mysql我们经常使用,但是我们对其中的知识也要了解和熟悉,我们需要做一下必要的总结,方便自己和同学们一起学习。接下来我们一起来看看平时我们需要了解和掌握的知识有哪些。
1. myisam和innodb的区别?
2. mysql的几种事务隔离级别。
3. 什么是聚簇索引和非聚簇索引。
4. 什么是覆盖索引、回表。
5. ACID是如何保证的。
6. 主从是如何同步的,有什么缺点?
1. myisam和innodb的区别。
myisam是之前mysql的默认引擎,主要用于读大于写的时候使用,数据存放在内存中,这样读的速度非常快,但是当数据库重启之后数据将需要重新加载到内存中。这个引擎从5.1之前都是默认的引擎。但是它不支持事务、行锁、外键,这些都是它的缺点。
innodb的产生就是为了解决它的缺点。innodb支持事务、行锁、外键。现在非常流行的就是这个数据库引擎。通过MVCC实现高并发访问。
2.mysql的几种事务隔离级别。
mysql支持未提交读,已提交读,可重复读,串行Serializable。mysql默认隔离级别为可重复读,oracle的默认隔离级别为已提交读。
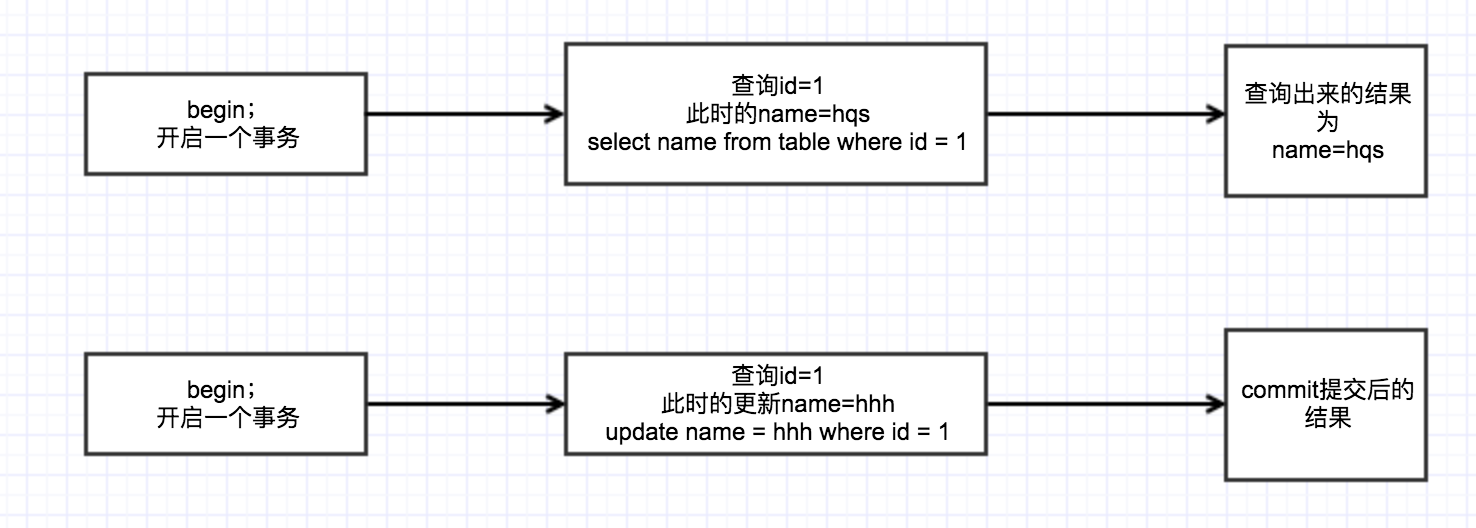
未提交读(Read Uncommitted) :即事务还没有提交的时候别的事务可以查看到数据,也成为脏读。举个例子,
事务A,查询id=1的name,此时name为hqs。
事务B,更新id=1的name为hhh。我们将看到如下的结果:
已提交读(Read Committed), 当事务提交的了之后,另外一个事务才能看到。不会出现上边的问题,即不会出现脏读,但是在这个过程中会出现不可重复读,接下来我们继续看,基本上还是刚才的例子。
