目录:
1.面试提问
2.完善采集端代码
3.唯一标识的问题
4.API的验证
1.面试会问到的问题:
# 1. 为啥要做CMDB?
# - 实现运维自动化, 而CMDB是实现运维自动化的基石
# - 之前公司统计资产的时候,使用Excel来统计, 为了年底资产审计方便,因此需要做CMDB
#
# 2. CMDB的架构以及你们公司采用的架构是啥?
# Agent
# ssh类
# saltstck
#
#
# 3. 你做这个项目的时候, 主要负责哪一块?
#
# - 数据的采集和发送
#
# a.数据的采集:
# - 高级的配置文件 (整合了自定制的配置文件和全局的配置文件)
# - 高内聚低耦合的思想, 实现了插件采集的可插拔式
#
# 参考了django的配置和django的中间件
#
# - 数据的二次清洗和加密
#
#
# - 数据的展示(图表部分)
#
# 4. 遇到了那些问题? 怎么解决的?
#
# - linux的命令不熟 -----> 找运维 或者 百度
# - 沟通问题, 和产品经理的沟通
# - 唯一标识的问题
# 几个人做的?做了多长时间?
#
# 刚开始:
#
# 1-2人做的客户端采集, 1人做API验证和数据清洗 ,1人做的数据的展示 (layui的 xadmin)
#
# 1-2个月的时间, 快速上线
#
#
# 后面:
#
# 1-2人做的客户端采集(代码的迭代), 1人做API验证和数据清洗,也负责用drf写接口 1个前端使用vue展示数据 (前后端分离的)
#
# 完善 1个月左右, 后面的时间就是不断的迭代, 维护, 完善整个项目的功能
5. 此项目花了多长时间? 几个人完成的?
3-4个人左右, 花的时间大概是 4个月:
1个月 : 调研, 排期, 开会选择方案
1-2个月 :项目快速上线 (不需要代码写的多么的好, 快快快) (2-3人 前后端不分离的项目)
1-2个月 :项目的完善 (代码的迭代,扩展性要高, 中间加一些产品经理提出的需求) (前后端分离的项目)
2.完善采集端代码
已经完成了采集数据,现在是要发送数据,一开始想到的是在启动文件中直接写代码
from lib.config.config import settings import json import requests from src.plugins import PluginsManger if __name__ == '__main__': if settings.MODE == 'agent': res = PluginsManger().execute() requests.post('http://127.0.0.1:8000', data=json.dumps(res)) else: res = PluginsManger().execute()
而逻辑代码是不能写在启动文件中的,所以在src创一个文件client.py
from lib.config.config import settings import json import requests from src.plugins import PluginsManger if settings.MODE == 'agent': res = PluginsManger().execute() requests.post('http://127.0.0.1:8000', data=json.dumps(res)) else: res = PluginsManger().execute()
但是以上又是面向过程的思想,所以要面向对象的思想
服务端的IP地址写在custom_settings。py里
import os BASEDIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) MODE = 'agent' SSH_USERNAME = 'root' SSH_PASSWORD = '123' SHH_PORT = 22 ### APIurl地址 API_URL = 'http://127.0.0.1:8000/getInfo/' DEBUG = True PLUGINS_DICT = { 'basic':'src.plugins.basic.Basic', 'board': 'src.plugins.board.Board', 'disk': 'src.plugins.disk.Disk', 'memory': 'src.plugins.memory.Memory', 'cpu':'src.plugins.cpu.Cpu', 'nic':'src.plugins.nic.Nic' }
client.py(先对agent采集模式进行测试)
from src.plugins import PluginsManger import json import requests from lib.config.config import settings class Agent(object): #收集数据并发送 def collectAndPost(self): res = PluginsManger().execute() for k,v in res.items(): print(k,v) requests.post(settings.API_URL, data=json.dumps(res))
start.py
from src.client import Agent if __name__ == '__main__': Agent().collectAndPost()
起一个django (我的是2.0版本) 服务端,应用项目是api
from django.contrib import admin from django.urls import path,re_path from api import views urlpatterns = [ path('admin/', admin.site.urls), re_path('getInfo/', views.getInfo), ]
将settings中drf注掉
# a. request.body中永远都是有数据的
#
#
# 当 Content-Type: application/x-www-form-urlencoded, request.POST中才会有值
# 当 Content-Type':"application/json" 这是采集端发送数据的头形式
views.py
from django.shortcuts import render,HttpResponse # Create your views here. def getInfo(request): print(request.body) return HttpResponse('ok')
shh, salt是通过服务端向db获取hostname主机名数据的,然后再朝客户端shh,salt返回数据库获取到的主机名列表
autoserver服务端
views.py
