环境信息
- GitHub 地址
- 选择分支:2.7.8-release
- Dubbo 2.7 官方文档
架构整体设计
基本设计原则
- 采用 Microkernel + Plugin 模式,Microkernel 只负责组装 Plugin,Dubbo 自身的功能也是通过扩展点实现的,也就是 Dubbo 的所有功能点都可被用户自定义扩展所替换。
- 采用 URL 作为配置信息的统一格式,所有扩展点都通过传递 URL 携带配置信息。
Dubbo调用关系说明
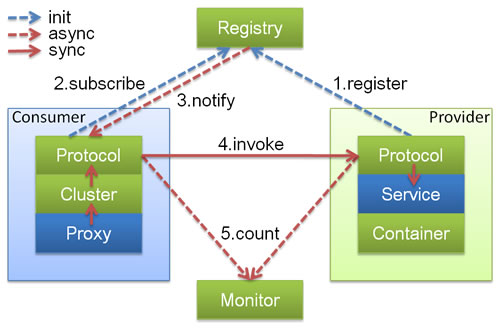
图例说明:
- 图中小方块 Protocol, Cluster, Proxy, Service, Container, Registry, Monitor 代表层或模块,蓝色的表示与业务有交互,绿色的表示只对 Dubbo 内部交互。
- 图中背景方块 Consumer, Provider, Registry, Monitor 代表部署逻辑拓扑节点。
- 图中蓝色虚线为初始化时调用,红色虚线为运行时异步调用,红色实线为运行时同步调用。
- 图中只包含 RPC 的层,不包含 Remoting 的层,Remoting 整体都隐含在 Protocol 中。
整体的调用链路
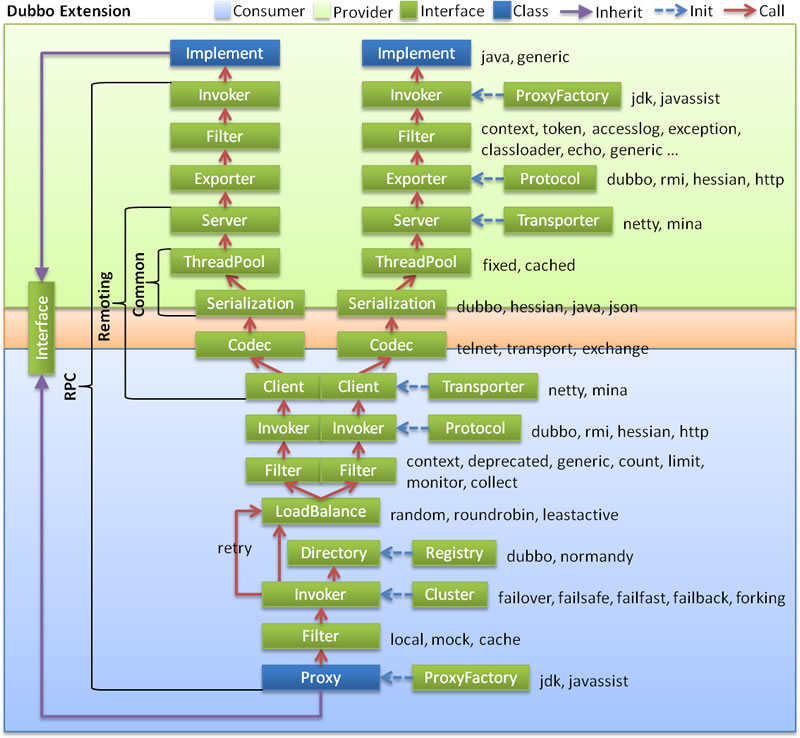
图例说明:
- 淡绿色代表了服务生产者的范围,淡蓝色代表了服务消费者的范围,红色箭头代表了调用的方向,蓝色虚线为初始化时调用
链路调用的流程:
- 消费者通过
Interface进行方法调用,统一交由消费者端的 Proxy(通过ProxyFactory来进行代理对象的创建,使用到了 jdk、javassist 技术) - 交给
Filter这个模块,做一个统一的过滤请求(在 SPI 案例中涉及过) - 接下来会进入最主要的 Invoker 调用逻辑
- 通过
Directory去配置中新读取信息,最终通过 list 方法获取所有的Invoker - 通过
Cluster模块,根据选择的具体路由规则来选取Invoker列表 - 通过
LoadBalance模块,根据负载均衡策略,选择一个具体的Invoker来处理我们的请求 - 如果执行中出现错误,并且 Consumer 阶段配置了重试机制 则会重新尝试执行
- 通过
- 继续经过
Filter,进行执行功能的前后封装,Invoker选择具体的执行协议 - 客户端 进行编码和序列化,然后发送数据
- 到达 Provider 中的
Server,在这里进行 反编码 和 反序列化的接收数据 - 使用
Exporter选择执行器 - 交给
Filter进行一个提供者端的过滤,到达Invoker执行器 - 通过
Invoker调用接口的具体实现,然后返回
Dubbo 源码整体设计
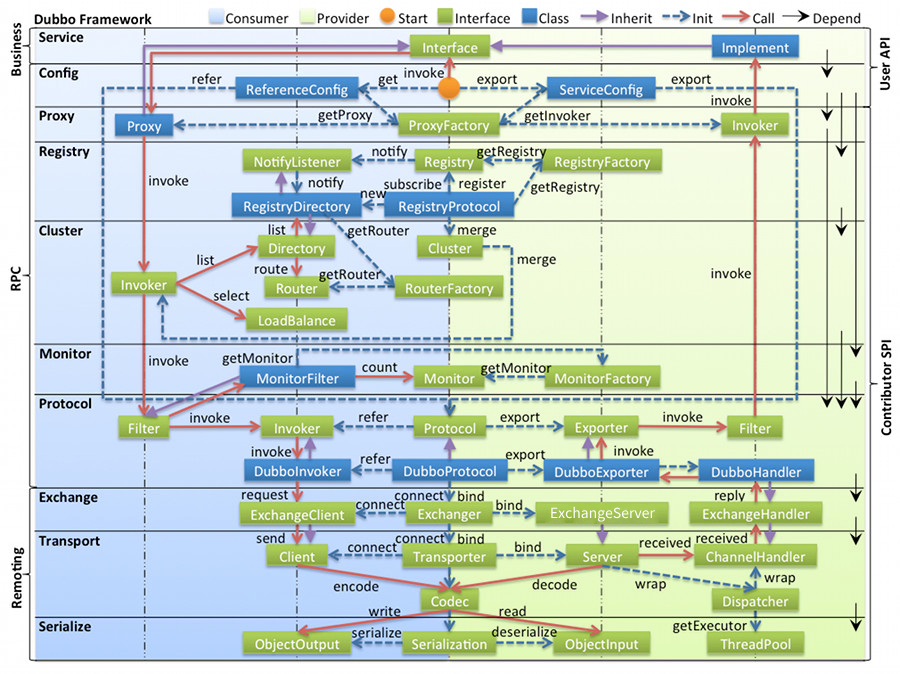
图例说明:
- 图中左边淡蓝背景的为服务消费方使用的接口,右边淡绿色背景的为服务提供方使用的接口,位于中轴线上的为双方都用到的接口。
- 图中从下至上分为十层,各层均为单向依赖,右边的黑色箭头代表层之间的依赖关系,每一层都可以剥离上层被复用,其中,
Service和Config层为 API,其它各层均为 SPI。 - 图中绿色小块的为扩展接口,蓝色小块为实现类,图中只显示用于关联各层的实现类。
- 图中蓝色虚线为初始化过程,即启动时组装链,红色实线为方法调用过程,即运行时调时链,紫色三角箭头为继承,可以把子类看作父类的同一个节点,线上的文字为调用的方法。