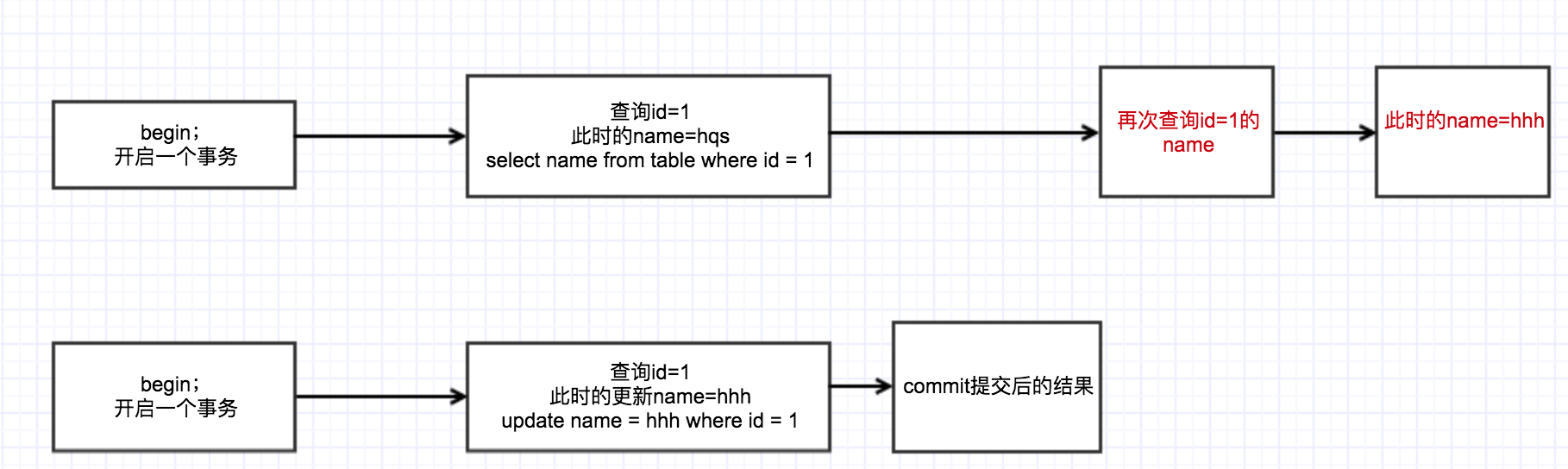
可重复读(Read Repeatable):每次可以正确的读取数据的结果,但是会出现幻读,接下来我们看看这种情况。

说道可重复读,我们需要了解一下他是如何实现的。它采用MVCC(Multi Version Concurency Control), 多版本并发控制,类似于数据库的乐观锁,通过版本号来控制该读哪个版本号的数据,实现对数据的高并发访问。
首先我们需要知道什么是undolog,redolog,binlog。
undolog,即未做日志,也就是加入数据库里边有一条id=1 and name='hqs'的数据,那么我修改了这个数据的name='hhh',当事务提交了之后,会有一条undolog,这个时候执行的语句就是update table set name='hqs' where id=1,即还原之前的数据。相应的如果有一条insert语句会有一条对应的delete语句,当事务出现了问题之后需要回滚到上一个版本上。这个也是mvcc的关键。
redolog,数据库的操作过程是非常快速的,一般执行数据库操作的时候需要将数据先写入到缓存,即write ahead log,比如写入数据会有一条insert语句,更新会有一条update语句等,这个时候需要先写到缓存中,然后当执行成功后会刷到磁盘上。这个时候实现了快速的处理和写入。写入缓存的时候为parepare,写完之后即变为commit,这也就是两阶段提交时进行的数据处理,当commit之后然后就可以flush到磁盘上。
binlog,即所有引擎日志,数据有了之后就有这个日志,记录了server的操作日志。用于主从复制,数据恢复时使用,这个需要定时保存。