from django.shortcuts import render,HttpResponse # Create your views here. def getInfo(request): if request.method == 'POST': 发送采集数据的话就是post请求 print(request.body) return HttpResponse('ok') else: ### 连接数据库获取主机名列表 return ['c1.com', 'c2.com'] sshsalt发送get请求来获取主机名,返回主机名列表
# python2:
#
# 进程池 有
# 线程池 无
#
# python3:
#
# 进程池 有
# 线程池 有
使用线程池的方式采集数据,因为可以提高效率,比如一次采集10台服务器的数据
先进行测试
s6.py
#### 线程池 import time from concurrent.futures import ThreadPoolExecutor def run(i): time.sleep(2) print(i) p = ThreadPoolExecutor(10) for i in range(100): p.submit(run, i)
client.py
from src.plugins import PluginsManger import json import requests from lib.config.config import settings class Base(): 专门用来进行发送数据采集到的数据 def post_data(self, server_info): requests.post(settings.API_URL, json=server_info) class Agent(Base): 继承base #收集数据并发送 def collectAndPost(self): server_info = PluginsManger().execute() for k,v in server_info.items(): print(k,v) self.post_data(server_info) 调用函数 class SHHSalt(Base): 继承base def get_hostname(self): 发送get请求获取主机名列表 hostname = requests.get(settings.API_URL) return ['c1.com', 'c2.com'] 先自定义进行测试一下 def run(self, hostname): server_info = PluginsManger(hostname).execute() self.post_data(server_info) def collectAndPost(self): hostnames = self.get_hostname() #单线程执行,循环速度比较慢 # for hostname in hostnames: # # server_info = PluginsManger().execute() # self.post_data(server_info) from concurrent.futures import ThreadPoolExecutor p = ThreadPoolExecutor(10) for hostname in hostnames: p.submit(self.run, hostname)
在src新建script.py用于判断mode,再调用不同采集方式的发送数据的方式
script.py
from src.client import Agent from src.client import SHHSalt from lib.config.config import settings def run(): if settings.MODE == 'agent': obj = Agent() else: obj = SHHSalt() obj.collectAndPost()
start.py
from src.script import run if __name__ == '__main__': run()
3.唯一标识码的问题
# 目标:将变更的信息通过程序的比对, 记录下来
#
# 第一天的时候:
#
# 采集数据:
# {'status': 10000, 'data': {'os_platform': 'linux', 'os_version': 'CentOS release 6.6 (Final) Kernel on an \m', 'hostname': 'c2.com'}}
#
# API清洗的时候:
# 因为是第一次, 数据库中并没有采集的数据
#
# 数据入库:
#
# server:1000条
# id sn os_platform os_version disk_size
# 1 dsadsa linux CentOS 250G
# ........
#
# 第二天的时候:
#
# 采集数据:
#
# {'status': 10000, 'data': {'os_platform': 'linux', 'os_version': 'CentOS release 6.6 (Final) Kernel on an \m', 'hostname': 'c2.com'}}
#
# {'status': 10000, 'data': {'0': {'slot': '0', 'pd_type': 'SAS', 'capacity': '300G', 'model': 'SEAGATE ST300MM0006 LS08S0K2B5NV'}, '1': {'slot': '1', 'pd_type': 'SAS', 'capacity': '279.396', 'model': 'SEAGATE ST300MM0006 LS08S0K2B5AH'}, '2': {'slot': '2', 'pd_type': 'SATA', 'capacity': '476.939', 'model': 'S1SZNSAFA01085L Samsung SSD 850 PRO 512GB EXM01B6Q'}, '3': {'slot': '3', 'pd_type': 'SATA', 'capacity': '476.939', 'model': 'S1AXNSAF912433K Samsung SSD 840 PRO Series DXM06B0Q'}, '4': {'slot': '4', 'pd_type': 'SATA', 'capacity': '476.939', 'model': 'S1AXNSAF303909M Samsung SSD 840 PRO Series DXM05B0Q'}, '5': {'slot': '5', 'pd_type': 'SATA', 'capacity': '476.939', 'model': 'S1AXNSAFB00549A Samsung SSD 840 PRO Series DXM06B0Q'}}}