各层说明:
- Business:业务逻辑层
- service 业务层:包括我们的业务代码,比如:接口、实现类,直接面向开发者
- RPC:远程过程调用层
- config 配置层:对外配置接口,以
ServiceConfig,ReferenceConfig为中心,可以直接初始化配置类,也可以通过 spring 解析配置生成配置类 - proxy 服务代理层:服务接口透明代理,生成服务的客户端 Stub 和服务器端 Skeleton,以
ServiceProxy为中心,扩展接口为ProxyFactory - registry 注册中心层:封装服务地址的注册与发现,以服务 URL 为中心,扩展接口为
RegistryFactory,Registry,RegistryService - cluster 路由层:封装多个提供者的路由及负载均衡,并桥接注册中心,以
Invoker为中心,扩展接口为Cluster,Directory,Router,LoadBalance - monitor 监控层:RPC 调用次数和调用时间监控,以
Statistics为中心,扩展接口为MonitorFactory,Monitor,MonitorService - protocol 远程调用层:封装 RPC 调用,以
Invocation,Result为中心,扩展接口为Protocol,Invoker,Exporter
- config 配置层:对外配置接口,以
- Remoting:远程数据传输层
- exchange 信息交换层:封装请求响应模式,同步转异步,以
Request,Response为中心,扩展接口为Exchanger,ExchangeChannel,ExchangeClient,ExchangeServer - transport 网络传输层:抽象 mina 和 netty 为统一接口,以
Message为中心,扩展接口为Channel,Transporter,Client,Server,Codec - serialize 数据序列化层:可复用的一些工具,扩展接口为
Serialization,ObjectInput,ObjectOutput,ThreadPool
- exchange 信息交换层:封装请求响应模式,同步转异步,以
领域模型
在 Dubbo 的核心领域模型中:
- Protocol 是服务域,它是 Invoker 暴露和引用的主功能入口,它负责 Invoker 的生命周期管理。
- Invoker 是实体域,它是 Dubbo 的核心模型,其它模型都向它靠扰,或转换成它,它代表一个可执行体,可向它发起 invoke 调用,它有可能是一个本地的实现,也可能是一个远程的实现,也可能一个集群实现。
- Invocation 是会话域,它持有调用过程中的变量,比如方法名,参数等。
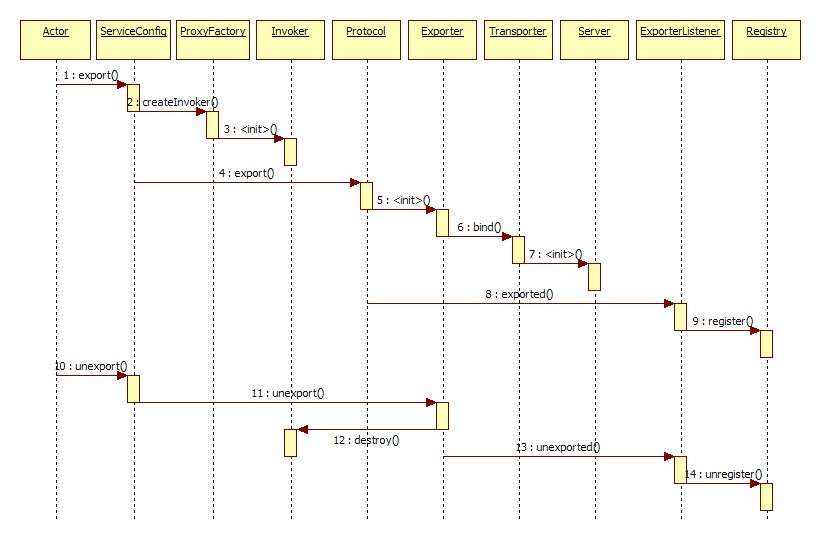
暴露服务时序
展开总设计图左边服务提供方暴露服务的蓝色初始化链,时序图如下:
引用服务时序
展开总设计图右边服务消费方引用服务的蓝色初始化链,时序图如下:
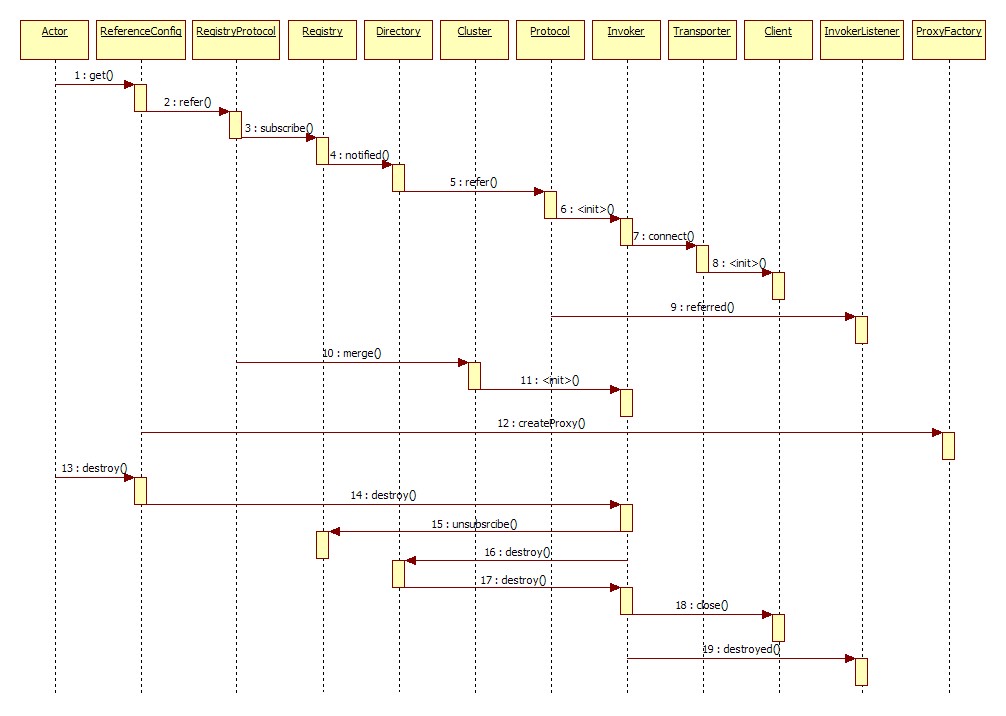
服务注册与消费源码剖析
流程说明:
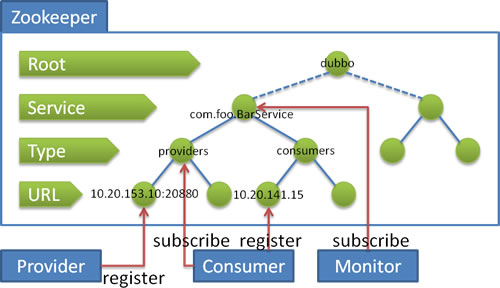
- 服务提供者启动时: 向
