首先需要弄清楚中断上下文切换和进程上下文切换之间的区别:
中断上下文切换发生在中断产生和中断返回时,由cpu硬件和中断处理程序入口的汇编代码结合起来完成中断上下文的切换。它是由一个进程的用户态进入其内核态,或者由内核态退出到用户态。
进程上下文的切换发生在进程调度过程中,是完全由内核代码来实现,没有硬件参与,是由一个进程切换到另一个进程,但一般进程上下文切换时嵌套到中断上下文切换中的。进程上下文的切换包括:从一个进程的地址空间切换到另一个进程的地址空间,从一个进程的内核堆栈切换到另一个进程的内核堆栈,还有诸如eip等寄存器状态的切换。
一. 以fork和execve系统调用为例分析中断上下文的切换:
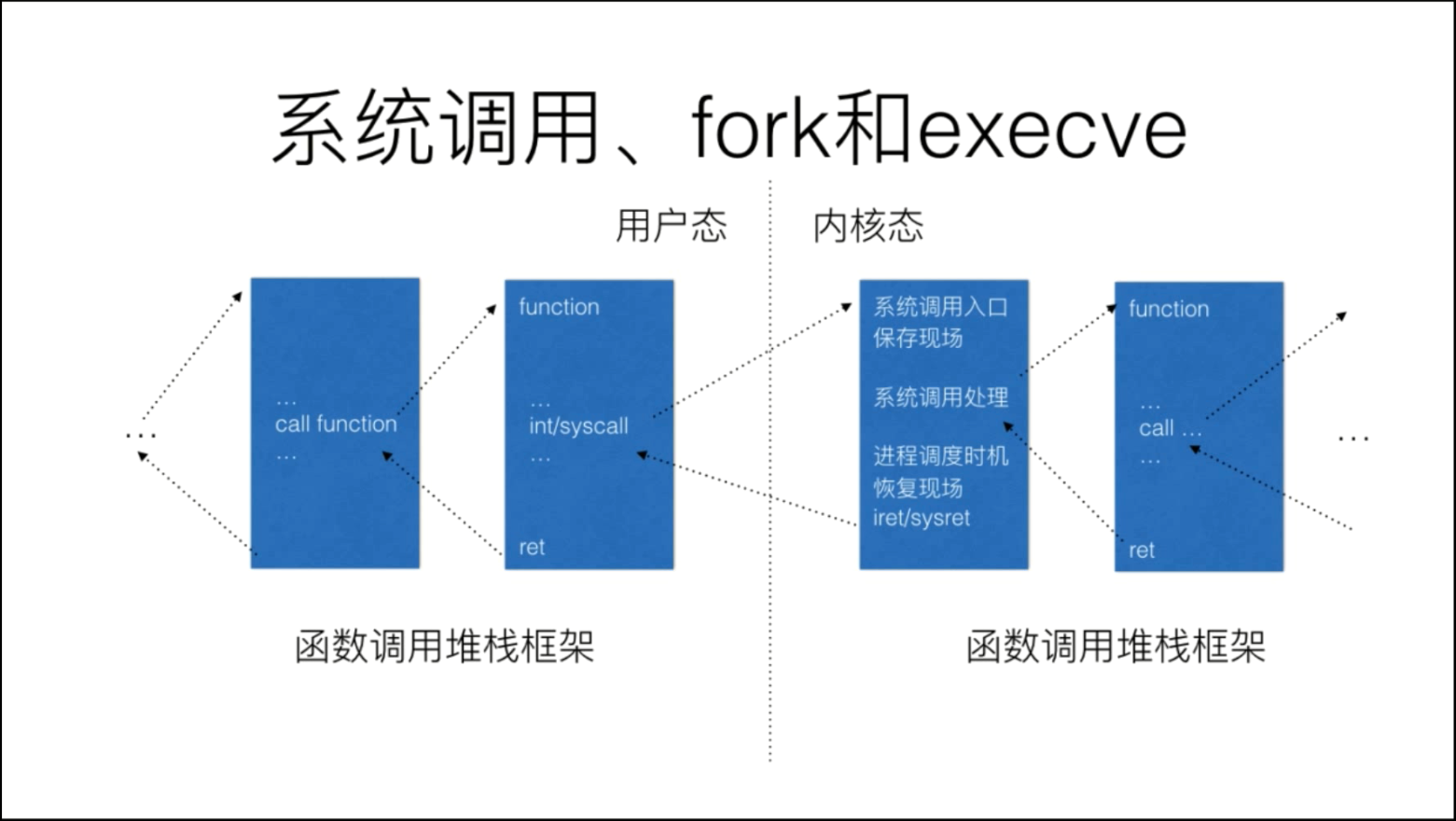
1. 一般的系统调用:
涉及到2个堆栈:用户态堆栈和内核态堆栈。
用户态进入内核态的中断上下文切换包括3部分:cpu硬件保存的寄存器状态+系统调用号+SAVE_ALL保存的寄存器,组成pt_regs数据结构。
内核态退出到用户态的中断上下文切换包括2部分:restore_all(还原SAVE_ALL保存的寄存器)+iret(还原cpu硬件保存的寄存器)。
2. fork系统调用:
struct task_struct init_task为0号进程,它是内核代码写死的,除此之外,所有其他进程的初始化都是通过_do_fork复制父进程的方式初始化的。1号进程kernel_init和2号进程kthreadd都是在start_kernel最后由rest_init()函数通过调用kernel_thread()函数创建的,而kernel_thread最终是调用_do_fork函数。用户态程序通过fork系统调用创建一个进程最终也是通过_do_fork来完成的。
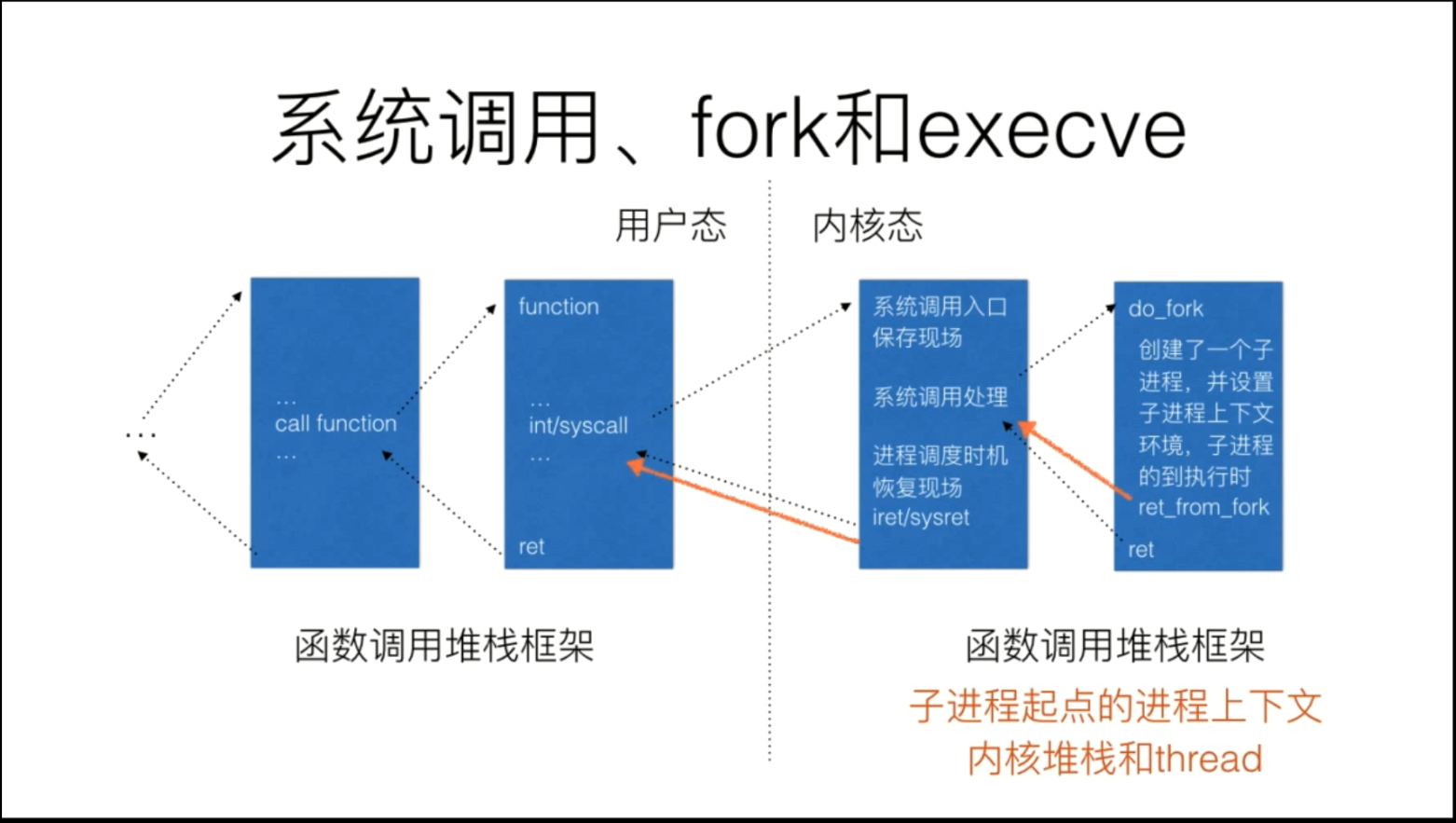