#
# API清洗的时候:
#
# 应该在新的POST数据中选取一个 唯一 的字段, 然后到数据库中作为where条件, 获取到对应的数据
#
# 问题是 应该选取谁?
# 选取的是 sn 序列号(mac地址) 作为唯一的字段
#
# 用sn遇到的问题:
# 虚拟机和实体机共用一个sn, 导致数据不准确
#
# 解决的方案:
#
# a. 如果公司不需要采集虚拟机的信息, 使用sn没有问题
# b. 采用 hostname 作为唯一标识
#
# - 是允许开发可以临时修改主机名的
#
# 引入规则/原则, 流程:
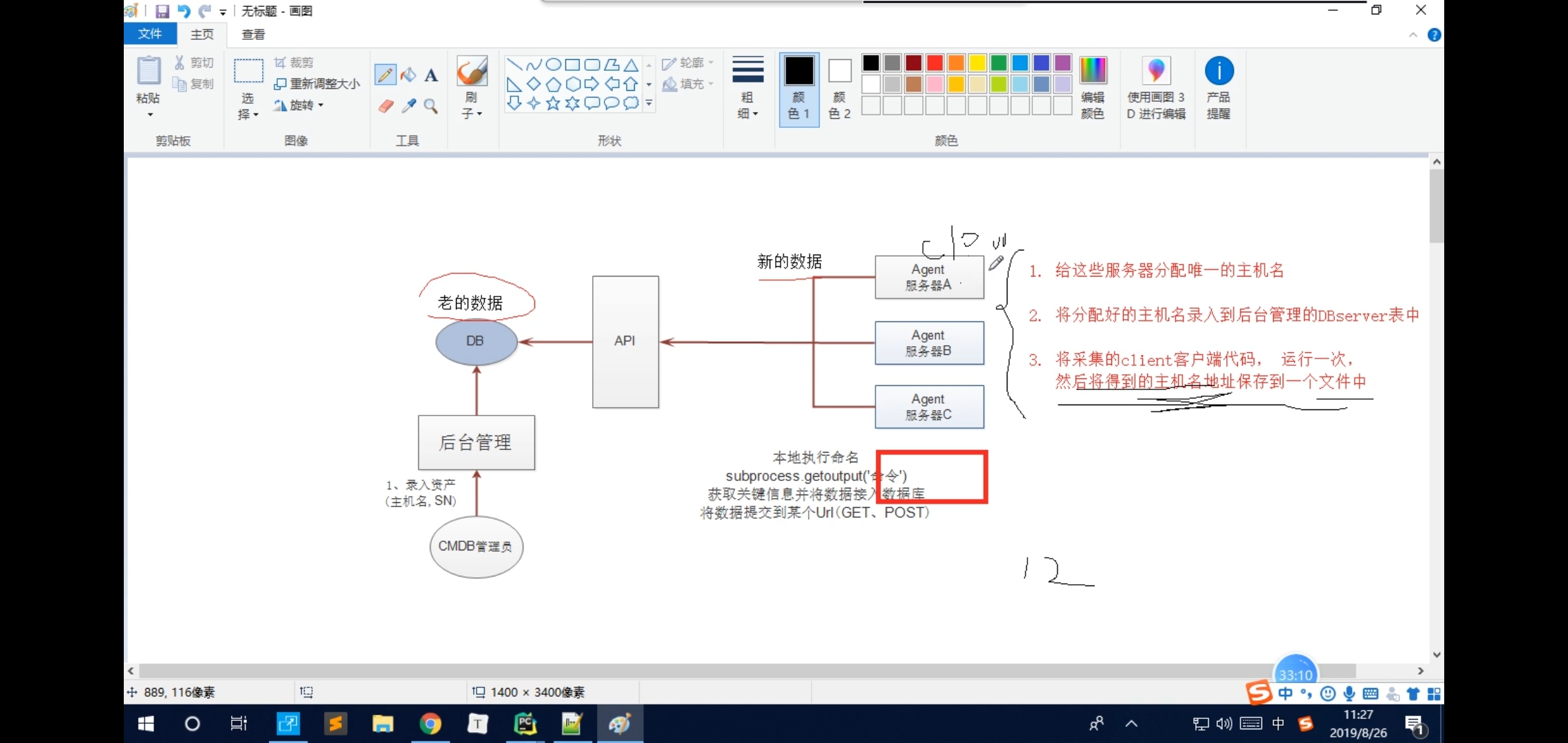
#
# 第一天:
# 1. 给这些服务器分配唯一的主机名
#
# 2. 将分配好的主机名录入到后台管理的DBserver表中
#
# 3. 将采集的client客户端代码, 运行一次,
# 然后将得到的主机名地址保存到一个文件中
#
# 第二天:
#
#
# hostname = server_info['basic']['data']['hostname'] ### c10000.com
# res = open(os.path.join(settings.BASEDIR, 'config/cert'), 'r', encoding='utf-8').read()
#
# if not res.strip():
# #### 第一次采集, 将采集的hostname写入到一个文件中
# with open(os.path.join(settings.BASEDIR, 'config/cert'), 'w', encoding='utf-8') as fp:
# fp.write(hostname)
# else:
# #### 第二次采集的时候, 永远以第一次文件中保存的主机名为标准
# server_info['basic']['data']['hostname'] = res
#
#
client.py 只有agent才用上
from src.plugins import PluginsManger import json import os import requests from lib.config.config import settings class Base(): def post_data(self, server_info): requests.post(settings.API_URL, json=server_info) class Agent(Base): #收集数据并发送 def collectAndPost(self): server_info = PluginsManger().execute() hostname = server_info['basic']['data']['hostname'] res = open(os.path.join(settings.BASEDIR,'conf/cert'), 'r', encoding='utf-8').read() if not res.strip(): # 第一次擦剂,将采集的hostname写入到一个文件中 with open(os.path.join(settings.BASEDIR,'confcert'), 'w', encoding='utf-8')as fp: fp.write(hostname) else: # 第二次采集的时候, 永远以第一次文件中保存的主机名为标准 server_info['basic']['data']['hostname'] = res # for k,v in server_info.items(): # print(k,v) self.post_data(server_info) class SHHSalt(Base): def get_hostname(self): hostname = requests.get(settings.API_URL) return ['c1.com', 'c2.com'] def run(self, hostname): server_info = PluginsManger(hostname).execute() self.post_data(server_info) def collectAndPost(self): hostnames = self.get_hostname() #单线程执行,循环速度比较慢 # for hostname in hostnames: # # server_info = PluginsManger().execute() # self.post_data(server_info) from concurrent.futures import ThreadPoolExecutor p = ThreadPoolExecutor(10) for hostname in hostnames: p.submit(self.run, hostname)