/dubbo/com.foo.BarService/providers目录下写入自己的 URL 地址 - 服务消费者启动时: 订阅
/dubbo/com.foo.BarService/providers目录下的提供者 URL 地址。并向/dubbo/com.foo.BarService/consumers目录下写入自己的 URL 地址 - 监控中心启动时: 订阅
/dubbo/com.foo.BarService目录下的所有提供者和消费者 URL 地址。
经过一次 Dubbo 服务调用后,ZooKeeper 内的目录结构如下:
- dubbo
- com.lagou.service.HelloService
- consumers
consumer://192.168.181.1/com.lagou.service.HelloService?application=service-consumer&category=consumers&check=false&dubbo=2.0.2&init=false&interface=com.lagou.service.HelloService&methods=sayHello&pid=11508&release=2.7.5&side=consumer&sticky=false×tamp=1610098210439
- providers
dubbo://192.168.181.1:20885/com.lagou.service.HelloService?anyhost=true&application=service-provider&deprecated=false&dubbo=2.0.2&dynamic=true&generic=false&interface=com.lagou.service.HelloService&methods=sayHello&pid=7948&release=2.7.5&side=provider×tamp=1610098147272
- configuration
- routers
- consumers
- com.lagou.service.HelloService
服务的注册过程分析
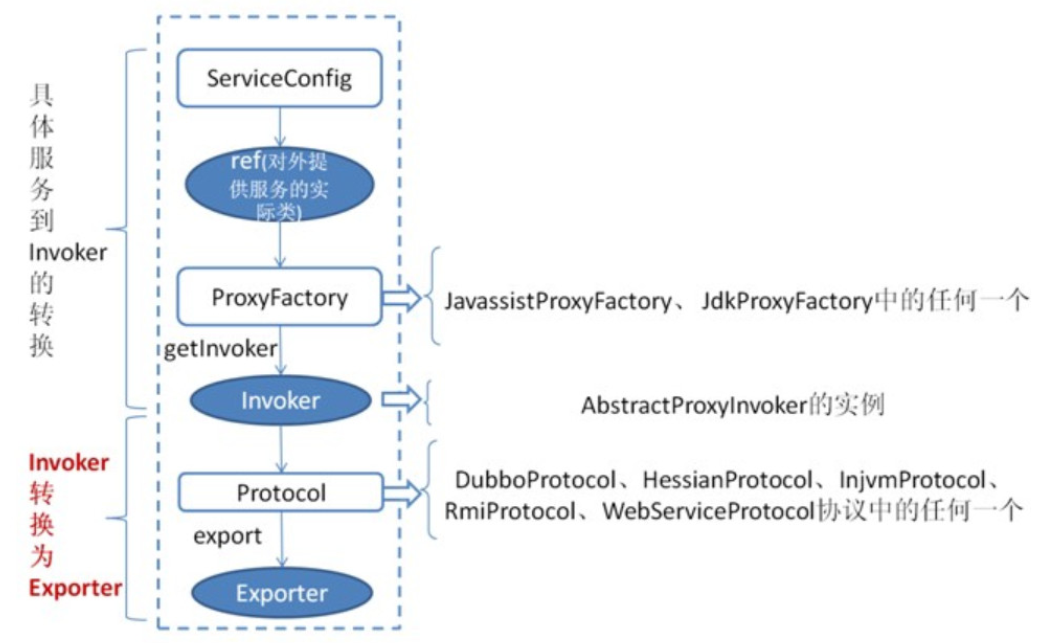
-
org.apache.dubbo.config.spring.context.DubboBootstrapApplicationListener#onContextRefreshedEvent通过 Spring 的监听器机制,监听
ContextRefreshedEvent事件-
org.apache.dubbo.config.bootstrap.DubboBootstrap#start-
org.apache.dubbo.config.ServiceConfig#export-
org.apache.dubbo.registry.integration.RegistryProtocol#export-
org.apache.dubbo.registry.integration.RegistryProtocol#register(关键)-
org.apache.dubbo.registry.zookeeper.ZookeeperRegistry#doRegisterZooKeeper 创建节点
-
org.apache.dubbo.registry.zookeeper.ZookeeperRegistry#toUrlPath将 URL 转为 ZooKeeper 的节点路径
