Java中的String是一个非常特殊的类,使它特殊的一个主要原因是:String是不可变的(immutable)。
String的不可变性是Java安全机制和线程安全的基石,没了它Java将变的不堪一击。
但不可变性的代价是昂贵的,当你试图“改变”一个String时,你实际上是在创建一个新的String,而原来的那个String在大多数情况下将会成 为垃圾(garbage)。多亏有了Java的垃圾自动回收机制,开发者不必在这些String垃圾上操太多心。但如果你完全忽略这些垃圾的存在,甚至肆 意乱用String的api,你的程序无疑将遭受大量GC(垃圾回收)活动的困扰。
在JDK的发展史中,人们做过一些努力去改善String的垃圾创建开销。JDK1.0中加入StringBuffer,JDK1.5中加入 StringBuilder。StringBuffer和StringBuilder在功能上是完全相同的,为一的不同点在于StringBuffer是 线程安全的,而StringBuilder不是。绝大多数的String连接操作发生在一个方法调用中,也就是说是单一线程的工作环境,所以线程安全在这 里是绝对多余的。所以JDK给开发者的建议是当你要做String连接操作时,请使用StringBuffer或StringBuilder,当你确定连 接操作只发生在单一线程环境下时,使用StringBuilder而不是StringBuffer。在大多数情况下遵守这一建议与直接使用 String.concat()相比能够大幅提高性能,但实际环境中某些情况远比这复杂。这一建议并不能给你最佳的性能收益!今天我们要深入的探讨一下 String连接操作的性能问题,希望能帮助大家彻底理解这一问题。
首先,需要辟谣,有些人说SB(StringBuffer和StringBuilder)总是比String.concat()有更好的性能。这一说法是不准确的!在特定条件下String.concat()要胜过SB。我们来通过一个例子证明这一点。
任务:
连接两个String,
String b = "abcdefghijklmnopqr"; //length=18
说明:
我们将要来分析一下不同连接方案的垃圾生产情况。讨论中我们将忽略由输入参数引起的垃圾,因为他们不是由连接代码创建的。另外我们只计算String内部的char[],因为除了这个字符数组String的其它域都非常小,完全可以忽略他们对GC的影响。
方案1:
使用String.concat()
代码:
这行代码简单到不能再简单了,不过还是让我们来看看Sun JDK java.lang.String的源代码,搞清楚这个调用究竟是怎样进行的。
Sun JDK java.lang.String的源代码片段:
2 int otherLen = str.length();
3 if (otherLen == 0) {
4 return this;
5 }
6 char buf[] = new char[count + otherLen];
7 getChars(0, count, buf, 0);
8 str.getChars(0, otherLen, buf, count);
9 return new String(0, count + otherLen, buf);
10 }
11
12 String(int offset, int count, char value[]) {
13 this.value = value;
14 this.offset = offset;
15 this.count = count;
16 }
这段代码首先创建一个新的char[],数组长度为a.length() + b.length(),然后分别将a和b的内容拷贝到新数组中,最后使用这个数组创建一个新的String对象。这里我们要特殊注意一下使用的构造函数, 这个构造函数只有package访问权限,它直接使用传入的char[]作为新生成的String的内部字符数组,而没有做任何拷贝保护。这个构造函数必 须是package级别的访问权限,否则你就能用它创建出一个可变的String对象(在构造完String后修改传入的char[])。JDK在 java.lang中的代码保证不会在调用这一构造函数后再修改传入的数组,加上java的安全机制不允许第三方代码加入java.lang包(你可以尝 试将自己的类放入java.lang包,此类将无法成功加载),所以String的不可变性不会被破坏。
整个过程我们没有创建任何垃圾对象(我们有言在先,a和b是传入参数,不是连接代码创建的,所以即使他们变成垃圾我们也不去计算),所以一切良好!
方案2:
使用SB.append(), 这里我使用StringBuilder来进行分析,对于StringBuffer也是完全一样的。
代码:
这行代码明显比String.concat()方案的代码复杂,但它的性能如何呢?让我们分4步来分析它new StringBuilder(),append(a),append(b)和toString().
1)new StringBuilder().
让我们来看看StringBuilder的源代码:
2 super(16);
3 }
4
5 AbstractStringBuilder(int capacity) {
6 value = new char[capacity];
7 }
它创建了一个大小为16的char[],目前为止还没有创建任何垃圾对象。
2)append(a).