3.API验证
客户端test文件夹中新建测试文件先进行测试
test.py
#原始的方式请求数据 import requests res = requests.get('http://127.0.0.1:8000/getInfo/') print(res.text)
服务端autoserver进行接受,返回数据
views.py
from django.shortcuts import render,HttpResponse # Create your views here. def getInfo(request): if request.method == 'POST': print(request.body) return HttpResponse('ok') else: ### 连接数据库获取主机名列表 # return ['c1.com', 'c2.com'] #如果要返回列表或者字典必须要用jsonresponse发送不然会报错return HttpResponse('非常重要的数据')
客户端发送token
test.py
# 第一种方式 import requests token = "dangerfad" # 切记,进行token验证的时候一定是将token写在http的请求头中 requests.get('http://127.0.0.1:8000/getInfo/', headers={"token":token})
服务端views.py
from django.shortcuts import render,HttpResponse # Create your views here. def getInfo(request): if request.method == 'POST': print(request.body) return HttpResponse('ok') else: ### 连接数据库获取主机名列表 # return ['c1.com', 'c2.com'] print(request.META) #可以获取到HTTP_TOKEN也就是我发过来的token
return HttpResponse('非常重要的数据')
第一种方式完整版
client.py
# 第一种方式 import requests token = "dangerfad" # 切记,进行token验证的时候一定是将token写在http的请求头中 res = requests.get('http://127.0.0.1:8000/getInfo/', headers={"token":token}) print(res.text)
服务端views.py
from django.shortcuts import render,HttpResponse # Create your views here. def getInfo(request): if request.method == 'POST': print(request.body) return HttpResponse('ok') else: ### 连接数据库获取主机名列表 # return ['c1.com', 'c2.com'] token = request.META server_token = "dangerfad" if token != server_token: return HttpResponse("token值是错误的") return HttpResponse('非常重要的数据')
设置超时时间,失效token不能再访问
服务端views.py