-
-
-
-
-
-
-
分析
org.apache.dubbo.registry.integration.RegistryProtocol#register(关键)-
org.apache.dubbo.registry.support.FailbackRegistry#register异常后失败重试
// Record a failed registration request to a failed list, retry regularly addFailedRegistered(url);
-
URL 规则详解 和 服务本地缓存
URL:
- 所有扩展点参数都包含 URL 参数,URL 作为上下文信息贯穿整个扩展点设计体系。
- URL 采用标准格式:
protocol://username:password@host:port/path?key=value&key=value
注意: Dubbo 中的 URL 与 Java 中的 URL 是有一些区别的,如下:
- 这里提供了针对于参数的 parameter 的增加和减少(支持动态更改)
- 提供缓存功能,对一些基础的数据做缓存
服务本地缓存
- Dubbo 调用者需要通过注册中心(例如: ZK )注册信息,获取提供者,但是如果频繁往从 ZK 获取信息,肯定会存在单点故障问题,所以 Dubbo 提供了将提供者信息缓存在本地的方法。
- Dubbo 在订阅注册中心的回调处理逻辑当中会保存服务提供者信息到本地缓存文件当中(同步 / 异步两种方式),以 URL 维度进行全量保存。
- Dubbo 在服务引用过程中会创建 registry 对象并加载本地缓存文件,会优先订阅注册中心,订阅注册中心失败后会访问本地缓存文件内容获取服务提供信息。
读取缓存文件:
-
org.apache.dubbo.registry.integration.RegistryProtocol#export启动服务时,进行服务注册,注册过程中,获取
Registryfinal Registry registry = getRegistry(originInvoker);-
org.apache.dubbo.registry.support.AbstractRegistry#AbstractRegistry -
初始化
Registry过程中,进行本地保存缓存文件,如果缓存文件已存在,从缓存文件中获取缓存的服务信息存入org.apache.dubbo.registry.support.AbstractRegistry#properties缓存文件默认路径是: String defaultFilename = System.getProperty("user.home") + "/.dubbo/dubbo-registry-" + url.getParameter(APPLICATION_KEY) + "-" + url.getAddress().replaceAll(":", "-") + ".cache";
-
保存缓存文件(默认异步):
-
org.apache.dubbo.registry.support.AbstractRegistry#saveProperties-
org.apache.dubbo.registry.support.AbstractRegistry#doSaveProperties
保存缓存文件,这里使用了原子类型
org.apache.dubbo.registry.support.AbstractRegistry#lastCacheChanged作为版本号,以及文件锁的方式