继续看源代码:
2 super.append(str);
3 return this;
4 }
5 public AbstractStringBuilder append(String str) {
6 if (str == null) str = "null";
7 int len = str.length();
8 if (len == 0) return this;
9 int newCount = count + len;
10 if (newCount > value.length)
11 expandCapacity(newCount);
12 str.getChars(0, len, value, count);
13 count = newCount;
14 return this;
15 }
16 void expandCapacity(int minimumCapacity) {
17 int newCapacity = (value.length + 1) * 2;
18 if (newCapacity < 0) {
19 newCapacity = Integer.MAX_VALUE;
20 } else if (minimumCapacity > newCapacity) {
21 newCapacity = minimumCapacity;
22 }
23 value = Arrays.copyOf(value, newCapacity);
24 }
这段代码首先确保SB的内部char[]有足够的剩余空间,这导致创建了一个新的大小为34的char[],而之前的大小为16的char[]成为垃圾对象。标记点1,我们创建了第一个垃圾对象,大小为16个char。
3)append(b).
相同的逻辑,首先确保内部char[]有足够的剩余空间,这导致创建了一个新的大小为70的char[],而之前的大小为34的char[]成为垃圾对象。标记点2,我们创建了第二个垃圾对象,大小为34个char。
4)toString()
看源代码:
2 // Create a copy, don't share the array
3 return new String(value, 0, count);
4 }
5 public String(char value[], int offset, int count) {
6 if (offset < 0) {
7 throw new StringIndexOutOfBoundsException(offset);
8 }
9 if (count < 0) {
10 throw new StringIndexOutOfBoundsException(count);
11 }
12 // Note: offset or count might be near -1>>>1.
13 if (offset > value.length - count) {
14 throw new StringIndexOutOfBoundsException(offset + count);
15 }
16 this.offset = 0;
17 this.count = count;
18 this.value = Arrays.copyOfRange(value, offset, offset+count);
19 }
要重点注意一下这次的构造函数,它有public访问权限,所以它必须做拷贝保护,不然就有可能破坏String的不可变性。但这又创建了一个垃圾对象。标记点3,我们创建了第三个垃圾对象,大小为70个char。
因此我们一共创建了3个垃圾对象,总大小为16+34+70=120个char! Java使用Unicode-16编码,这就意味着240byte的垃圾!
有一件事情能够改善SB的性能,把代码改为:
自己算一下吧,这次我们只创建了1个垃圾对象,大小为17+18=35个char,还是不怎么样,不是吗?
和String.concat()比起来SB创建了“许多”垃圾(任何比0大的数和0比起来都是无穷大!),而且相信你也注意到了,SB比String.concat()有更多的方法调用(栈操作可不是免费的)。
进一步的分析可以发现(自己分析吧),当你连接少于4个String时(不含4),String.concat()要比SB高效的多。
所以当你要连接多于3个String时(不含3),我们应该使用SB,对吗?
不全对!
SB有一个天生固有的毛病,它使用一个可以动态增长的内部char[]来追加新的String,当你追加新String且SB达到了内部容量上限时,它就 必须扩大内部缓冲区。之后SB获得了一个更大的char[],而之前使用的char[]则变为了垃圾。如果我们能够精确的告诉SB最终的结果有多长,它就 可以省掉许多由无谓的增长产生的垃圾。但想要预测最终结果的长度并不容易!