from django.shortcuts import render,HttpResponse # Create your views here. def getInfo(request): if request.method == 'POST': print(request.body) return HttpResponse('ok') else: ### 连接数据库获取主机名列表 # return ['c1.com', 'c2.com'] token = request.META.get('HTTP_TOKEN') print(token) client_md5_token,client_time = token.split('|') client_time = float(client_time) import time server_time = time.time() if server_time -client_time > 5: return HttpResponse('第一关【超时了】') server_token = "dangerfad" tmp = "%s|%s" % (server_token, client_time) import hashlib m = hashlib.md5() m.update(bytes(tmp, encoding='utf8')) server_md5_token = m.hexdigest() if server_md5_token !=client_md5_token: return HttpResponse("第二关数据被修改了") return HttpResponse('非常重要的数据')
客户端test.py
#第二种方式 import requests token = "dangerfad" import time client_time = time.time() tmp = "%s|%s"%(token, client_time) import hashlib m = hashlib.md5() m.update(bytes(tmp, encoding='utf8')) res = m.hexdigest() print(res) client_md5_token = '%s|%s' %(res, client_time) data = requests.get('http://127.0.0.1:8000/getInfo/', headers = {"token":client_md5_token}) print(data)
以上还存在一些问题:
client向server在五秒之内发送请求过了一关,紧接着将token发送给服务端,服务端拿到token之后进行解析认证,这是正常用户。
如果说一个黑客,在2s访问完了服务端,然后生成token
,迅速在第3s的时候截取你刚刚访问的token,然后拿到token之后不做任何处理,然后再向服务端发送请求,可以通过验证。
解决:客户端的token只能用一次就好了,在服务端只能让你访问一次token,将客户端的token存起来,如果存在数据库或者文件里面,每天如果频繁去发送的话,这个文件或数据库记录越来越多,然后之前的client_md5_token过期了就没用,所以要存在一个定期清理一些我们不需要的数据的介质里面,存在redis里面(听下回详解)
# 第一次来的时候,先去redis判断client_md5_token是否在redis中,如果在就代表已经访问过了,直接return回去
#如果不在redis第一次访问就添加到redis中并且设置过期时间:5s
总结:
1. 完善了采集端的代码:
- 完善了发送 (agent 和 sshsalt的发送)
class BASE():
def post_data():
requests.post(API_URL)
class Agent(Base):
def collectAndPost():
1. 收集服务器的信息
2. self.post_data()
class SSHSalt(Base):
def collectAndPost():
1. 获取服务器主机名列表,收集服务器的信息
2. self.post_data()
- 改进了sshsalt的登录并发执行:
python2:
线程池 无
进程池 有
python3:
线程池 有
进程池 有
2. 唯一标识的问题:
之前的方法:
sn
改进的方法:
hostname
遵守一些规则:
1. 给这些服务器分配唯一的主机名
2. 将分配好的主机名录入到后台管理的DBserver表中
3. 将采集的client客户端代码, 运行一次,
然后将得到的主机名保存到一个文件中
3. API验证:
第一关:
验证时间是否超时
server_time - client_time > 3
第二关:
对数据由原来的的明文 加密成现在的密文
md5() : 不可逆的算法 sha256 sha128
第三关:
只允许 client_md5_token 只能用一次
redis:
- 速度快
- 设置超时时间 10S
JWT