-
Dubbo 消费过程分析
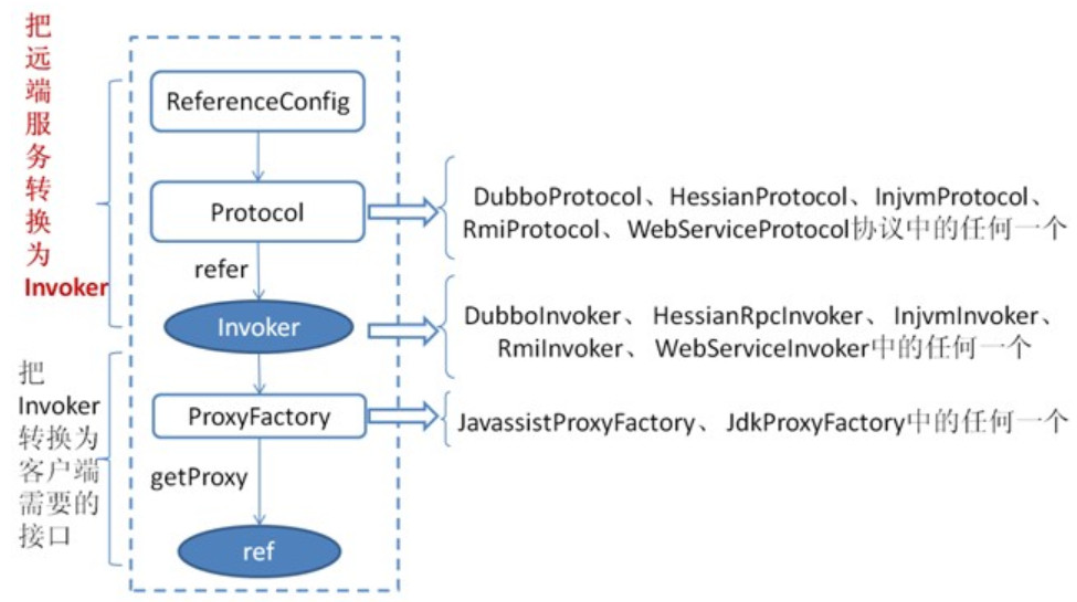
首先 ReferenceConfig 类的 init 方法调用 createProxy() ,期间 使用 Protocol 调用 refer 方法生成 Invoker 实例(如上图中的红色部分),这是服务消费的关键。接下来使用 ProxyFactory 把 Invoker 转换为客户端需要的接口(如: HelloService )。
Dubbo 扩展 SPI 源码剖析
最重要的类就是 org.apache.dubbo.common.extension.ExtensionLoader ,它是所有 Dubbo 中 SPI 的入口。
getExtensionLoader:获取扩展点加载器 并加载所对应的所有的扩展点实现getExtension:根据 name 获取扩展的指定实现getAdaptiveExtension:获取带@Adaptive注解的类createAdaptiveExtensionClass: 通过代码生成的方式生成扩展类
集群容错源码剖析
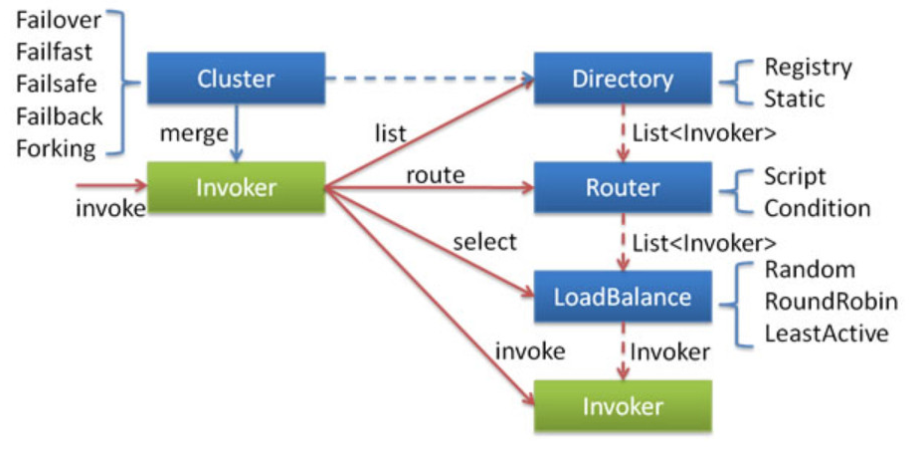
集群工作过程可分为两个阶段,第一个阶段是在服务消费者初始化期间,集群 Cluster 实现类为服务消费者创建 Cluster Invoker 实例,即上图中的 merge 操作。第二个阶段是在服务消费者进行远程调用时。以 FailoverClusterInvoker 为例,该类型 Cluster Invoker 首先会调用 Directory 的 list 方法列举 Invoker 列表(可将 Invoker 简单理解为服务提供者)。 Directory 的用途是保存 Invoker 列表,可简单类比为 List 。其实现类 RegistryDirectory 是一个动态服务目录,可感知注册中心配置的变化,它所持有的 Invoker 列表会随着注册中心内容的变化而变化。每次变化后, RegistryDirectory 会动态增删 Invoker ,并调用 Router 的 route 方法进行路由,过滤掉不符合路由规则的 Invoker 。当 FailoverClusterInvoker 拿到 Directory 返回的 Invoker 列表后,它会通过 LoadBalance 从 Invoker 列表中选择一个 Invoker 。最后 FailoverClusterInvoker 会将参数传给 LoadBalance 选择出的 Invoker 实例的 invoke 方法,进行真正的远程调用。
Dubbo 主要提供了这样几种容错方式:
- Failover Cluster - 失败自动切换 失败时会重试其它服务器
- Failfast Cluster - 快速失败 请求失败后快速返回异常结果 不重试
- Failsafe Cluster - 失败安全 出现异常 直接忽略 会对请求做负载均衡
- Failback Cluster - 失败自动恢复 请求失败后 会自动记录请求到失败队列中
- Forking Cluster - 并行调用多个服务提供者 其中有一个返回 则立即返回结果
信息缓存接口 Directory
Directory 获取所有提供者信息:
-
org.apache.dubbo.rpc.cluster.Directory#list根据本次调用的信息来获取所有可以被执行的提供者信息