与预测最终结果的长度相比,预测要连接String的数量就显得容易多了。我们可以先缓存要连接的String,然后在最后那一刻(调用 toString()的时候)计算最终结果的精确长度,用该长度创建一个SB来连接String,这样就能节省掉许多无谓的中间垃圾char[]。尽管有 时想要精确预测要连接的String数量也是很难的,我们可以效仿SB的做法,使用一个动态增长的String[]来缓存String,因为 String[]要比原来的char[]小的多(现实世界中的String普遍多余一个字符),所以一个动态增长的String[]要比动态增长的 char[]便宜的多。接下来我要介绍的StringBundler就是基于这一原理工作的。
2 _array = new String[_DEFAULT_ARRAY_CAPACITY]; // _DEFAULT_ARRAY_CAPACITY = 16
3 }
4
5 public StringBundler(int arrayCapacity) {
6 if (arrayCapacity <= 0) {
7 throw new IllegalArgumentException();
8 }
9 _array = new String[arrayCapacity];
10 }
11
第一个构造函数会创建一个默认数组大小为16的StringBundler,第二个构造函数允许你指定一个初始容量。每当你调用append()时,你并没有真正的执行String连接操作,而是将该String放置到缓存数组中。
2 if (s == null) {
3 s = StringPool.NULL;
4 }
5 if (_arrayIndex >= _array.length) {
6 expandCapacity();
7 }
8 _array[_arrayIndex++] = s;
9 return this;
10 }
11
如果你追加的String数量超过了缓存数组容量,内部的String[]会动态增长。
2 String[] newArray = new String[_array.length << 1];
3 System.arraycopy(_array, 0, newArray, 0, _array.length);
4 _array = newArray;
5 }
6
扩充一个String[]要比扩充char[]便宜的多。因为String[]比较小,而且增长的频度要远比原来的char[]低。
当你完成了全部追加后,调用toString()来获取最终结果。
2 if (_arrayIndex == 0) {
3 return StringPool.BLANK;
4 }
5 String s = null;
6 if (_arrayIndex <= 3) {
7 s = _array[0];
8 for (int i = 1; i < _arrayIndex; i++) {
9 s = s.concat(_array[i]);
10 }
11 }
12 else {
13 int length = 0;
14 for (int i = 0; i < _arrayIndex; i++) {
15 length += _array[i].length();
16 }
17 StringBuilder sb = new StringBuilder(length);
18 for (int i = 0; i < _arrayIndex; i++) {
19 sb.append(_array[i]);
20 }
21 s = sb.toString();
22 }
23 return s;
24 }
25
如果String的数量小于4(不含4),使用String.concat()来连接String,否则首先计算最终结果的长度,再用该长度来创建一个StringBuilder,最后使用这个StringBuilder来连接所有String。