图中黄色的线就是fork后子进程的代码执行路径,从ret_from_fork开始执行,最后中断返回到用户态开始执行用户态代码。
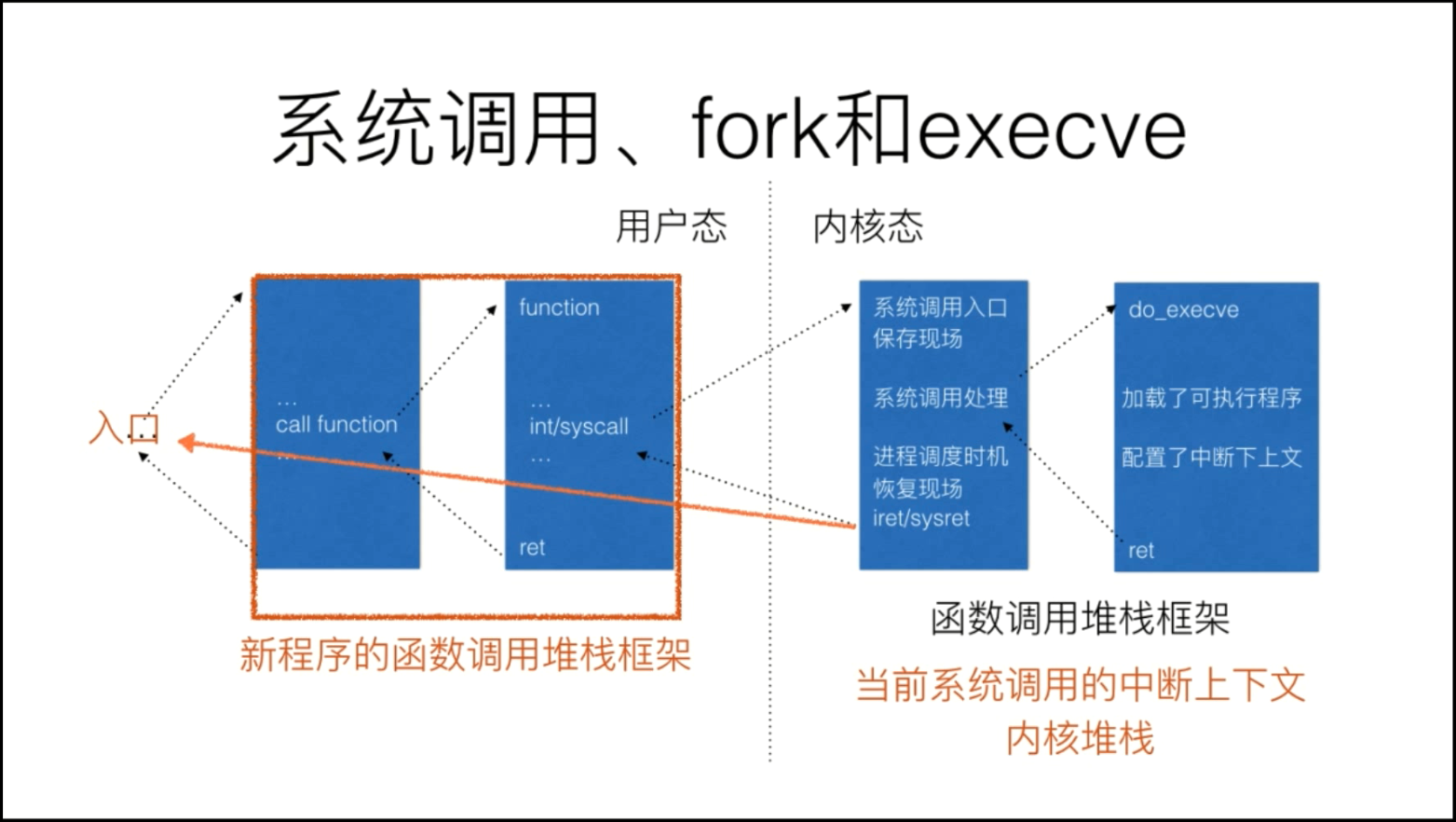
3. execve系统调用:
当execve系统调用返回到用户态时已经不是原来的那个可执行程序了,颇有点狸猫换太子的意思。
二. 分析fork 子进程启动执行时 进程上下文的特殊之处:
我们知道一般的系统调用执行完之后就从内核态切换到用户态,并从系统调用的下一条指令开始执行,只有这一个返回。而fork系统调用的特殊之处是它在内核里面变成了父子2个进程,有2个返回,父进程执行完fork系统调用要返回到用户态,而fork出来的子进程也要从内核里返回到用户态,那子进程从哪行代码开始执行呢?
首先抽象的看下_do_fork函数干了什么事:


copy_thread_tls()函数用于初始化子进程的内核栈,下面我们就来看看子进程的内核栈有什么特殊之处:
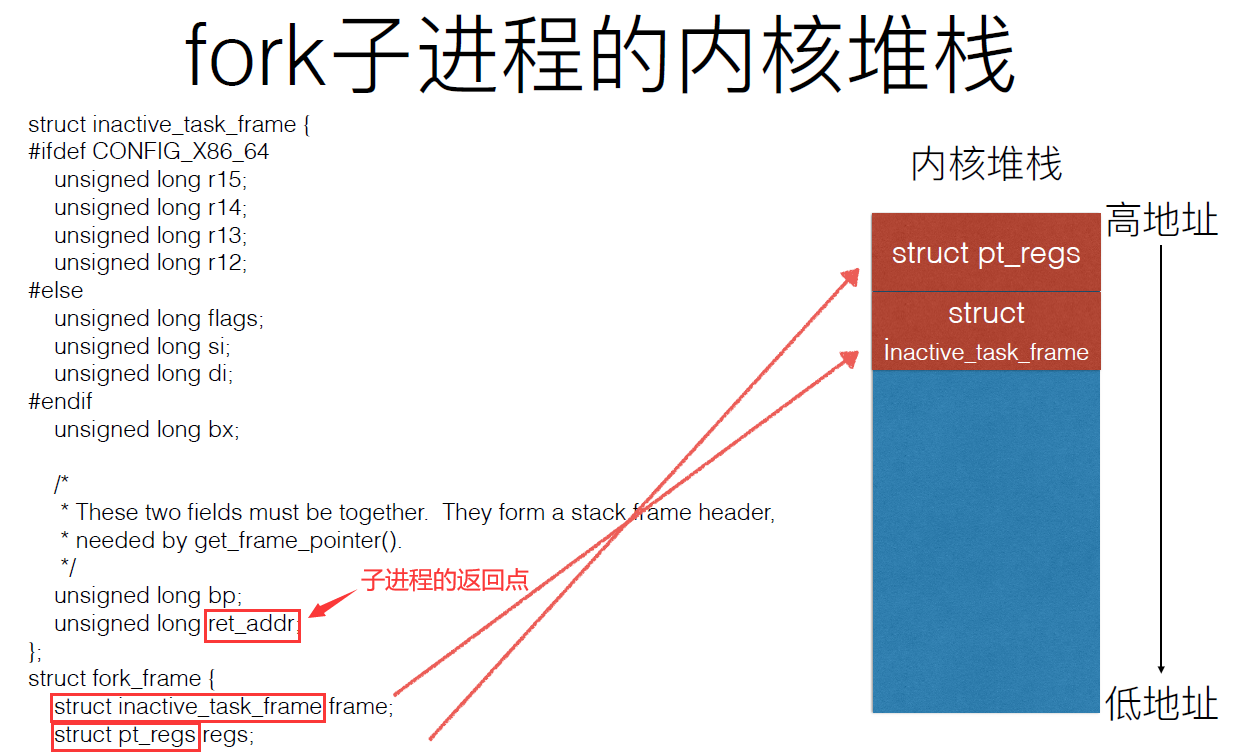
从struct fork_frame中可以看出子进程的内核栈是在struct pt_regs的基础上增加了struct inactive_task_frame,而struct inactive_task_frame结构体中的变量ret_addr就是子进程的返回点。在前面我们了解到copy_thread_tls()函数用于初始化子进程的内核栈,而结构体变量frame就是在那里初始化的:

子进程创建好了之后就通过wake_up_new_task(p)添加到运行队列,等待调度执行,子进程的执行就从这里设定的ret_from_fork开始,父进程返回到用户态后就从fork系统调用的下一条语句开始执行。
三. 分析execve系统调用中断上下文的特殊之处:
execve系统调用相比于一般的系统调用特殊之处在于:当前的可执行程序在执行到execve系统调用时陷入内核态,在内核中利用do_execve函数加载可执行文件,把当前进程的可执行程序给覆盖掉,所以当execve系统调用返回时,返回的已经不是原来的那个可执行程序了,而是新的可执行程序。execve系统调用返回的是新的可执行程序的起点:main函数,静态链接的可执行文件在main函数大致位置处,动态链接的可执行文件还需要ld链接好动态链接库再从main函数开始执行。
linux系统提供了6个用于加载执行一个可执行文件的库函数:execl,execlp,execle,execv,execvp和execve。这些函数统称为exec系列库函数,它们的差异在于命令行参数和环境变量参数的传递方式不同,但都是通过execve系统调用进入内核,对应的系统调用内核处理函数为sys_execve或__x86_sys_execve,然后通过调用do_execve函数来执行具体的可执行文件的加载工作。

而start_thread()函数修改了内核堆栈的底部,即中断关键上下文的cpu状态信息,使得execve系统调用返回到用户态时能够从新的程序入口开始执行。
四. 下面从逻辑上完整走一遍中断处理过程(结合中断上下文的切换,以定时器中断为例,假设从用户态进入中断):
1. 定时器连接在8259A可编程中断控制器(PIC,Programmable Interrupt Controller)的0号IRQ线上,0号IRQ线对应32+0=32号中断向量。中断控制器又与CPU的INTR引脚相连。当定时器产生中断时,中断控制器把对应的中断向量32放到一个I/O端口上,从而允许CPU通过数据总线读到这个向量。然后PIC就向CPU的中断引脚发送一个低电平,即产生一个中断。CPU对这个信号做应答,PIC收到应答后,清INTR引脚。
