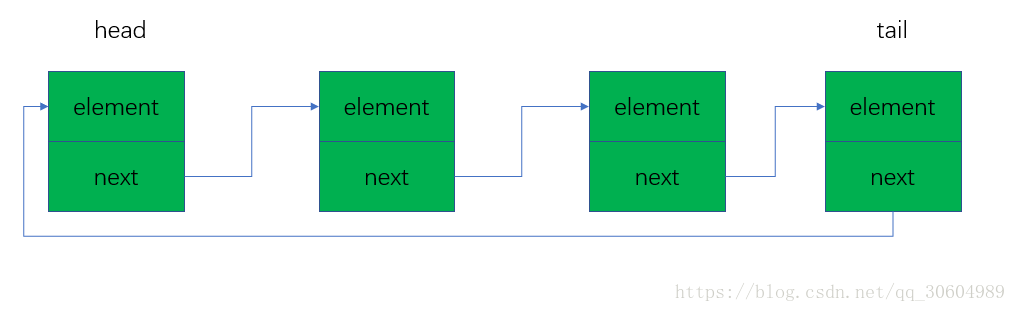
1.2 单向循环链表
单向循环链表和单向链表的不同是,最后一个节点的next不是指向null,而是指向head节点,形成一个“环”。
1.3 双向链表
双向链表包含两个指针,pre指向前一个节点,next指向后一个节点,第一个节点的pre和最后一个节点的next都指向null。

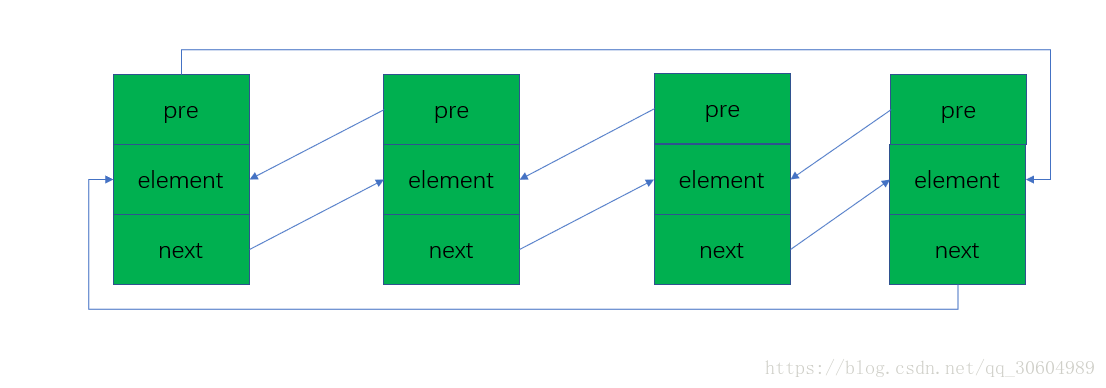
1.4 双向循环链表
双向循环链表和双向链表的不同在于,第一个节点的pre指向最后一个节点,最后一个节点的next指向第一个节点,也形成一个“环”。而LinkedList就是基于双向循环链表设计的。
LinkedList的定义
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable
LinkedList是一个继承于AbstractSequentialList的双向循环链表。它也可以被当做堆栈、队列、双端队列进行操作。
LinkedList实现了List接口,它能进行队列操作。
LInkedList实现了Deque接口,能将LInkedList当做双端队列使用。
LinkedList实现了Cloneable接口,即覆盖了函数clone(),能克隆。
LinkedList实现了java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
LinkedList是非同步的(不是线程安全的)
LinkedList的属性
//表示LinkedList元素的数量 transient int size = 0; /** * Pointer to first node.头结点 */ transient Node<E> first; /** * Pointer to last node.尾节点 */ transient Node<E> last; /** * 空构造器 */ public LinkedList() { } /** * 构造一个包含指定 collection 中的元素的列表, * 这些元素按其 collection 的迭代器返回的顺序排列 * */ public LinkedList(Collection<? extends E> c) { this(); addAll(c); }
内部类:Node其实就是实际的节点用于存放元素的地方
private static class Node<E> { E item;//数据域 Node<E> next;//后继 Node<E> prev;//前驱 //构造函数赋值 Node(Node<E> prev, E element, Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }
API方法摘要


增加
/** * 在list的头部增加一个元素e */ public void addFirst(E e) { linkFirst(e); } /** * 在list的尾部增加一个元素e */ public void addLast(E e) { linkLast(e); }
/** * 将e添加为第一个元素 */ private void linkFirst(E e) { final Node<E> f = first; final Node<E> newNode = new Node<>(null, e, f); first = newNode; if (f == null) last = newNode; else f.prev = newNode; size++; modCount++; } /** * 链接e作为最后一个元素 */ void linkLast(E e) { final Node<E> l = last;//保存尾节点,l为final类型不可更改 //新生成节点的前驱为l,后继为null final Node<E> newNode = new Node<>(l, e, null); last = newNode;//重新给尾节点赋值 if (l == null)//如果尾节点为空 first = newNode;//赋值头节点 else//尾节点不为空 l.next = newNode;//尾节点的后继为新生成的节点 size++;//大小加1 modCount++;//结构性修改 }
addAll函数有两个重载方法:addAll(Collection<? extends E>)型和addAll(int, Collection<? extends E>)型,主要是用后者
public boolean addAll(Collection<? extends E> c) { return addAll(size, c); } /** * 在指定位置添加一个集合 */ public boolean addAll(int index, Collection<? extends E> c) { checkPositionIndex(index);//检查插入的位置是否合法 //将集合转化为数组 Object[] a = c.toArray(); int numNew = a.length;//保存集合大小 if (numNew == 0)//集合为空直接返回 return false; Node<E> pred, succ;//前驱、后继 if (index == size) {//如果插入的位置为链表末尾,则后继为null,前驱为尾节点 succ = null; pred = last; } else {//插入的位置为其他某个位置 succ = node(index);//寻找该节点 pred = succ.prev;//保存该节点的前驱 } for (Object o : a) {//遍历数组 @SuppressWarnings("unchecked") E e = (E) o;//向下转型 //生成一个新的节点 Node<E> newNode = new Node<>(pred, e, null); if (pred == null)//在第一个元素之前插入(索引为0的节点) first = newNode; else pred.next = newNode; pred = newNode; } if (succ == null) {//表示在最后一个元素之后插入 last = pred; } else { pred.next = succ; succ.prev = pred; } size += numNew;//修改实际元素个数 modCount++;//结构性修改加1 return true; }
传入的index表示在索引为index的元素前面插入(也就是index+1这个元素前面)
上面的函数和查找还会调用到node函数:
Node<E> node(int index) { // assert isElementIndex(index); //判断插入的位置是链表的前半段还是后半段 if (index < (size >> 1)) {//前半段 Node<E> x = first; for (int i = 0; i < index; i++)//从头节点开始正向遍历 x = x.next; return x;//返回该节点 } else {//插入位置在后半段 Node<E> x = last; for (int i = size - 1; i > index; i--)//从尾节点开始向前遍历 x = x.prev; return x;//返回该节点 } }在根据索引查找结点时,会有一个小优化,结点在前半段则从头开始遍历,在后半段则从尾开始遍历,这样就保证了只需要遍历最多一半结点就可以找到指定索引的结点。
删除
/** * 删除某个节点 */ public boolean remove(Object o) { if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); return true; } } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { unlink(x); return true; } } } return false; }
E unlink(Node<E> x) { // assert x != null; final E element = x.item;//保存节点的元素 final Node<E> next = x.next;//保存后继 final Node<E> prev = x.prev;//保存前驱 if (prev == null) {//前驱为空表示删除的是头结点 first = next;//重新赋值头结点 } else {//删除的不为头结点 prev.next = next;//赋值前驱节点的后继 x.prev = null;//节点的前驱为空,切断节点的前驱指针 } if (next == null) {//后继为空,表示删除的节点为尾节点 last = prev;//重新赋值尾节点 } else {//删除的节点不为尾节点 next.prev = prev;//重新赋值后继节点的前驱 x.next = null;//节点的后继为空,切断节点的后继指针 } x.item = null;//节点赋值为空,供垃圾回收 size--;//减少元素的实际个数 modCount++;//结构性修改加1 return element;//返回节点的旧元素 }
修改
/** * 修改指定位置的元素 */ public E set(int index, E element) { checkElementIndex(index);//越界检查 Node<E> x = node(index);//找到要替换的元素 E oldVal = x.item;// 取出该节点的元素,供返回使用 x.item = element;// 用新元素替换旧元素 return oldVal;//返回 }
查询
/** * 查询 */ public E get(int index) { checkElementIndex(index); return node(index).item; }
是否包含
/** * 判断是否包含某个元素 */ public boolean contains(Object o) { return indexOf(o) != -1; }
/** * 从前向后查找,返回“值为对象(o)的节点对应的索引”,不存在就返回-1 */ public int indexOf(Object o) { int index = 0; if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) return index; index++; } } else { for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) return index; index++; } } return -1; } /** * 从后向前查找,返回“值为对象(o)的节点对应的索引”,不存在就返回-1 */ public int lastIndexOf(Object o) { int index = size; if (o == null) { for (Node<E> x = last; x != null; x = x.prev) { index--; if (x.item == null) return index; } } else { for (Node<E> x = last; x != null; x = x.prev) { index--; if (o.equals(x.item)) return index; } } return -1; }
判断容量
/** * 返回list元素的数量 */ public int size() { return size; }
LinkedList实现双端队列
/** * Adds the specified element as the tail (last element) of this list. * * @param e the element to add * @return {@code true} (as specified by {@link Queue#offer}) * @since 1.5 */ public boolean offer(E e) { return add(e); } // Deque operations /** * Inserts the specified element at the front of this list. * * @param e the element to insert * @return {@code true} (as specified by {@link Deque#offerFirst}) * @since 1.6 */ public boolean offerFirst(E e) { addFirst(e); return true; } /** * Inserts the specified element at the end of this list. * * @param e the element to insert * @return {@code true} (as specified by {@link Deque#offerLast}) * @since 1.6 */ public boolean offerLast(E e) { addLast(e); return true; } /** * Retrieves, but does not remove, the first element of this list, * or returns {@code null} if this list is empty. * * @return the first element of this list, or {@code null} * if this