-
org.apache.dubbo.registry.integration.RegistryDirectory#doList依靠
routerChain去决定真实返回的提供者列表-
org.apache.dubbo.rpc.cluster.RouterChain#route依次交给所有的路由规则进行选取路由列表
// 依次交给所有的路由规则进行选取路由列表 for (Router router : routers) { finalInvokers = router.route(finalInvokers, url, invocation); }
-
-
路由是获取 Invoker 列表:
-
org.apache.dubbo.registry.integration.RegistryProtocol#refer消费者端生成代理提供者类时调用此方法
-
org.apache.dubbo.registry.integration.RegistryProtocol#doRefer实例化
Directory, 进行监听所有的的 provider ,构建路由链// 构建路由链 directory.buildRouterChain(subscribeUrl);
-
路由规则实现原理
RouterChain 中的 Router 是如何实现的。这里我们主要对 ConditionRouter 的实现来做说明:
两个关键属性:
// 是否满足判断条件
protected Map<String, MatchPair> whenCondition;
// 当满足判断条件时如何选择invokers
protected Map<String, MatchPair> thenCondition;
Router选择Invoker:org.apache.dubbo.rpc.cluster.router.condition.ConditionRouter#route- 生成整个路由规则 :
org.apache.dubbo.rpc.cluster.router.condition.ConditionRouter#init
Cluster 组件
Cluster 它主要用于代理真正的 Invoker 执行时做处理,提供了多种容错方案 ,默认使用 failover 作为实现
-
org.apache.dubbo.rpc.cluster.Cluster#join-
org.apache.dubbo.rpc.cluster.support.wrapper.AbstractCluster#join封装所有拦截器
-
分析默认实现 org.apache.dubbo.rpc.cluster.support.FailoverCluster:
-
org.apache.dubbo.rpc.cluster.support.FailoverCluster#doJoin-
org.apache.dubbo.rpc.cluster.support.AbstractClusterInvoker#invoke获取所有
Invoker,初始化负载均衡器-
org.apache.dubbo.rpc.cluster.support.FailoverClusterInvoker#doInvoke重试指定次数后,如果仍然失败,抛出异常
-
-
负载均衡实现原理
默认使用随机算法
-
org.apache.dubbo.rpc.cluster.LoadBalance#select-