数据库在执行了事务之后,每条记录除了数据之外,还有几个关键字段db_trx_id, db_roll_ptr。
db_trx_id,即执行事务的id。
db_roll_ptr,事务回滚的指针,用于指向undolog的记录,当事务执行失败之后需要需要回滚到之前的版本号。
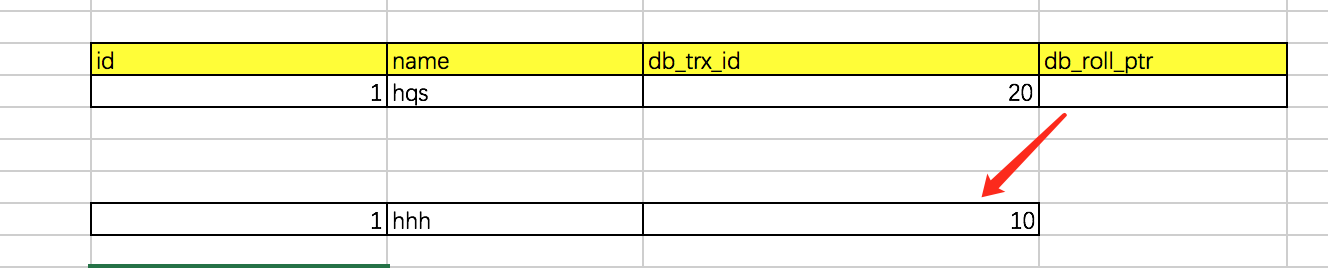
MVCC就是采用事务版本号进行读取的,当commit之后,我们知道最后一个事务成功的版本号,然后根据这个版本号产生一个读视图(read view),通过读视图读取数据时,这个时候就能正确的读取数据。
那我们知道了可重复读的隔离情况下,如何解决幻读呢?
假如我们数据库里边有这几条数据。

这个时候我们执行下边的两条事务,第一条语句执行的时候加了行锁,然后第二条语句开始进行写入。
begin; select * from table where age = 20 for update; begin; insert into table (name, age) values (h4, 10); #成功 insert into table (name, age) values (h5, 20); #失败 insert into table (name, age) values (h6, 25); #失败 insert into table (name, age) values (h7, 30); #失败
这个时候就出现了Gap Lock,这个是可重复读隔离级别独有的。通过这种方式可以获取“当前读”,即当前最新的数据,避免产生幻读。行锁+间隙所解决幻读的问题。