list is empty * @since 1.6 */ public E peekFirst() { final Node<E> f = first; return (f == null) ? null : f.item; } /** * Retrieves, but does not remove, the last element of this list, * or returns {@code null} if this list is empty. * * @return the last element of this list, or {@code null} * if this list is empty * @since 1.6 */ public E peekLast() { final Node<E> l = last; return (l == null) ? null : l.item; } /** * Retrieves and removes the first element of this list, * or returns {@code null} if this list is empty. * * @return the first element of this list, or {@code null} if * this list is empty * @since 1.6 */ public E pollFirst() { final Node<E> f = first; return (f == null) ? null : unlinkFirst(f); } /** * Retrieves and removes the last element of this list, * or returns {@code null} if this list is empty. * * @return the last element of this list, or {@code null} if * this list is empty * @since 1.6 */ public E pollLast() { final Node<E> l = last; return (l == null) ? null : unlinkLast(l); } /** * Pushes an element onto the stack represented by this list. In other * words, inserts the element at the front of this list. * * <p>This method is equivalent to {@link #addFirst}. * * @param e the element to push * @since 1.6 */ public void push(E e) { addFirst(e); } /** * Pops an element from the stack represented by this list. In other * words, removes and returns the first element of this list. * * <p>This method is equivalent to {@link #removeFirst()}. * * @return the element at the front of this list (which is the top * of the stack represented by this list) * @throws NoSuchElementException if this list is empty * @since 1.6 */ public E pop() { return removeFirst(); }
小结
1、LinkedList实际上是通过双向链表去实现的,包含了一个非常重要的内部类Node,他是双向链表节点所对应的数据结构,包含的属性有:当前节点所包含的值,上一个节点,下一个节点。
2、从LinkedList实现方式可以发现不存在容量不足的问题
3、LinkedList的克隆函数即是将全部元素克隆到新的LinkedList对象中。
4、LinkedList实现了java.io.Serializable。当写入到输出流的时候,先写“容量”,再依次写“每个节点保护的值”;当读出到输入流时,先读取“容量”,再依次读取“每个元素”。
5、由于LinkedList实现了Deque,而Deque接口定义了在双端队列两端访问元素的方法。提供插入、移除和检查元素的方法。每种方法都存在两种形式:一种形式在失败时抛出异常,另一种形式返回一个特殊值(null或false,具体取决于操作)
LinkedList和ArrayList迭代效率
结论:ArrayList使用for循环遍历比较快,LinkedList使用foreach遍历比较快。
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.SerializableArrayList实现了RandomAccess接口,LinkedList没有。
关于RandomAccess

ArrayList和LInkedList比较
1、顺序插入速度ArrayList会比较快,因为ArrayList是基于数组实现的,数组是事先new好的,只需要wang
往指定位置塞一个数据就好了;LinkedList则不同,每次顺序插入的时候LinkedList将会new一个对象出来,如果对象比较大,那么new的时间会很长,再加上一些赋值操作,所以顺序插入LinkedList必然慢于ArrayList。
2、因为LinkedList里面不仅维护了待插入的元素,还维护了Node的前驱和后继,如果一个LinkedList的Node很多,那么将会比ArrayList更加耗费内存。
3、数据遍历,使用给子的遍历效率最高的方式,ArrayList的效率比LinkedList的高。
4、关于LinkedList做插入和删除更快,这种说法其实不准确:
1)LinkedList做插入和删除的时候,慢在寻址,快在只需要改变前后Node的引用地址。
2)ArrayList做插入和删除的时候,慢在数组元素的批量copy,快在寻址。
所以,如果待插入的元素是在数据结构的前半段尤其是非常靠前的位置时,LinkedList的效率将大大快过ArrayList,因为ArrayList将批量copy大量的元素;越往后,对于LinkedList来说,因为他是双向链表,所以在第2个元素后面插入一个数据和在倒数第2个元素后插入一个元素在效率上基本没有差别,但是ArrayList由于需要批量copy元素越来越少,操作速度必然追上乃至超过LinkedList。
ArrayList底层数组扩容是一个既消耗时间又消耗空间的操作。
原文: http://tengj.top/2016/04/15/javajh3hashmap/ 作者: 嘟嘟MD