org.apache.dubbo.rpc.cluster.loadbalance.AbstractLoadBalance#select-
org.apache.dubbo.rpc.cluster.loadbalance.RandomLoadBalance#doSelect通过权重指定不同提供者端随机到的概率
-
-
Invoker 执行逻辑
Invoker 就是我们真实执行请求的组件。这里也会衍生出我们真正的 Dubbo 或者 Grpc 等其他协议的请求。
org.apache.dubbo.rpc.Invoker#invokeorg.apache.dubbo.rpc.protocol.AbstractInvoker#invokeorg.apache.dubbo.rpc.protocol.dubbo.DubboInvoker#doInvoke
网络通信原理剖析
数据包结构
Dubbo 协议采用固定长度的消息头(16 字节)和不定长度的消息体来进行数据传输,消息头定义了底层框架(Netty)在 IO 线程处理时需要的信息
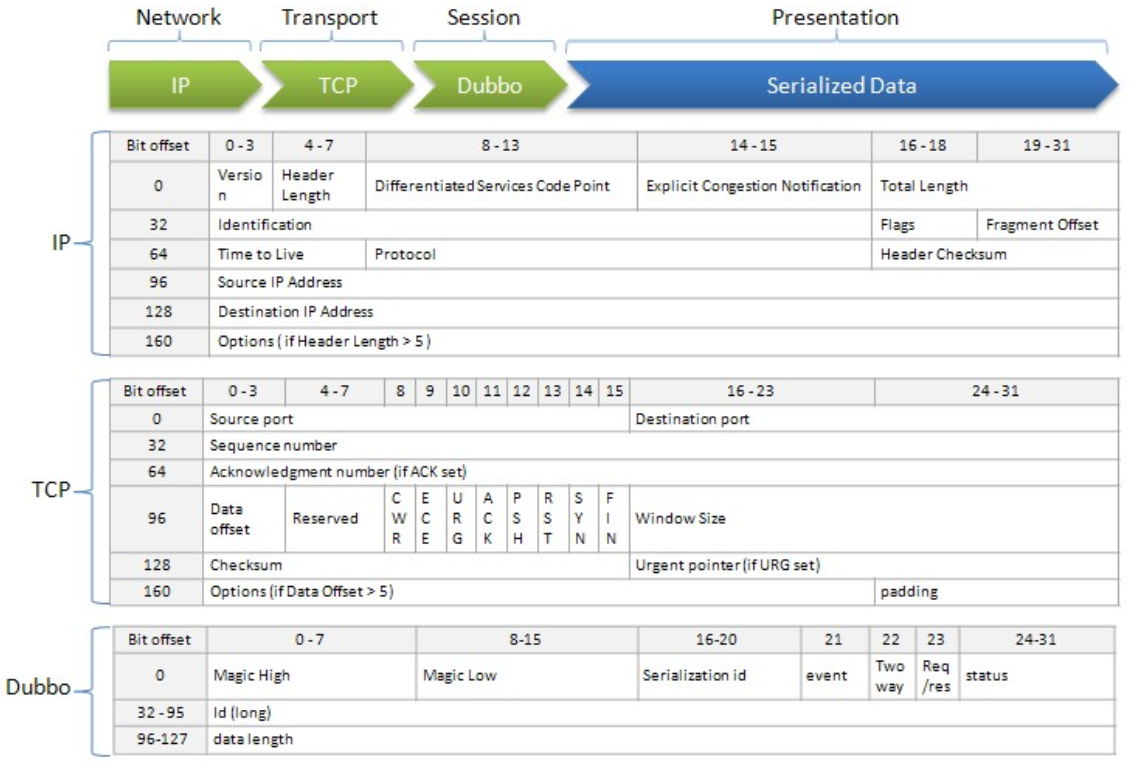
-
Magic - Magic High & Magic Low (16 bits)
标识协议版本号,Dubbo 协议:0xdabb
-
Serialization ID (5 bit)
标识序列化类型:比如 fastjson 的值为 6。
-
Event (1 bit)
标识是否是事件消息,例如,心跳事件。如果这是一个事件,则设置为 1。
-
2 Way (1 bit)
仅在 Req/Res 为 1(请求)时才有用,标记是否期望从服务器返回值。如果需要来自服务器的返回值,则设置为 1。
-
Req/Res (1 bit)
标识是请求或响应。请求: 1; 响应: 0。
-
Status (8 bits)
仅在 Req/Res 为 0(响应)时有用,用于标识响应的状态。
- 20 - OK
- 30 - CLIENT_TIMEOUT
- 31 - SERVER_TIMEOUT
- 40 - BAD_REQUEST
- 50 - BAD_RESPONSE
- 60 - SERVICE_NOT_FOUND
- 70 - SERVICE_ERROR
- 80 - SERVER_ERROR
- 90 - CLIENT_ERROR
- 100 - SERVER_THREADPOOL_EXHAUSTED_ERROR
-
Request ID (64 bits)
标识唯一请求。类型为 long。
-
Data Length (32 bits)
序列化后的内容长度(可变部分),按字节计数。int 类型。
-
Variable Part
被特定的序列化类型(由序列化 ID 标识)序列化后,每个部分都是一个 byte [] 或者 byte
如果是请求包 ( Req/Res = 1),则每个部分依次为:
- Dubbo version
- Service name
- Service version
- Method name
- Method parameter types
- Method arguments
- Attachments
- 如果是响应包(Req/Res = 0),则每个部分依次为:
- 返回值类型(byte),标识从服务器端返回的值类型:
- 返回空值:RESPONSE_NULL_VALUE 2
- 正常响应值: RESPONSE_VALUE 1