2. 硬件保存现场:SS、SP、eflags、cs、eip,保存到被中断进程的内核堆栈中(tr寄存器保存当前进程的tss段,而tss段里有最后一次访问内核栈的指针)。
3. 读idtr寄存器指向的中断描述符表(idt)的第30项,得到相应的中段描述符,并用中断描述符里的段选择符(还要根据gdtr寄存器指向的全局描述符表gdt获取段选择符对应的段描述符)和偏移量装载CPU的cs和eip寄存器。这样就进入到了中断处理程序的入口,CPU开始执行中断处理程序入口的代码ENTRY(interrupt)。
4. 而在系统初始化时,通过调用init_IRQ()函数用interrupt数组的每一项来初始化idt表,而interrupt数组的每一项都是一样的内容,都是interrupt。所以无论发生哪一种中断,都会跳转到一段汇编代码ENTRY(interrupt)处,这就是每一个中断处理程序的入口。它首先在内核栈上push中断向量号,然后跳转到common_interrupt处。

5. common_interrupt首先使用SAVE_ALL继续保存现场(按照pt_regs数据结构保存),然后无论哪一个中断都会调用do_IRQ函数,这个函数就一个参数即指向pt_regs数据结构的指针,使用%eax寄存器传递。
6. do_IRQ函数使用全局数组irq_desc,irq_desc既是数组名也是数组中每个元素的数据类型。每个中断号对应一个irq_desc,irq_desc里包含irqaction链表,我们将每个设备对应的中断服务例程打包成irqaction,并通过setup_irq函数将其加入相应的irqaction链表中。handle_IRQ_event()函数负责扫描action链表,依次把action都执行一遍。

7. 跳转到ret_from_intr。