关于间隙锁,我们接下来继续认识一下。以上数据产生的间隙锁如下(左包含右边不包含):
(负无穷, 10], (10 20], (20, 30], (30, 正无穷)
因为数据里边有age=20的记录,所以(10, 20]会锁定,这些记录段的数据不能进行更新操作。所以10成功了,20失败了之后,后边的就全部失败了,因为有失败了之后进行了数据的回滚。
如果索引是唯一索引的话不存在间隙锁。
基于上边的总结,我整理出一个表格可以更清晰的认识这个事务的级别。

3. 什么是聚簇索引和非聚簇索引。
每个表都有一个唯一主键,唯一主键形成的索引树就是聚簇索引,采用B+树进行的数据存储。每个节点存储这个数据的索引id,一层一层的按范围分的,越往上越范围越大,越往下范围越小。叶子节点存储的真实的数据,真实的数据是id从小到大的数据进行分布的,数据采用双向链表用于数据的快速查找。如下图所示: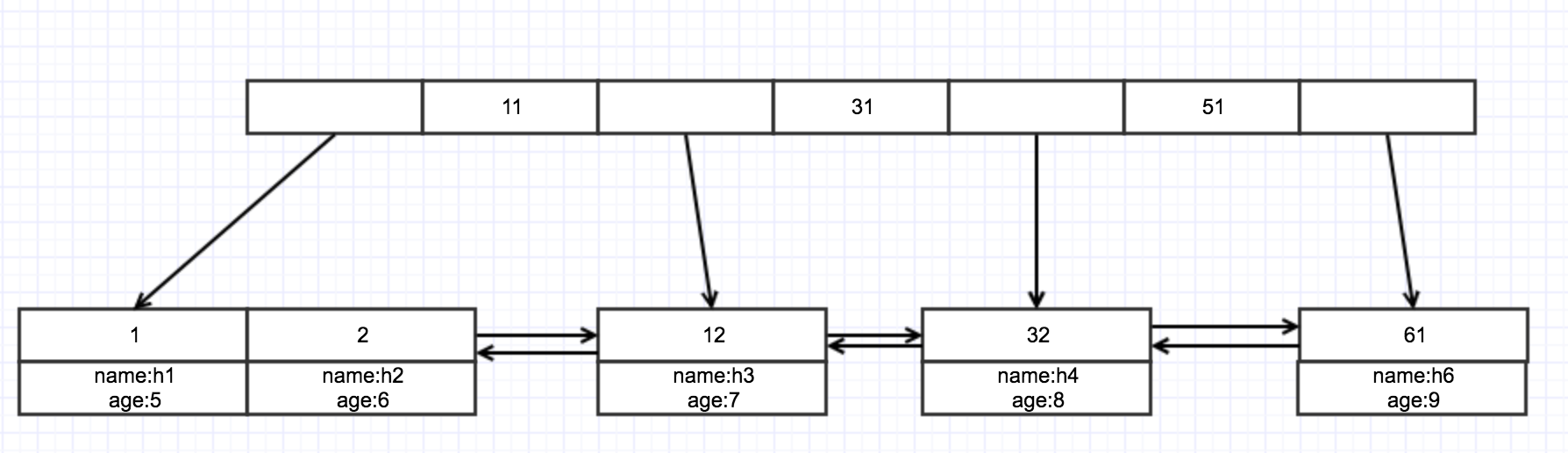
非聚簇索引也称为非主索引,加入以name+age为索引的话,那么效果就是这样的,根据索引字段生成一个索引id,然后索引id和主键形成一个映射。然后再根据主键进行数据的查询。效果如下:

4. 什么是覆盖索引、回表。
覆盖索引理解起来比较简单,即执行explain的时候的时候提示“using index”,即使用了覆盖索引。
比如有一个table,有表A、B、C字段,假如有index( A,B,C) 那么,我们查询顺序A, AB, ABC的时候,都是采用覆盖索引。
当我们使用字段B,C的时候,那么没有走到数据库的索引,这个时候需要先查询到索引对应的主键id,然后再进行二次查询,这个就是回表。
5. ACID是如何保证的。