- 异常:RESPONSE_WITH_EXCEPTION 0
- 返回值:从服务端返回的响应bytes
注意:对于(Variable Part)变长部分,当前版本的Dubbo 框架使用json序列化时,在每部分内容间额外增加了换行符作为分隔,请在Variable Part的每个part后额外增加换行符, 如:
Dubbo version bytes (换行符)
Service name bytes (换行符)
...
数据协议 ExchangeCodec
编解码相关类:
-
org.apache.dubbo.remoting.Codec2-
org.apache.dubbo.remoting.exchange.codec.ExchangeCodec类中的常量定义对应于数据包结构
org.apache.dubbo.rpc.protocol.dubbo.DubboCodec
-
编解码方法:
org.apache.dubbo.remoting.exchange.codec.ExchangeCodec#encodeorg.apache.dubbo.remoting.exchange.codec.ExchangeCodec#decode
处理粘包和拆包问题
当发生 TCP 粘包的时候 是 TCP 将一个 Dubbo 协议栈放在一个 TCP 包中,那么有可能发生下面几种情况
- 当前 inbound 消息只包含一个 Dubbo 协议栈
- 当前 inbound 消息包含一个 Dubbo 协议栈,同时包含部分另一个或者多个 Dubbo 协议栈内容
如果发生只包含一个协议栈,那么当前 buffer 通过 ExchangeCodec 解析协议之后,当前的 buffer 的 readeIndex 位置应该是 buffer 尾部,那么在返回到 InternalDecoder 中 message 的方法 readable 返回的是 false ,那么就会对 buffer 重新赋予 EMPTY_BUFFER 实体;
而针对包含一个以上的 Dubbo 协议栈,当然也会解析出其中一个 Dubbo 协议栈,但是经过 ExchangeCodec 解析之后, message 的 readIndex 不在 message 尾部,所以 message 的 readable 方法返回的是 true 。那么则会继续遍历 message ,读取下面的信息。最终要么 message 刚好整数倍包含完整的 Dubbo 协议栈,要不 ExchangeCodec 返回 NEED_MORE_INPUT ,最后将未读完的数据缓存到 buffer 中,等待下次 inbound 事件,将 buffer 中的消息合并到下次的 inbound 消息中,问题种类又回到了拆包上。
Dubbo 在处理 TCP 的粘包和拆包时是借助 InternalDecoder 的 buffer 缓存对象来缓存不完整的 Dubbo 协议栈数据,等待下次 inbound 事件,合并进去。所以说在 Dubbo 中解决 TCP 拆包和粘包的时候是通过 buffer 变量来解决的。
org.apache.dubbo.remoting.transport.netty4.NettyCodecAdapter.InternalDecoder#decodeorg.apache.dubbo.rpc.protocol.dubbo.DubboCountCodec#decodeorg.apache.dubbo.remoting.exchange.codec.ExchangeCodec#decode