所以在外部看来就是:定时器发生中断了,定时器中断服务例程执行。
五. 结合中断上下文切换和进程上下文切换分析Linux系统的一般执行过程,以期对Linux系统的整体运作形成一套逻辑自洽的模型,并能将所学的各种OS和Linux内核知识/原理融通进模型中:
Linux系统在运行过程中一个最基本也是最一般的场景就是:正在运行的用户态进程X切换到用户态进程Y,具体过程描述如下:(假设用户态进程Y也是在中断处理过程中或中断返回前调用了schedule函数被切换了出去,(为什么会在这个时间点发生进程调度呢?我的理解是此时中断处理过程已经全部结束,内核栈就只剩下一个pt_regs结构,而这个pt_regs结构就是用户态进程被中断时的各种寄存器状态,如果不发生进程切换,直接将pt_regs结构出栈就可以恢复执行被中断的进程,而此时发生进程切换,就省去了保存现场的操作,这个pt_regs结构就是现场,这里用到的一个tricky就是中断和进程切换要保存和恢复的现场都是一样的,都是pt_regs结构,在中断返回时进行进程切换就省去了一次保存现场和恢复现场,直接利用中断保存的现场来做进程切换,否则若是在中断返回后直接在用户态进行进程切换,就还要再保存和恢复一次现场,这样设计可以提高效率。)那进程Y在被调度回来以后接着schedule函数执行,这个时候的中断处理函数只剩了schedule函数里的一点代码和恢复现场,接着执行就会中断返回到Y的用户态接着被中断的地方执行。)
思考:只有内核调用schedule函数才能发生进程切换,所以只要进程永远在用户态执行不进入内核态就会一直占有cpu不会被切换出去,但这显然是不可能的,先不说随时都可能产生的其他的外部中断,定时器就会周期性的产生中断,给进程调度创造时机。所以一个进程不可能不被调度,除非它要做的东西非常少,在定时器产生中断的时间间隔内就执行完了(好像几乎不可能)。