我建议大家如果确定需要连接的String的数量小于4的,直接使用String.concat()来连接,虽然StringBundler能够帮你自动处理这一情况,但创建一个String[]和那些方法调用都是一些无谓的开销。
如果大家想进一步了解StringBundler,可以查看Liferay的JIRA连接,
http://support.liferay.com/browse/LPS-6072
好了,解释的已经够多了,是时候看看性能测试结果了,这些测试结果将向你展示StringBundler能为你带来多大的性能提升!
我们将要比较String.concat(),StringBuffer,StringBuilder,使用默认构造函数的StringBundler,使用给定初始化容量构造函数的StringBundler在连接String时的性能差异。
具体比较内容有两部分:
- 比较在完成相同次数连接操作情况下,各种连接方式的时间消耗。
- 比较在完成相同次数连接操作情况下,各种连接方式的垃圾生产量。
测试中使用连接String长度均为17,要连接的String的数量从72到2,对每个连接数量执行100,000次重复操作。
对于1,我只采用连接数量从40到2时产生的结果进行比较分析,因为JVM的预热会对前面的结果产生影响(JIT会占用大量的CPU时间)。
对于2,我采用全部结果进行比较分析,因为JVM的预热不会对总的垃圾生成数量产生影响(JIT虽然也会产生垃圾,但对于各个测试应是*似*等的,我只比较差值,所以该影响可以忽略)。
顺便说一下,我使用如下JVM参数来生成GC日志:
之所以采用SerialGC是为了消除多处理器对测试结果的影响。
下面的图片展示各种连接方式间时间消耗的不同: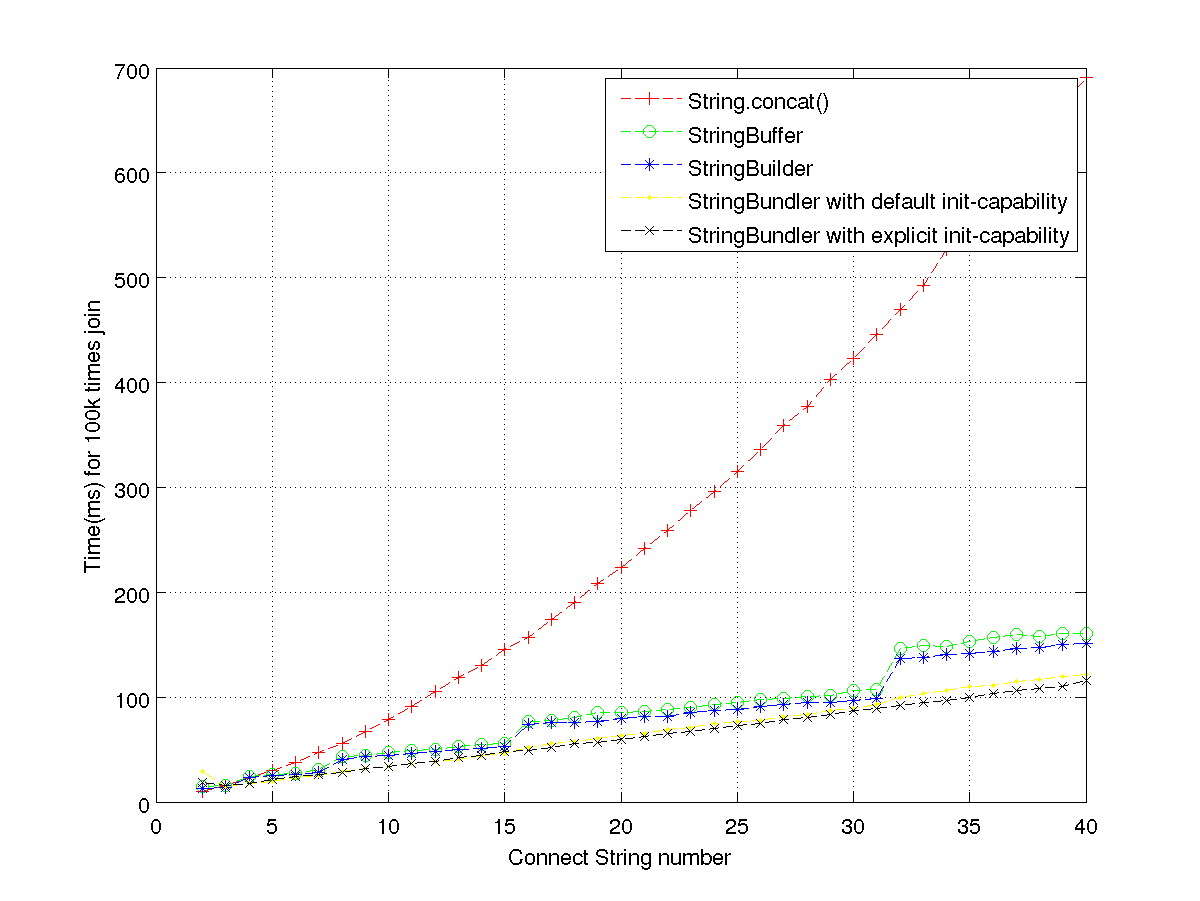
由图可以看出:
- 当连接2或3个String时,String.concat()的性能最好
- StringBundler整体上优于SB
- StringBuilder优于StringBuffer(由于节省了大量的同步操作)
对于3,在今后的blog中我还会更进一步的展开讨论,在我们自己的代码和JDK的代码中存在大量相似的情况,许多同步保护都是不必要的(至少在特定的情 况下是不必要的),比如JDK的IO包。如果我们能够绕过这些不必要的同步操作,我们就能大幅提高程序性能。
下面我们来分析以下GC日志(GC日志并不能100%准确的告诉你垃圾的数量,但它可以告诉你一个大致的趋势)
| String.concat() | 229858963K |
| StringBuffer | 34608271K |
| StringBuilder | 34608144K |
| StringBundler(默认构造函数) | 21214863K |
| StringBundler(明确指定String数量构造函数) | 19562434K |
由统计数字可以看出,StringBundler节省了大量的String垃圾。
最后我给大家留下4点建议:
- 当你连接2或3个String时,使用String.concat()。
- 如果你要连接多于3个String(不含3),并且你能够精确预测出最终结果的长度,使用StringBuilder/StringBuffer,并设定初始化容量。
- 如果你要连接多于3个String(不含3),并且你不能够精确预测出最终结果的长度,使用StringBundler。
- 如果你使用StringBundler,并且你能预测出要连接的String数量,使用指定初始化容量的构造函数。
如果你很懒!直接使用StringBundler吧,他在绝大多数情况下是最佳选择,在其他情况下虽然他不是最佳选择,但也能提供足够的性能保障。
这里我提供了一个消除了对Liferay其他类文件依赖的StringBundler供大家下载使用。