A原子性,通过undolog保证,当事务执行失败的时候,通过unlog将数据还原来保证事务的一致性。
C一致性,当两个事务提交后,最终能保证数据的结果是一致的。
I隔离性,通过MVCC来保证。
D持久性,通过内存+redolog,数据一般会刷到内存,然后事务提交之后再刷到磁盘上。当数据有问题的时候通过redolog来进行数据恢复。
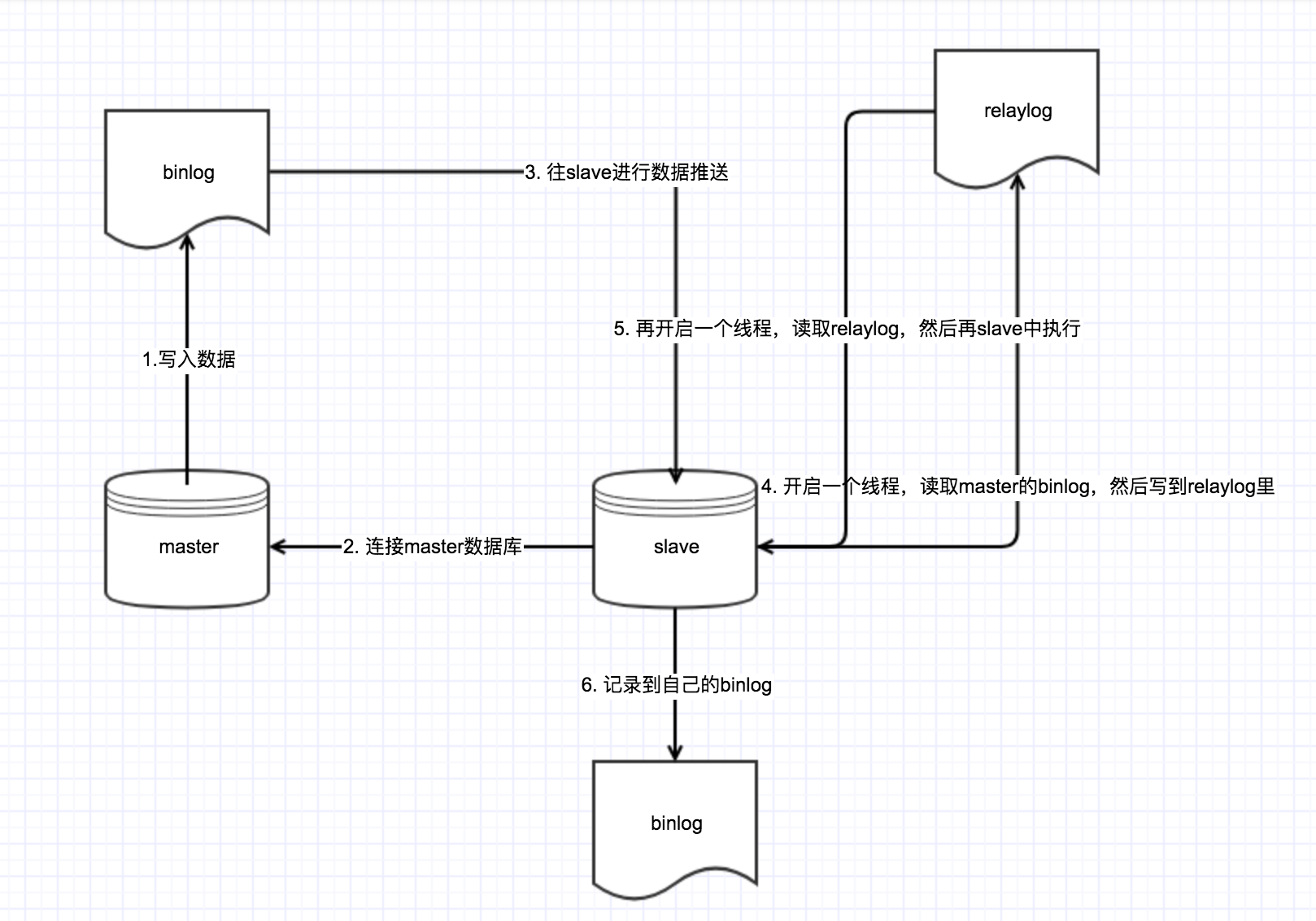
6. 主从是如何同步的,有什么缺点?
主从同步,分为几个步骤:
1. master写入binlog。
2. slave连接到master,并且记录好binlog的id.
3. master的binlog进行slave日志同步。
4. slave开启一个线程,读取binlog的日志,然后写到中继日中relaylog中。
5. slave在开启一个线程,从relaylog读取日志之后写到slave数据库看。
6. slave会记录到自己的数据库中。
如下图所示:
由于默认mysql同步日志是采用异步的,所以主库写入不写入从库,主库不关心,这个时候从库出现了问题的话,主库无感知。如果主库失败了,那么从库读取失败的话,从库升级为主库,日志就丢失了。这个时候就会出现两种情况:
全同步复制:
全同步就是当主库往从库写数据采用的同步处理,这个时候主库写完binlog,然后等待从库处理完成,这样会影响效率。
半同步复制:
半同步是在数据发给从库后,从库处理完之后会发一个ACK给主库,这样主库就知道了,然后确认传输完成。
当然,我们除了数据库的解决数据丢失问题,我们还需要程序来保证额外的数据冗余处理,比如将传输的数据发送到MQ或KAFKA,其他系统可以从这个里边去读取,然后进行下一步处理。保证数据的安全可靠。