注意:进程调度发生了进程切换一定是内核调用了schedule函数!而且切换出去和切换回来时都是在执行schedule函数。切换回来时从schedule函数里的$1f处开始执行。
1. 用户态进程X正在运行。
2. 发生中断(包括硬件中断,异常和系统调用),此时硬件完成以下动作:
- 首先找到被中断进程的内核栈,加载内核栈的ss:esp到cpu的ss和esp寄存器。
- 将当前cpu的上下文(ss:esp(用户态堆栈)/eflags/cs:eip)压入被中断进程X的内核堆栈。
- 根据idt表和gdt表的表项装载cs和eip寄存器,使其跳转到中断处理程序的起点。
3. SAVE_ALL,继续按pt_regs数据结构保存现场。此时就完成了中断上下文的切换,即从进程X的用户态切换到了进程X的内核态。
4. 在中断处理过程中或中断返回前调用了schedule函数,其中的switch_to做了关键的进程上下文的切换。将当前用户进程X的内核栈切换到用户进程Y的内核栈,并完成eip等寄存器状态的切换。
所以进程切换走和切换回来的时间点都是在执行schedule函数,而用户进程Y也是在中断处理过程中或中断返回前调用了schedule函数被切换了出去,所以被调度回来仍从schedule函数里的$1f位置处接着执行。$1f位置处执行完 popl %ebp; popfl; 这2行汇编代码后switch_to函数就执行完了,接着依次返回到context_switch函数,再返回到schedule()函数。

5. schedule()函数执行完以后,使用restore_all恢复现场。注意此时运行的是用户进程Y调用schedule函数的那个中断的代码。
6. 接着执行iret,硬件恢复现场,从Y进程的内核堆栈中弹出2中硬件完成的压栈内容,此时完成了中断上下文的切换,即从进程Y的内核态返回到进程Y的用户态。
7. 继续运行用户态进程Y。